
新闻推荐DKN:Deep Knowledge-Aware Network for News Recommendation

论文链接:DKN: Deep Knowledge-Aware Network for News Recommendation
发表会议:WWW' 2018
主题:News Recommendation; Knowledge Graph Representation; Deep Neu-
ral Networks; Attention Model
作者:Hongwei Wang^{1,2}, Fuzheng Zhang^{1} , Xing Xie^{2} , Minyi Guo^{1}
单位:1 Shanghai Jiao Tong University, Shanghai, China,2 Microsoft Research Asia, Beijing, China
本文作者:张恒,来自中国人民大学大数据管理与分析方法研究北京市重点实验室(BDAI)。学术型硕士研究生,研究方向Recommendation System,Deep Learning等。
本文收录于RUC AI Box专栏,为该专栏特供稿件zhuanlan.zhihu.com/RucAIBox
前言:本文提出了一种将知识图谱实体嵌入表示与神经网络融合起来,进行新闻推荐的模型DKN。一般来说,新闻文本的特点是语言高度浓缩,并且包含有很多知识实体与常识。但是以往的模型却较少考虑新闻包含的外部知识,仅仅从语义层面(semantic level)进行表示学习,没有充分挖掘新闻文本在知识层面(knowledge level)的联系。此外,新闻具有很强的时效性,一个好的新闻推荐算法应该能随用户的兴趣的改变做出相应的变化。为解决上述问题,本文提出了DKN模型。首先使用一种融合了知识的卷积神经网络KCNN(knowledge-aware convolutional neural network),将新闻的语义表示与知识表示融合起来形成新的embedding表示,再建立从用户的新闻点击历史到候选新闻的attention机制,选出得分较高的新闻推荐给用户。并且在真实的线上新闻数据集上做了大量的实验,实验结果表示,DKN模型在F1-score,AUC等指标上超过了现有的state-of-art模型。
一、写作动机
推荐系统最初是为了解决互联网信息过载的问题,帮助用户针推荐其感兴趣的内容并给出个性化的建议。新闻的推荐有三个要解决的突出问题:
1.不同于电影,餐馆等产品的推荐,新闻文章具有高度的时间敏感性,它们的相关性很快就会在短时间内失效。 过时的新闻经常被较新的新闻所取代。 导致传统的基于ID的协同过滤算法失效。
