
策略梯度(Policy Gradient)实现(CartPole-v1)

计算机练习生/文史哲爱好者/云吸猫轻度患者
理论
看李宏毅的强化学习做的笔记:


策略梯度的目标就是使得以下的期望最大化:
\bar R_\theta = \sum_\tau R(\tau)P_\theta(\tau)\\
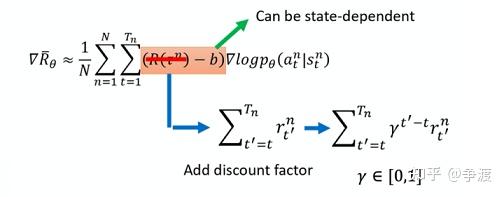
最终要求的式子为:\bigtriangledown R_{\theta} = \frac{1}{N} \sum_{n=1}^N \sum_{t=1}^{T_n}R(\tau ^n)\bigtriangledown log P_\theta(a_t^n|s_t^n)\\
如果在 s_t 执行 a_t 这个动作并且最终的奖励是正的,那么应该增大选择该动作的概率;否则就应该较小。
并且在实现的时候,还可以增加两个Tips:
- 增加baseline:


- 为每个动作添加合适的分数:

实现
- 动作选择
在Q-learning、DQN中,都是根据 \epsilon-greedy 策略,但是这里是依据概率进行采样,因为我们的目标是不断的对动作选择的概率进行调整。
def choose_action(self, s):
s = torch.unsqueeze(torch.FloatTensor(s), 0) # [1, n_states]
logits = self.model(s) # [1, n_actions]
probs = F.softmax(logits, 1)
action = torch.multinomial(probs, 1) # 根据概率采样
self.log_a.append(torch.log(probs[0][action].squeeze(0))) # 保存公式中的log值
return action.item()- 更新策略
def learn(self):
processed_ep_r = np.zeros_like(self.ep_r)
sum = 0
for i in reversed(range(0, len(self.ep_r))): # 回溯
sum = sum * self.gamma + self.ep_r[i]
processed_ep_r[i] = sum
eps = np.finfo(np.float32).eps.item()
processed_ep_r = (processed_ep_r - np.mean(processed_ep_r)) / (np.std(processed_ep_r) + eps) # 归一化
processed_ep_r = torch.FloatTensor(processed_ep_r)
loss = -torch.sum(torch.cat(self.log_a) * processed_ep_r)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.log_a = [] # 数据使用完后即丢弃
self.ep_r = []完整代码
import gym
import argparse
import torch
import torch.nn as nn
import numpy as np
import torch.nn.functional as F
import matplotlib.pyplot as plt
class Net(nn.Module):
def __init__(self, n_states, n_actions, emb_dim):
super(Net, self).__init__()
self.n_states = n_states
self.n_actions = n_actions
self.emb_dim = emb_dim
self.fc = nn.Linear(self.n_states, self.emb_dim)
self.out = nn.Linear(self.emb_dim, self.n_actions)
def forward(self, x):
x = self.fc(x)
x = F.relu(x)
x = self.out(x)
return x
class PG(nn.Module):
def __init__(self, n_states, n_actions, args):
super().__init__()
self.n_states = n_states
self.n_actions = n_actions
self.gamma = args.gamma
self.lr = args.lr
self.log_a = []
self.ep_r = []
self.model = Net(self.n_states, self.n_actions, args.emb_dim)
self.optimizer = torch.optim.Adam(self.model.parameters(), lr=self.lr)
def choose_action(self, s):
s = torch.unsqueeze(torch.FloatTensor(s), 0) # [1, n_states]
logits = self.model(s) # [1, n_actions]
probs = F.softmax(logits, 1)
action = torch.multinomial(probs, 1) # 根据概率采样
self.log_a.append(torch.log(probs[0][action].squeeze(0))) # 保存公式中的log值
return action.item()
def store(self, r):
self.ep_r.append(r)
def learn(self):
processed_ep_r = np.zeros_like(self.ep_r)
sum = 0
for i in reversed(range(0, len(self.ep_r))): # 回溯
sum = sum * self.gamma + self.ep_r[i]
processed_ep_r[i] = sum
eps = np.finfo(np.float32).eps.item()
processed_ep_r = (processed_ep_r - np.mean(processed_ep_r)) / (np.std(processed_ep_r) + eps) # 归一化
processed_ep_r = torch.FloatTensor(processed_ep_r)
loss = -torch.sum(torch.cat(self.log_a) * processed_ep_r)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.log_a = [] # 数据使用完后即丢弃
self.ep_r = []
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--n_episodes', type=int, default=500)
parser.add_argument('--emb_dim', type=int, default=128)
parser.add_argument('--gamma', type=float, default=0.95)
parser.add_argument('--seed', type=int, default=1)
parser.add_argument('--lr', type=float, default=0.01)
args = parser.parse_args()
env = gym.make('CartPole-v1')
env.seed(args.seed)
torch.manual_seed(args.seed)
np.random.seed(args.seed)
n_actions = env.action_space.n
n_states = env.observation_space.shape[0]
agent = PG(n_states, n_actions, args)
x, y = [], []
for episode in range(args.n_episodes):
ep_reward, s = 0, env.reset()
while True:
a = agent.choose_action(s)
s_, r, done, _ = env.step(a)
agent.store(r)
ep_reward += r
s = s_
if done:
break
agent.learn()
print('Episode {:03d} | Reward:{:.03f}'.format(episode, ep_reward))
x.append(episode)
y.append(ep_reward)
plt.plot(x, y)
plt.show()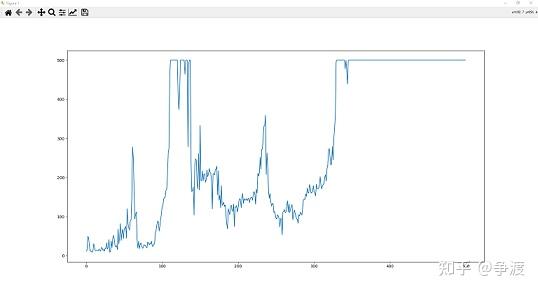
编辑于 2021-03-21 10:17
