
Redux-Saga 漫谈

原文有更好的阅读体验 :《Redux-Saga 漫谈》。
新知识很多,且学且珍惜。
在选择要系统地学习一个新的 框架/库 之前,首先至少得学会先去思考以下两点:
- 它是什么?
- 它解决了什么问题?
然后,才会带着更多的好奇心去了解:它的由来、它名字的含义、它引申的一些概念,以及它具体的使用方式...
本文尝试通过 自我学习/自我思考 的方式,谈谈对 redux-saga 的学习和理解。
学前指引
『Redux-Saga』是一个 库(Library),更细致一点地说,大部分情况下,它是以 Redux 中间件 的形式而存在,主要是为了更优雅地 管理 Redux 应用程序中的 副作用(Side Effects)。
那么,什么是 Side Effects?
Side Effects
来看看 Wikipedia 的专业解释(敲黑板,划重点):
Side effects are the most common way that a program interacts with the outside world (people, filesystems, other computers on networks).
映射在 Javascript 程序中,Side Effects 主要指的就是:异步网络请求、本地读取 localStorage/Cookie 等外界操作:
Asynchronous things like data fetching and impure things like accessing the browser cache
虽然中文上翻译成 “副作用”,但并不意味着不好,这完全取决于特定的 Programming Paradigm(编程范式),比如说:
Imperative programming is known for its frequent utilization of side effects.
所以,在 Web 应用,侧重点在于 Side Effects 的 优雅管理(manage),而不是 消除(eliminate)。
说到这里,很多人就会有疑问:相比于 redux-thunk 或者 redux-promise, 同样在处理 Side Effects(比如:异步请求)的问题上,redux-saga 会有什么优势?
Saga vs Thunk
这里是指 redux-saga vs redux-thunk。
首先,从简单的字面意义就能看出:背后的思想来源不同 —— Thunk vs Saga Pattern。
这里就不展开讲述了,感兴趣的同学,推荐认真阅读以下两篇文章:
- 《Thunk | Rethinking Asynchronous Javascript》
- 《Saga Pattern | How to implement business transactions using Microservices》
其次,再从程序的角度来看:使用方式上的不同。
Note:以下示例会省去部分 Redux 代码,如果你对 Redux 相关知识还不太了解,那么《Redux 卍解》了解一下。
redux-thunk
一般情况下,actions 都是符合 FSA 标准的(即:a plain javascript object),像下面这样:
{
type: 'ADD_TODO',
payload: {
text: 'Do something.'
}
};它代表的含义是:每次执行 dispatch(action) 会通知 reducer 将 action.payload(数据) 以 action.type 的方式(操作)同步更新到 本地 store 。
而一个 丰富多变的 Web 应用,payload 数据往往来自于远端服务器,为了能将 异步获取数据 这部分代码跟 UI 解耦,redux-thunk 选择以 middleware 的形式来增强 redux store 的 dispatch 方法(即:支持了 dispatch(function)),从而在拥有了 异步获取数据能力 的同时,又可以进一步将 数据获取相关的业务逻辑 从 View 层分离出去。
来看看以下代码:
// action.js
// ---------
// actionCreator(e.g. fetchData) 返回 function
// function 中包含了业务数据请求代码逻辑
// 以回调的方式,分别处理请求成功和请求失败的情况
export function fetchData(someValue) {
return (dispatch, getState) => {
myAjaxLib.post("/someEndpoint", { data: someValue })
.then(response => dispatch({ type: "REQUEST_SUCCEEDED", payload: response })
.catch(error => dispatch({ type: "REQUEST_FAILED", error: error });
};
}
// component.js
// ------------
// View 层 dispatch(fn) 触发异步请求
// 这里省略部分代码
this.props.dispatch(fetchData({ hello: 'saga' }));如果同样的功能,用 redux-saga 如何实现呢?它的优势在哪里?