2.用户在阅读新闻的时候是带有明显的倾向性的,一般一个用户阅读过的文章会属于某些特定的主题,如何利用用户的阅读历史记录去预测其对于候选文章的兴趣是新闻推荐系统的关键 。
3.新闻类文章的语言都是高度浓缩的,包含了大量的知识实体与常识。用户极有可能选择阅读与曾经看过的文章具有紧密的知识层面的关联的文章。
以往的模型只停留在衡量新闻的语义和词共现层面的关联上,本文在考虑语义的基础上,创造性地提出加入新闻之间知识层面的相似度量,来给用户更精确地推荐可能感兴趣的新闻。
二、概念回顾
2.1 知识图谱网络嵌入(Knowledge Graph Embedding)
一个知识图谱由大量的结点以及节点之间的边组成,其中节点代表实体,边代表节点之间的关系,可以看作是许多三元组(head,relation,tail)构成的一个集合。针对知识图谱的网络嵌入目的是用一个低维稠密的向量来表示节点,保证该向量包含了节点间的相似性关系以及网络的结构信息。目前已有的很多translation-based的嵌入表示方法,具体参见以下链接:
[1]TransE:
假设 h,r,t 分别是head,tail,relation对应的向量,优化的目标是使 h+r\approx t,评分函数是 f_{r}(h,t)=\left|| h+r-t \right||_{2}^{2} ,数值越小说明对应的向量之间的关系越符合网络中实体节点的关系
[2]TransH:
评分函数 f_{r}(h,t)=\left|| h_{\bot}+r-t_{\bot} \right||_{2}^{2} ,其中 h_{\bot}=h-w_{r}^{\top}hw_{r} , t_{\bot}=t-w_{r}^{\top}tw_{r} 是h,r映射到相同空间以后的向量 ,\left|| w_{r} |\right|_{2}=1
[3]TransR:
使用一个映射矩阵,把不同的实体向量映射到相同的向量空间中 f_{r}(h,t)=\left|| h_{r}+r-t_{r} \right||_{2}^{2} ,其中 h_{r}=hM_{r},t_{r}=tM_{r}
[4]TransD:
提出了新的映射方式, f_{r}(h,t)=\left|| h_{\bot}+r-t_{\bot} \right||_{2}^{2} ,其中 h_{\bot}=(r_{p}h_{p}^{\top} +I)h,t_{\bot}=(r_{p}t_{p}^{\top} +I)t, 这里的 h_{p},r_{p},t_{p} 是另外一组实体及关系的向量表示, I 是单位矩阵。
以上网络嵌入表示方法的损失函数相同,如下:
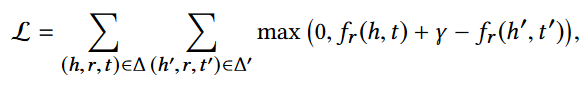

