
一文带你了解pandas的DataFrame

在使用Python进行数据分析时,最常用的莫过于pandas包中的二维数据结构DataFrame(数据框),因为它可容纳不同的列数据类型,十分贴合实际应用。了解并掌握DataFrame的脾气秉性格外重要,如果不了解它是什么、包含什么,那么你将不能灵活控制它,本文将带你走进pandas的DataFrame,来看看它到底是什么?
1. 先聊聊numpy
pandas包中的数据结构是以numpy包作为基础,只不过增添了一些专门适合数据分析的功能和属性。
numpy中一维和二维数据结构均为ndarray,一般情况下,它存储的数据类型都是“数”,包括:整数、浮点数、复数。numpy具有着优秀的矩阵计算性能,可谓专为“算数”而生,其计算速度特别快,特别适合大数据的计算。
若要使用numpy,首先要导入该包:import numpy as np
创建numpy一维数组,需要传入一个列表参数,其元素查找方式类似于列表,但又和列表有着截然不同的区别:
区别一:array数组元素的数据类型必须一致,列表可以包含不同的数据类型
区别二:array可以进行向量计算
区别三:array具有统计功能
区别四:array数组乘以标量n表示每个元素值放大n倍,列表乘以标量n表示重复n次
请看下图:


numpy二维数组则是一个矩阵,较一维数组多了一个“轴”,有行也有列。
类似地,创建numpy二维数组,传入一个嵌套列表即可,每个子列表的元素数目相同,有多少个子列表,二维数组就有多少行。


其元素的查询方式可通过“[行标,列标]”的方式,如果要查询一行或一列,则用冒号(:)来代替。
在统计功能方面,二维数组较一维数组多了个“轴选项”,axis=0表示按列统计,axis=1表示按行统计。如果不加“轴选项”参数,则默认按整个数组计算统计量。如下图:


2. 开启pandas
刚才说了,pandas是以numpy为基础开发而来,它具有所有numpy优秀计算性能,额外又增加了适合数据分析的成分。来看看都增添了些什么?
在下面的研究前,先导入pandas包:import pandas as pd
pandas一维数据结构:Series(向量)
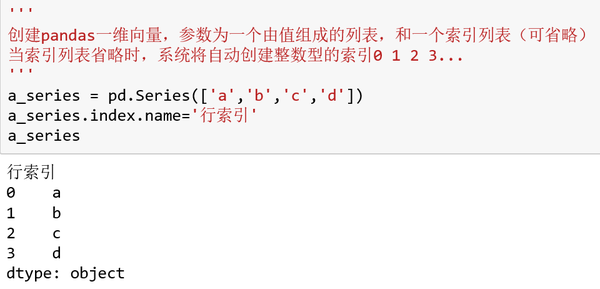
在创建Series向量的时候,向其传入一个array一维数组,然后可显式指定其索引index,如果不指定index,则系统默认生成整数型索引0 1 2 3……这里的索引index指的是行索引,行索引具有一个name属性,意思是index的名字,此处不懂没关系,在后面的DataFrame中也会继续讲到。下面几个图分别显示了:不指定index,指定index。



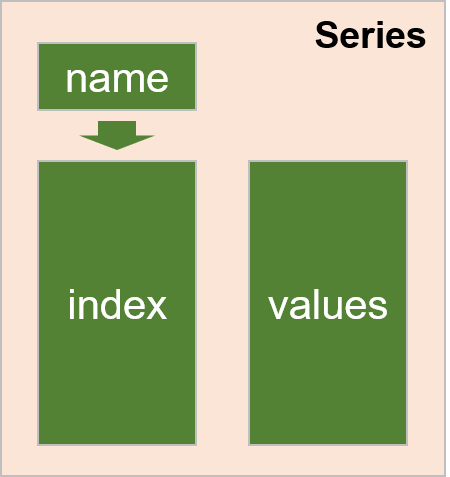
一个Series的完整结构包括:
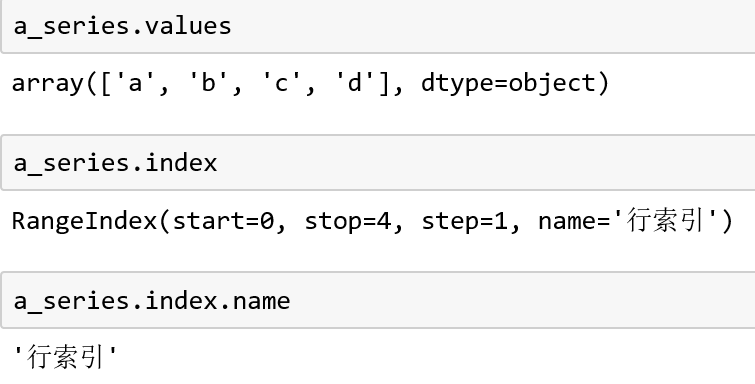
数据内容部分Series.values
行索引部分Series.index
结构图和示例图如下:


查找Series元素有两种方法:


Series的统计属性和数据类型:


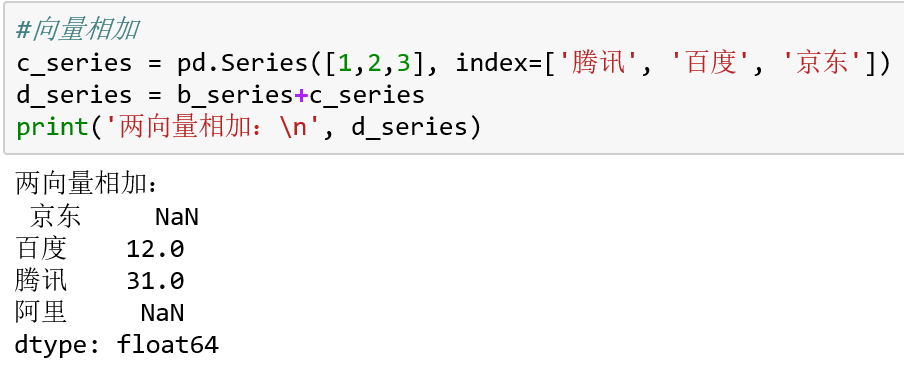
两个Series向量相加,按照index自动匹配,无法匹配的则输出NaN:

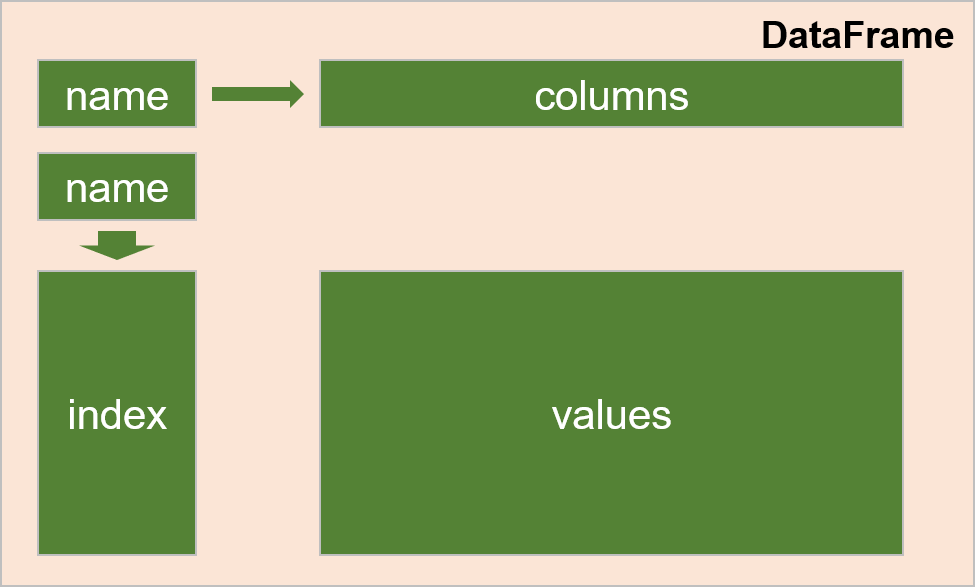
DataFrame可以看成是由若干Series组合而成,这些Series共享同一index行索引,列索引则包含所有Series的列名称,行索引和列索引均有name属性。
标准的DataFrame结构包含:
①数据内容部分df.values,它是一个numpy的ndarray类型
②行索引df.index,列索引df. columns
③行索引的名字df.index.name,和列索引的名字df.columns.name
结构图如下:

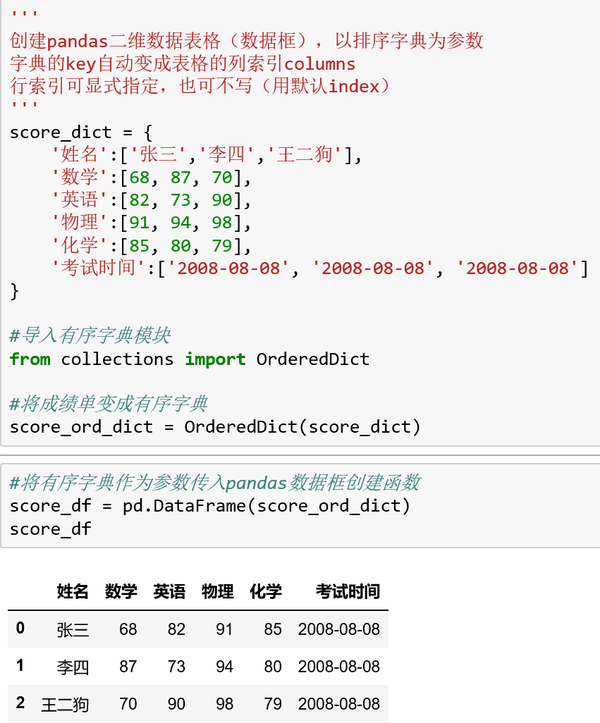
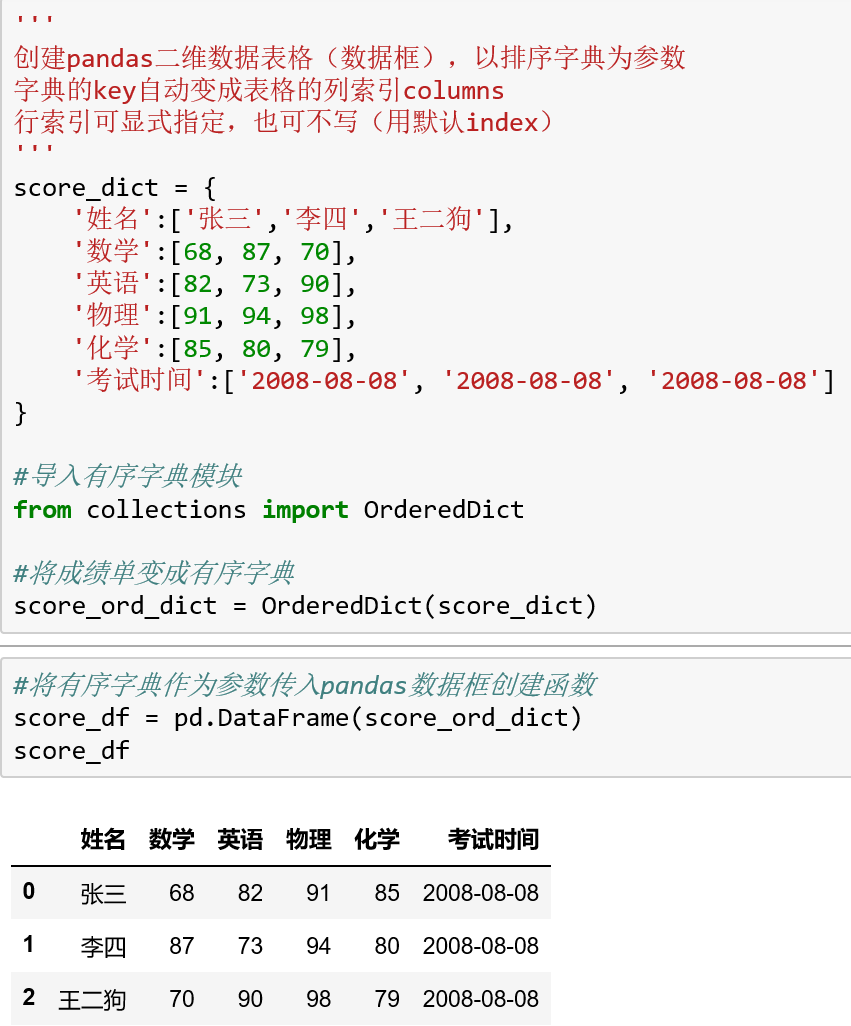
创建DataFrame可以将一个(有序)字典传入函数,字典的键key将自动变成数据框的列索引columns,如果不显式指定行索引index,则系统自动生成整数型行索引0 1 2 3……
创建示例:
分别查看数据框的列索引columns和行索引index:


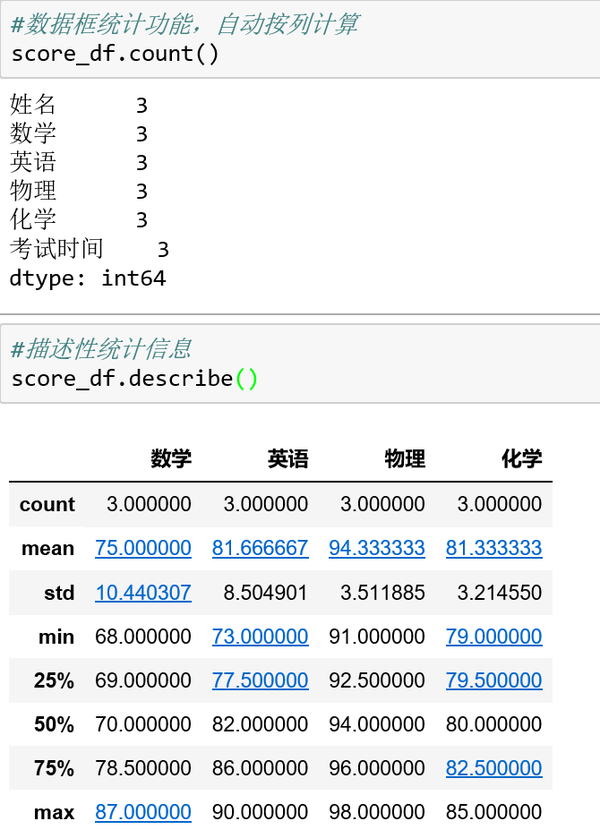
DataFrame的统计功能自动按列计算:
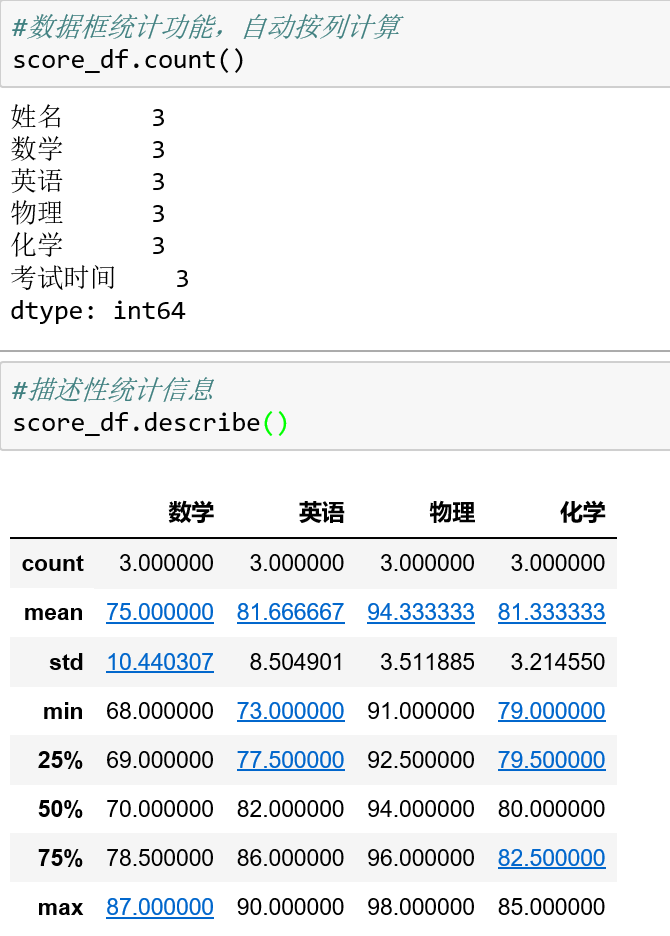
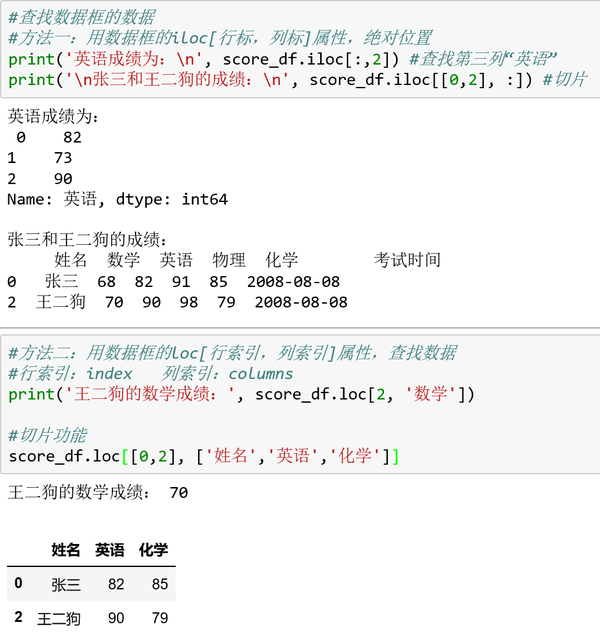