redux-saga
先来看下代码,大致感受下(后面会细讲):
// saga.js
// -------
// worker saga
// 它是一个 generator function
// fn 中同样包含了业务数据请求代码逻辑
// 但是代码的执行逻辑:看似同步 (synchronous-looking)
function* fetchData(action) {
const { payload: { someValue } } = action;
try {
const result = yield call(myAjaxLib.post, "/someEndpoint", { data: someValue });
yield put({ type: "REQUEST_SUCCEEDED", payload: response });
} catch (error) {
yield put({ type: "REQUEST_FAILED", error: error });
}
}
// watcher saga
// 监听每一次 dispatch(action)
// 如果 action.type === 'REQUEST',那么执行 fetchData
export function* watchFetchData() {
yield takeEvery('REQUEST', fetchData);
}
// component.js
// -------
// View 层 dispatch(action) 触发异步请求
// 这里的 action 依然可以是一个 plain object
this.props.dispatch({
type: 'REQUEST',
payload: {
someValue: { hello: 'saga' }
}
});将从上面的代码,与之前的进行对比,可以归纳以下几点:
- 数据获取相关的业务逻辑 被转移到单独 saga.js 中,不再是掺杂在 action.js 或 component.js 中。
- dispatch 的参数依然是一个纯粹的 action (FSA),而不是充满 “黑魔法” thunk function。
- 每一个 saga 都是 一个 generator function,代码采用 同步书写 的方式来处理 异步逻辑(No Callback Hell),代码变得更易读(没错,这很 co~ )。
- 同样是受益于 generator function 的 saga 实现,代码异常/请求失败 都可以直接通过 try/catch 语法直接捕获处理。
深入学习
最简单完整的一个单向数据流,从 hello saga 说起。
先来看看,如何将 store 和 saga 关联起来?
import { createStore, applyMiddleware } from 'redux';
import createSagaMiddleware from 'redux-saga';
import rootSaga from './sagas';
import rootReducer from './reducers';
// 创建 saga middleware
const sagaMiddleware = createSagaMiddleware();
// 注入 saga middleware
const enhancer = applyMiddleware(sagaMiddleware);
// 创建 store
const store = createStore(rootReducer, /* preloadedState, */ enhancer);
// 启动 saga
sagaMiddleWare.run(rootSaga);代码分析:
- 8L:通过工厂函数
createSagaMiddleware创建 sagaMiddleware(当然创建时,你也可以传递一些可选的配置参数)。 - 10L~13L:注入 sagaMiddleware,并创建 store 实例,意味着:之后每次执行
store.dispatch(action),数据流都会经过 sagaMiddleware 这一道工序,进行必要的 “加工处理”(比如:发送一个异步请求)。 - 16L:启动 saga,也就是执行 rootSaga,通常是程序的一些初始化操作(比如:初始化数据、注册 action 监听)。
整合以上分析:程序启动时,run(rootSaga) 会开启 sagaMiddleware 对某些 action 进行监听,当后续程序中有触发 dispatch(action) (比如:用户点击)的时候,由于数据流会经过 sagaMiddleware,所以 sagaMiddleware 能够判断当前 action 是否有被监听?如果有,就会进行相应的操作(比如:发送一个异步请求);如果没有,则什么都不做。
所以来看看,初始化程序时,rootSaga 具体可以做些什么?