2.2 CNN句子特征提取
本文所用于提取句子特征的CNN源自于Kim CNN,用句子所包含词的词向量组成的二维矩阵,经过一层卷积操作之后再做一次max-over-time的pooling操作得到句子向量,另外在本文中还使用了不同大小的卷积核得到多组不同的向量。
三、问题定义
给定义一个用户 user_{i} 他的点击历史记为 \left\{ t_{1}^{i},t_{2}^{i},t_{3}^{i}...t_{N}^{i} \right\} 是该用户过去一段时间内层点击过的新闻的标题, N_{i} 代表用户点击过新闻的总数。每个标题都是一个词序列 t=\left\{ {w_{1},w_{2},w_{3}...w_{n}} \right\} ,标题中的每个单词都对应知识图谱中的一个实体 e 。举例来说,标题《Trump praises Las Vegas medical team》其中"Trump"与知识图谱中的实体
“Donald Trump”即现任美国总统相对应,"Las"和"Vegas"与实体"Las Vegas"。本文要解决的问题就是给定用户的点击历史,以及标题单词和知识图谱中实体的关联,我们要预测的是:一个用户 i ,是否会点击一个特定的新闻 t_{j} 。
四、融合知识的深度神经网络
整体的网络架构如下:
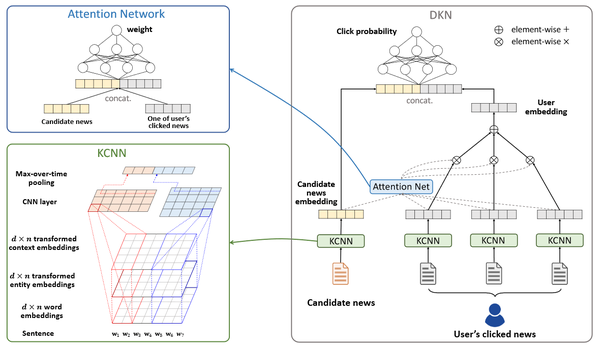
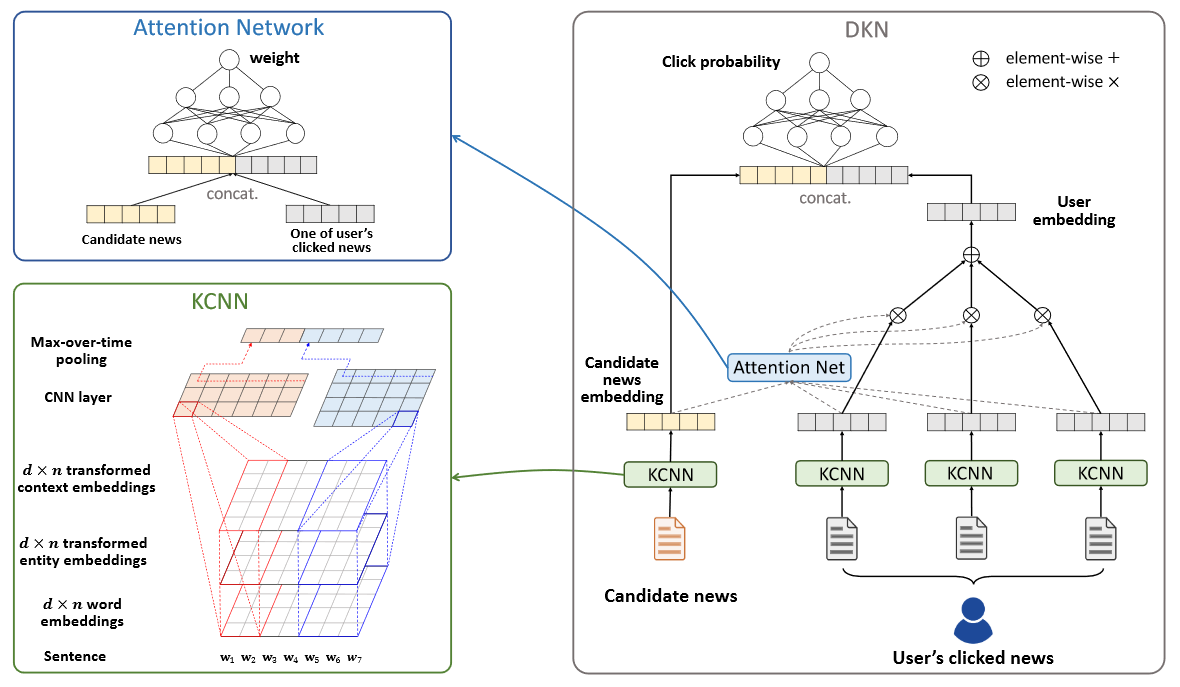
DKN的网络输入有两个:候选新闻集合,用户点击过的新闻标题序列。embedding层,都是用KCNN来提取特征,之上是一个attention层,计算候选新闻向量与用户点击历史向量之间的attentention权重,在顶层拼接两部分向量之后,用DNN计算用户点击此新闻的概率
框架整体包括三部分:
4.1 知识提取(Knowledge Distillation,字面翻译为知识升华,余以为标题起的很妙)


过程分四步:
1.识别出文本中的知识实体并利用实体链接技术消除歧义
2.利用新闻文本中的实体与关系就构成了一个原来知识图谱的一个子图,本文把所有与文中的实体的链接在一个step之内的所有实体都扩展到该子图中来。
3 .构建好知识子图以后,利用知识图谱嵌入技术得到每个实体的向量
4.根据实体向量得到对应单词的词向量
尽管目前现有的网络嵌入方法得到的向量保存了绝大多数的结构信息,但还有一定的信息损失,为了更好地利用一个实体在原知识图谱的位置信息,文中还提到了利用一个实体的上下文实体来表示该单词。一个实体 e 的上下文是指该实体在知识图谱网络中的邻居。 context(e)={e_{i} |(e,r,e_{i})\in G or (e_{i},r,e)\in G} ,G是构建的知识图谱子图。上下文表示是上下文实体的embedding的平均值:
\bar{e}=\frac{1}{|context(e)|}\sum_{e_{i}\in context(e)}{e_{i}}
4.3 新闻特征提取KCNN
获得了标题中单词和对应实体的向量之后,相比于简单地把所有的向量拼接起来以后输入给CNN,本文使用的是multi-channel和word-entity-aligned KCNN。具体做法是先把实体的向量,和实体上下文向量映射到一个空间里:
g(e_{1:n})=[g(e_{1}),g(e_{2})...g(e_{n})] , g(\bar{e}_{1:n})=[g(\bar{e}_{1}),g(\bar{e}_{2})...g(\bar{e}_{n})] 映射的方式可以是线性变换或者非线性的变换如tanh。
得到映射之后的向量之后,将两种向量作为标题单词向量额外的通道,类似图像的RGB三个通道:
W=\left[ [w_{1},g(e_{1}),g(\bar{e}_{1})],[w_{2},g(e_{2}),g(\bar{e}_{2})],...,[[w_{n},g(e_{n}),g(\bar{e}_{n})]] \right]\in R_{}^{d*n*3}
获得了多通道的词表示之后,再用CNN进行处理获取新闻标题的表示:
e(t)=[\tilde{c}^{h_{1}},\tilde{c}^{h_{2}}....\tilde{c}^{h_{m}} ] ,其中m是卷积核的个数。
4.4 基于注意力机制的用户兴趣预测
获取到用户点击过的每篇新闻的向量表示以后,作者并没有简单地作加和来代表该用户,而是计算候选文档对于用户每篇点击文档的attention,再做加权求和,计算attention:
s_{t_{k}^{i},t_{j}}=softmax(H(e(t_{k}^{i}),e(t_{j})))=\frac{exp(H(e(t_{k}^{i}),e(t_{j})))}{\sum_{k=1}^{N_{i}}{exp(H(e(t_{k}^{i}),e(t_{j})))}}
用户i对候选新闻k的表示: e(i)=\sum_{k=1}^{N_{i}}{s_{t_{k}^{i},t_{j}}}e(t_{k}^{i}))
得到用户表示和新闻表示以后用另外一个DNN来计算用户点击的概率: p_{i,t_{j}}=G(e(i),e(t_{j}))
五、实验
5.1 数据集
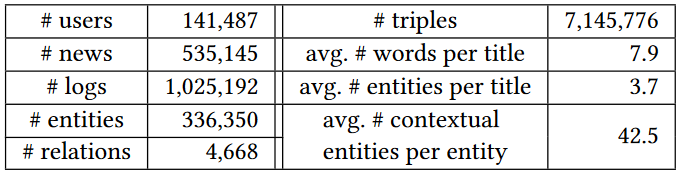
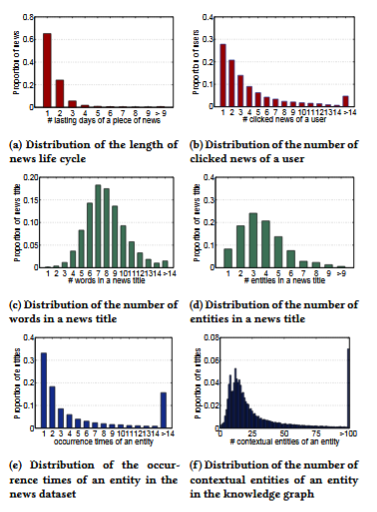
