
跳出思维的盒子,谈一谈交互式视频目标分割中标注帧的选取

本文是对CVPR 2021论文《Learning to Recommend Frame for Interactive Video Object Segmentation in the Wild》的解读,该论文由湖南大学、群核科技(酷家乐)、美团、上海科技大学共同合作完成。本文提出了一种适用于自然场景下的交互式视频目标分割框架,其中用户可以在推荐的视频帧提供额外标注来帮助提高分割质量。
前言
视频目标分割任务的目的是在视频序列中分割特定的目标。然而,收集一个细粒度、像素级标注的数据集成本是十分高昂。例如,标注DAVIS[1]数据集每个视频帧中的一个物体就需要100秒。
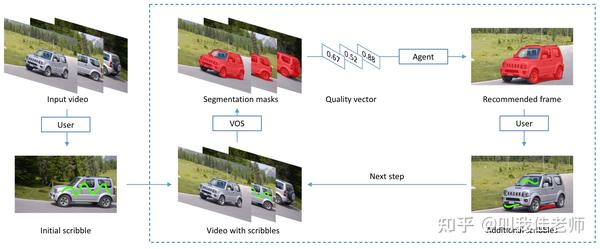
为了减少人工标注的成本,Caelles等人[2]提出了一种交互式视频目标分割任务,该任务希望在提供少量的人工监督信号来实现令人满意的分割结果。具体地,给定一个视频序列,用户首先选取能够最好表达待分割目标的其中一帧视频图像,并以涂鸦的方式标注该目标。随后,分割算法基于用户提供的初始涂鸦标注给出视频每帧的分割结果,用户通过在某一视频帧上绘制涂鸦来标记出算法分割错误的区域来提升算法的分割结果。
现有的框架选取其中最差的视频帧来纠正分割结果,然而,用户很难从分割结果中准确地找出分割质量最差的一帧;况且,具有最差质量评价指标的视频帧,并不一定是对整体视频分割质量提升最有帮助的帧(见题图)。
方法
本文将交互式视频目标分割中的关键帧选择问题建模为一个马尔可夫决策过程,通过强化学习框架,让智能体学习如何推荐关键帧。完成学习的智能体可以自动判断出最有价值的视频关键帧,使得交互式视频目标分割在自然场景下更为可行。

状态(state)
为了减少状态空间,我们采取分割质量作为每个帧的状态。额外的,我们还考虑每帧历史推荐的次数。
动作(action)
智能体的动作即为推荐某个帧,即视频帧的索引。
奖励(reward)
本文期望学习到的策略至少应该比随机选取的平均性能要高。然而,实验表明这是不充分的。所以,我们提出以下奖励函数:
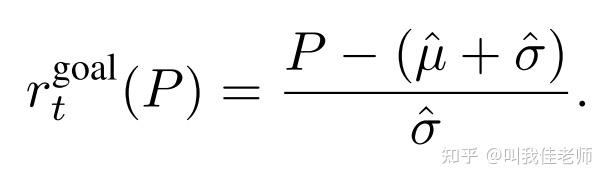

同时,我们期望推荐帧覆盖的范围应该较广,提出下面的辅助奖励函数:
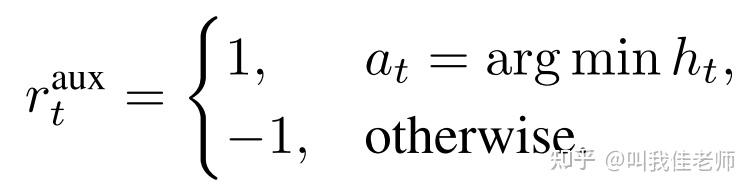

目标(target)
我们采用Double Q-learnig来求解该问题:


实验
本文选取三个state-of-the-art的VOS算法(IPN、MANet和ATNet),在两个常用的视频目标分割数据集(DAVIS和YouTube-VOS)上验证了本文提出的模型。
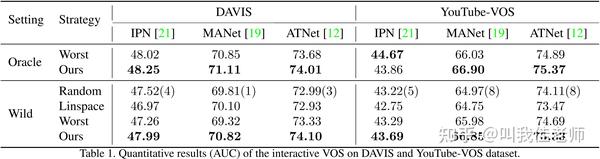

如上表所示,在公开的数据集上的实验结果表明,经过学习的智能体可以在不对现有视频目标分割算法进行任何改变的前提下,有效地进行视频关键帧推荐。


另外,本文将学习到的智能体与人类标注者进行了对比。实验结果表明,本文提出的智能体在性能和时间都要优于人工标注者。
更多实验细节请参考原文!
参考
- ^DAVIS Dataset http://davischallenge.org/
- ^DAVIS 2018 https://arxiv.org/abs/1905.00737