// sagas/index.js
import { fork, takeEvery, put } from 'redux-saga/effects';
import { push } from 'react-router-redux';
import ajax from '../utils/ajax';
export default function* rootSaga() {
// 初始化程序(欢迎语 :-D)
console.log('hello saga');
// 首次判断用户是否登录
yield fork(function* fetchLogin() {
try {
// 异步请求用户信息
const user = yield call(ajax.get, '/userLogin');
if (user) {
// 将用户信息存入 本地 store
yield put({ type: 'UPDATE_USER', payload: user })
} else {
// 路由跳转到 403 页面
yield put(push('/403'));
}
} catch (e) {
// 请求异常
yield put(push('/500'));
}
});
// watcher saga 监听 dispatch 传过来的 action
// 如果 action.type === 'FETCH_POSTS' 那么 请求帖子列表数据
yield takeEvery('FETCH_POSTS', function* fetchPosts() {
// 从 store 中获取用户信息
const user = yield select(state => state.user);
if (user) {
// TODO: 获取当前用户发的帖子
}
});
}如同前面所说,rootSaga 里面的代码会在程序启动时,会依次被执行:
- 8L:控制台同步打印出 'hello saga' 欢迎语。
- 11L~21L:发起一个 异步非阻塞数据请求(Non-Blocking),初始化用户信息,也做了一些异常情况的容错处理。
- 31L~38L:
takeEvery方法会注册一个 watcher saga,对{ type: 'FETCH_POSTS' }的 action 实施监听,后续会执行与之匹配的 worker saga(比如:fetchPosts)。
PS:通常情况下,在无需进行 saga 按需加载 的情况下,rootSaga 里会集中 引入并注册 程序中所有用到的 watcher saga(就像 combine rootReducer 那样)。
最后再看看,程序启动后,一个完整的单向数据流是如何形成的?
import React from 'react';
import { connect } from 'react-redux';
// 关联 store 中 state.posts 字段 (即:帖子列表数据)
@connect(({ posts }) => ({ posts }))
class App extends React.PureComponent {
componentDidMount() {
// dispatch(action) 触发数据请求
this.props.dispatch({ type: 'FETCH_POSTS' });
}
render() {
const { posts = [] } = this.props;
return (
<ul>
{ posts.map((post, index) => (<li key={index}>{ post.title }</li>)) }
</ul>
);
}
}
export default App;当组件 <App /> 被执行挂载后,通过 dispatch({ type: 'FETCH_POSTS' }) 通知 sagaMiddleware 寻找到 匹配的 watcher saga 后,执行对应的 woker saga,从而发起数据异步请求 ...... 最终 <App/> 会在得到最新 posts 数据后,执行 re-render 更新 UI。
至此,以上三个部分代码实现了基于 redux-saga 的一次 完整单向数据流,如果用一张图来表现的话 ,应该是这样:

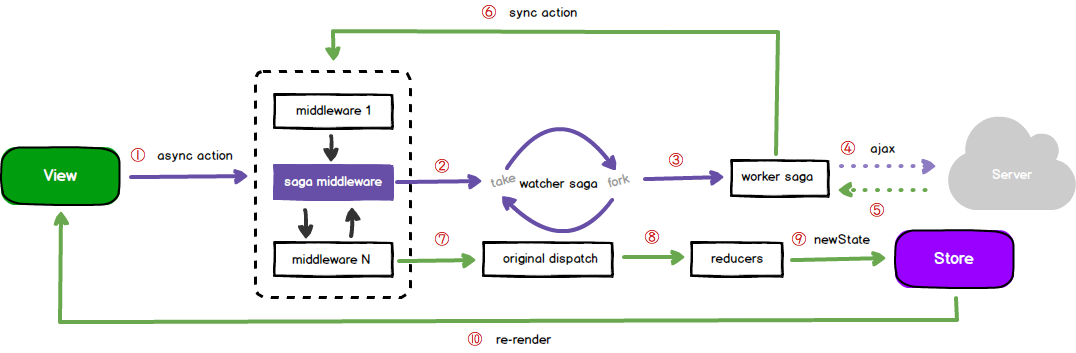
文章看到这里,对于一个 redux-saga 新手而言,可能会留有这样的疑惑: 上述代码中 put/call/fork/takeEvery 这些方法是干什么用的?这就是接下来要详细讨论的 saga effects。
Effects
前面说到,saga 是一个 generator function,这就意味着它的执行原理必然是下面这样:
function isPromise(value) {
return value && typeof value.then === 'function';
}
const iterator = saga(/* ...args */);
// 方法一:
// 一步一步,手动执行
let result;
result = iterator.next();
result = iterator.next(result.value);
result = iterator.next(result.value);
// ...
// done!!