DataFrame的查找元素方法也有df.iloc[行标,列标]和df.loc[行索引,列索引]两种方式:
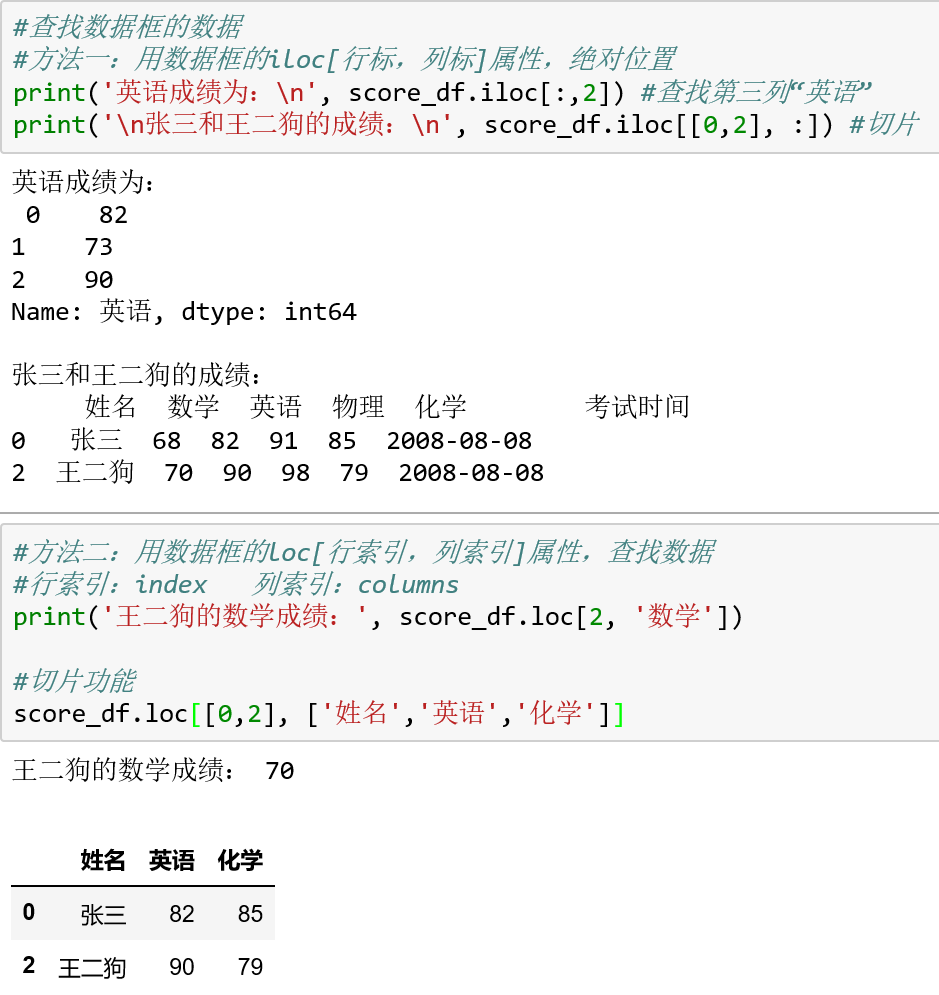
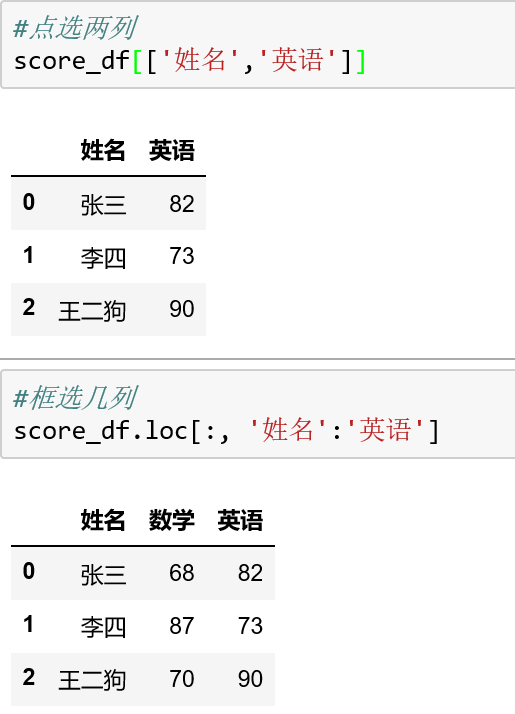
在DataFrame中“点选”几列和“框选”几列的方法:
点选:选择不连续的几列
框选:选择连续的几列

