
图表总结预训练BERT系列模型

算法工程师
预训练语言模型Bert至问世以来,各种围绕Bert的变体就不断被提出,笔者也陆陆续续跟进了一些,之前也私下做了部分笔记,但总觉不够直观,不易将各模型做对比,现以表格的形式重新整理Bert及其部分变体模型,表格放到附件中,截图如下所示:
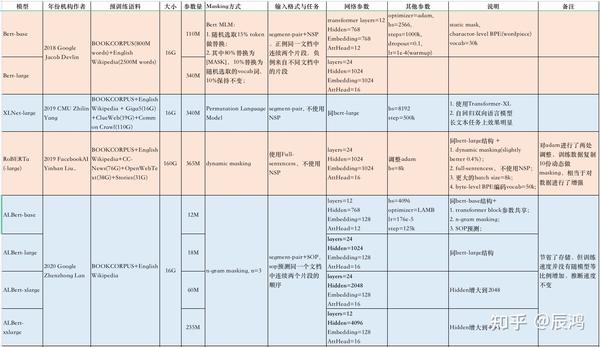

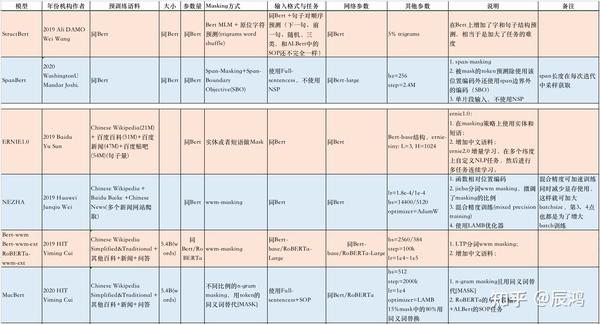

通过对比部分Bert系列变体,可以看到基于Bert预训练模型主要的优化集中在三个方面:一是改进Masking机制;二是增强预训练任务;三是增大数据量和充分预训练;参考张俊林老师《乘风破浪的PTM:两年来预训练模型的技术进展》对预训练总结如下:
- 用于预训练的高质量数据多多益善;如RoBERTa增加英文语料,BaiduERNIE增加中文百科语料等(数据高质量是前提,T5验证了引入不过滤带噪声数据后效果降低)
- 增加模型复杂度,提高模型参数量;如Large模型层数深度增加,隐层向量纬度增宽等;
- 提升预训练任务难度,包括Masking机制和句子纬度任务;如wwm/span/dynamic masking, SOP/句子序/ERNIE2.0多任务等;
- 更加充分的训练过程,包括增大训练步数,加大训练batch等;
除上面所列BERT变体外,针对生成任务NLG还有UniLM、MASS、BART等预训练模型,这里暂未列出。
pretrain_lm_0125.xlsx
发布于 2021-01-25 21:59