本文的数据来自bing新闻的用户点击日志,包含用户id,新闻url,新闻标题,点击与否(0未点击,1点击)。搜集了2016年10月16日到2017年7月11号的数据作为训练集。2017年7月12号到8月11日的数据作为测试集合。使用的知识图谱数据是Microsoft Satori。以下是一些基本的统计数据以及分布。

5.2 评价指标
作者使用的评价指标为F1-score和AUC值
5.3实验对比
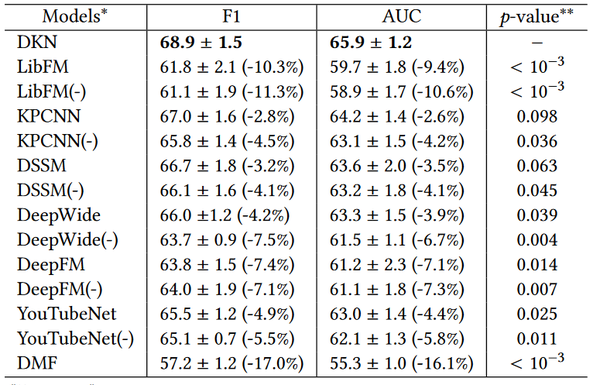

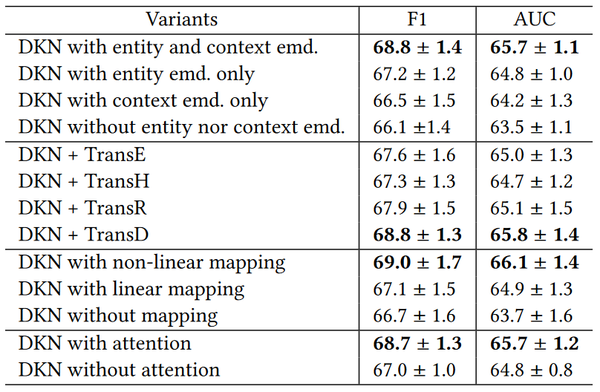
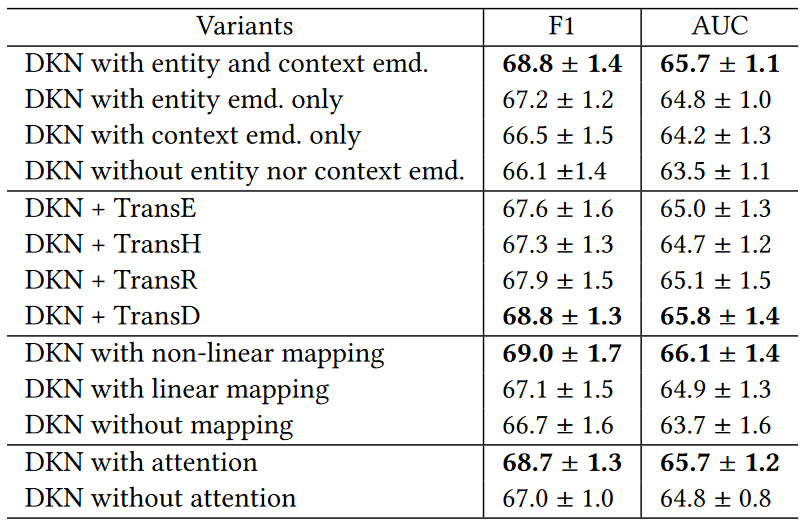
从图上看到,DKN在F1-score和AUC两个指标上,都超过了作为baseline的LibFM,DeepFM,DSSM等模型。另外,针对DKN不同的配置,作者也做了对比实验:
六、讨论
6.1 使用实体嵌入向量可以提高几乎所有baseline的效果,KPCNN,DeepWide,YouTubeNet 使用了实体嵌入表示以后分别有1.1%,1.8%,1.1%的提升。但是在DeepFM上提升效果很小,所以实验说明FM类的方法不能很好地利用知识实体。
6.2 DMF是所有模型中效果最差的一个,可能原因是新闻对时效性要求比较高,生存周期短,基于协同过滤的算法在新闻推荐中效果不佳。
6.3 除DMF之外的所有神经网络推荐模型在AUC上都超过了LibFM的baseline模型,说明深度学习模型确实适合建模新闻数据中的一些非线性的关系
6.4 本文提出的DKN模型在AUC指标上超过了次好的模型KPCNN,原因主要是(1)DKN使用多通道的词表示与实体表示来建模标题序列,能更好的建模词和实体之间的关系。(2)DKN使用attention机制,针对不同的候选新闻赋予user历史点击不同的权重,能更好地刻画用户的兴趣。
6.5 在对DKN的变体所做的对比试验中,发现TranseD效果最好。
七、总结
本文针对新闻文本时效性强,包含很多单词实体的特点,提出了DKN模型。DKN是一种content-based的模型,非常适合用来做新闻点击率预测。其特点是融合了知识图谱与深度学习,从语义层面和知识两个层面对新闻进行表示,实体和单词的对齐机制更是融合了异构的信息源,能更好地捕捉新闻之间的隐含关系。对于不同的候选新闻,DKN使用attention机制来动态地学习用户历史点击的表示。实验结果表示,加入的实体表示的DKN模型对baseline模型体现了显著的优越性,相信以后怎样更充分地利用知识提升深度神经网络的效果是一个重要的研究方向,值得人们探究。