// 方法二:
// 函数封装,自主执行
function next(args) {
const result = iterator.next(args);
if (result.done) {
// 执行结束
console.log(result.value);
} else {
// 根据 yielded 的值,决定什么时候继续执行(resume)
if (isPromise(result.value)) {
result.value.then(next);
} else {
next(result.value)
}
}
}
next();也就是说,generator function 在未执行完前(即:result.done === false),它的控制权始终掌握在 执行者(caller)手中,即:
- caller 决定什么时候 恢复(resume)执行。
- caller 决定每次 yield expression 的返回值。
而 caller 本身要实现上面上述功能需要依赖原生 API :iterator.next(value) ,value 就是 yield expression 的返回值。
举个例子:
function* gen() {
const value = yield Promise.reslove('hello saga');
console.log('value: ', value); // value??
}单纯的看 gen 函数,没人知道 value 的值会是多少?
这完全取决于 gen 的执行者(caller),如果使用上面的 next 方法来执行它,value 的值就是 'hello saga',因为 next 方法对 expression 为 promise 时,做了特殊处理(这不就是缩小版的 co 么~ wow~⊙o⊙)。
换句话说,expression 可以是任何值,关键是 caller 如何来解释 expression,并返回合理的值 !
以此结论,推理来看:
- 大家熟知的 co 可以认为是一个 caller,它解释的 expression 是:promise/thunk/generator function/iterator 等。
- 这里的 sagaMiddleware 也算是一个 caller,它主要解释的 expression 就是 effect(当然还可以是 promise/iterator) 。
讲了这么多,那么 effect 到底是什么呢?先来看看官方解释:
An effect is a plain JavaScript Object containing some instructions to be executed by the saga middleware.
意思是说:effect 本质上是一个普通对象,包含着一些指令信息,这些指令最终会被 saga middleware 解释并执行。
用一段代码来解释上述这句话:
function* fetchData() {
// 1. 创建 effect
const effect = call(ajax.get, '/userLogin');
console.log('effect: ', effect);
// effect:
// {
// CALL: {
// context: null,
// args: ['/userLogin'],
// fn: ajax.get,
// }
// }
// 2. 执行 effect,即:调用 ajax.get('/userLogin')
const value = yield effect;
console.log('value: ', value);
}可以明显的看出:
- call 方法用来创建 effect 对象,被称作是 effect factory。
- yield 语法将 effect 对象 传给 sagaMiddleware,被解释执行,并返回值。
这里的 call effect 表示执行 ajax.get('user/Login') ,又因为它的返回值是 promise, 为了等待异步结果返回,fetchData 函数会暂时处于 阻塞 状态。
除了上述所说的 call effect 之外,redux-saga 还提供了很多其他 effect 类型,它们都是由对应的 effect factory 生成,在 saga 中应用于不同的场景,比较常用的是:
- put:相当于在 saga 中调用 store.dispatch(action)。
- take:阻塞当前 saga,直到接收到指定的 action,代码才会继续往下执行,有种 Event.once() 事件监听的感觉。
- fork: 类似于 call effect,区别在于它不会阻塞当前 saga,如同后台运行一般,它的返回值是一个 task 对象。
- cancel:针对 fork 方法返回的 task ,可以进行取消关闭。
- ...等等
其中,比较难以理解的就属:如何区分 call 和 fork?什么是阻塞/非阻塞?这是接下来要讲的。
Call vs Fork
前面已经提到,saga 中 call 和 fork 都是用来执行指定函数 fn,区别在于:
- call effect 会阻塞当前 saga 的执行,直到被调用函数 fn 返回结果,才会执行下一步代码。
- fork effect 则不会阻塞当前 saga,会立即返回一个 task 对象。
举个例子,假设 fn 函数返回一个 promise:
// 模拟数据异步获取
function fn() {
return new Promise((resolve, reject) => {
setTimeout(() => {
resolve('hello saga');
}, 2000);
});
}
function* fetchData() {
// 等待 2 秒后,打印欢迎语(阻塞)
const greeting = yield call(fn);
console.log('greeting: ', greeting);
// 立即打印 task 对象(非阻塞)
const task = yield fork(fn);
console.log('task: ', task);
}显然,fork 的异步非阻塞特性更适合于在后台运行一些不影响主流程的代码(比如:后台打点/开启监听),这往往是加快页面渲染的一种方式,有点类似于 Egg 的 runInBackground,倘若在这种情况下,你依然要获取返回结果,可以这样做:
const task = yield fork(fn);
// 0.16.0 api
task.done().then((greeting) => {
console.log('greeting: ', greeting);
});
// 1.0.0-beta.0 api
task.toPromise().then((greeting) => {
console.log('greeting: ', greeting);
});PS:这里的函数 fn 是一个 normal function,其实它还可以是一个 generator function(被称作是 Child Saga)。
最后的最后,再简单聊聊 saga 中的错误处理方式?