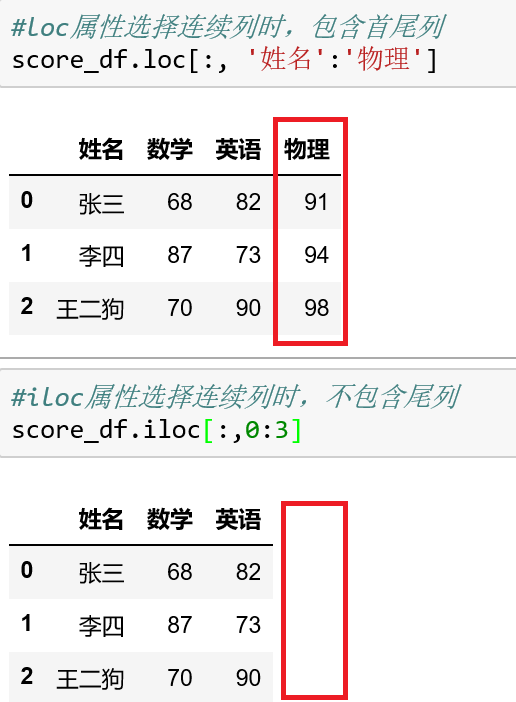
DataFrame的loc属性在查找连续几列时,是包含首尾列的;而iloc属性则不包含尾列。日常使用中loc属性更直观、更常用。这一功能经常用来取数据框子集,举例:

此外,DataFrame还有一个特殊的筛选属性(条件筛选),可根据某一列满足某一条件,或整个数据框满足某一条件,然后生成一个布尔型索引,用于数据筛选。
例如:DataFrame的某一列与一个标量进行比较,生成一个布尔型Series索引,可将其传入df.loc中,筛选出满足条件的 行:


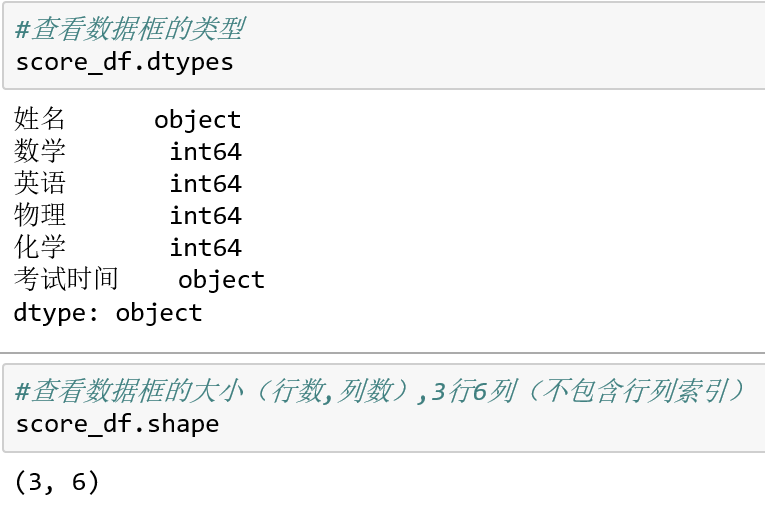
查看DataFrame的数据类型,与英语的复数相似,单个Series用dtype,多个Series就变成了复数形式dtypes。
查看DataFrame的形状,即有多少行多少列数据,用shape属性。

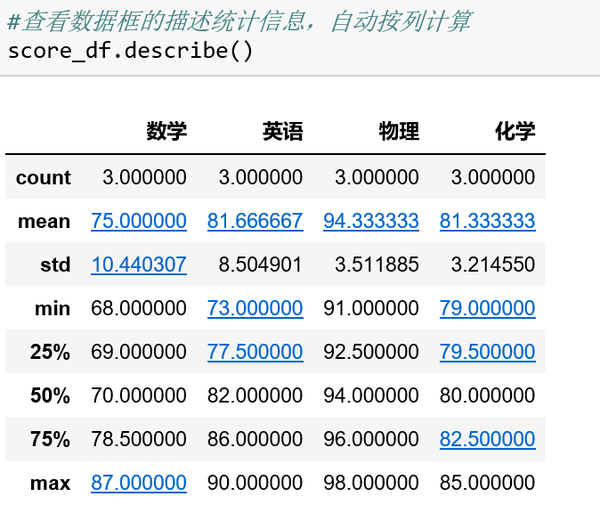
描述性统计信息默认按列统计:

3. 总结
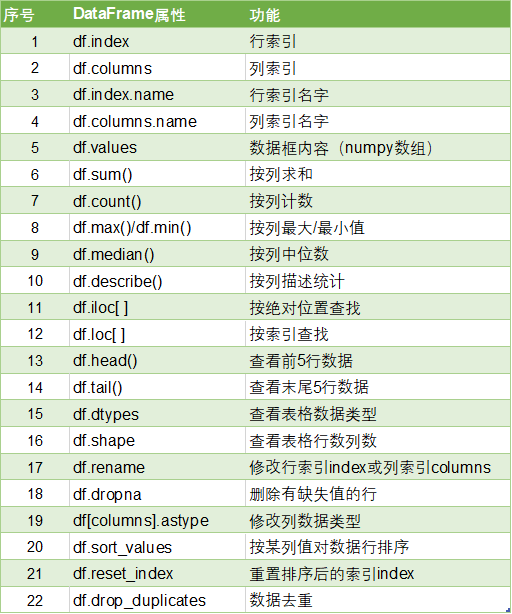
以上内容重点讲解了日后数据分析中常用的DataFrame的结构和一些基本属性,下表给出《DataFrame常用属性速查表》,牢记此表,将让你节约65%的数据清洗时间,别问我数字怎么来的,我猜的,总之将大幅提升你清理数据的效率。

《速查表》的后半部分属性将在下篇文章--应用到实际数据分析过程时,结合相应步骤,作详细讲解,你会发现:全是套路。。。