Error Handling
在 saga 中,无论是请求失败,还是代码异常,均可以通过 try catch 来捕获。
倘若访问一个接口出现代码异常,可能是网络请求问题,也可能是后端数据格式问题,但不管怎样,给予日志上报或友好的错误提示是不可缺少的,这也往往体现了代码的健壮性,一般会这么做:
function* saga() {
try {
const data = yield call(fetch, '/someEndpoint');
return data;
} catch(e) {
// 日志上报
logger.error('request error: ', e);
// 错误提示
antd.message.error('请求失败');
}
}这是最正确的处理方式,但这里更想讨论的是:如果忘记写 try catch 进行异常捕获,结果会怎么样?
就好比下面这样:
function* saga1 () { /* ... */ }
function* saga2 () { throw new Error('模拟异常'); }
function* saga3 () { /* ... */ }
function* rootSaga() {
yield fork(saga1);
yield fork(saga2);
yield fork(saga3);
}
// 启动 saga
sagaMiddleware.run(rootSaga);假设 saga2 出现代码异常了,且没有进行异常捕获,这样的异常会导致整个 Web App 崩溃么?答案是:肯定的!
来具体解释下:
redux-saga 中执行 sagaMiddleware.run(rootsaga) 或 fork(saga) 时,均会返回一个 task 对象(上文中说到),嵌套的 task 之间会存在 父子关系,就比如上述代码:
- rootSaga 生成了 rootTask。
- saga1,saga2 和 saga3,在 rootSaga 内部执行,生成的 task,均被认为是 rootTask 的 childTask。
现在某一个 childTask 异常了(比如这里的: saga2),那么它的 parentTask(如:rootTask)收到通知先会执行自身的 cancel 操作,再通知其他 childTask(如:saga1,saga3) 同样执行 cancel 操作。(这其实正是 Saga Pattern 的思想)
但这就意味着,用户可能会因为一个按钮点击引发的异常,而导致整个 Web 应用的功能均无法使用!!
那么,面对这样的问题,如何优化呢?隔离 childTask 是首先想到的一种方案。
export default function* root() {
yield spawn(saga1);
yield spawn(saga2);
yield spawn(saga3);
}使用 spawn 替换 fork,它们的区别在于 spawn 返回 isolate task,不存在 父子关系,也就是说,即使 saga2 挂了,rootSaga 也不受影响,saga1 和 saga3 自然更不会受影响,依然可以正常工作。
但这样的方案并不是让人最满意的!如果因为某一次网络原因,导致 saga2 挂了,在不刷新页面的情况下,用户连重试的机会都不给,显然是不合理的,那么如果可以做到 saga 自动重启呢?社区里已经有一个比较好的方案了:
function* rootSaga () {
const sagas = [ saga1, saga2, saga3 ];
yield sagas.map(saga =>
spawn(function* () {
while (true) {
try {
yield call(saga);
} catch (e) {
console.log(e);
}
}
})
);
}上述代码通过在最上层为每一个 childSaga 添加异常捕获,并通过 while(true) {} 循环自动创建新的 childTask 取代 异常 childTask,以保证功能依然可用(这就类似于 Egg 中某一个 woker 进程 挂了,自动重启一个新的 woker 进程一样)。
OK,差不多就先讲这些吧... 完!
