[CVPR2018笔记]Discriminative Learning of Latent Features for Zero-Shot Recognition

CVPR 2018 ORAL
zero-shot learning的解释可以详情见郑哲东在知乎中的回答,就是寻求将学习到的特征映射到另一个空间中,从而map到seen及unseen的属性或者label上
这篇文章的主要亮点在于学习了已定义label的同时,学习了latent attribute(隐含属性)。
已有方案的drawbacks:
1,在映射前,应当抽取image的feature,传统的用pretrain model等仍不是针对zero-shot learning (ZSL)特定抽取特征的最优解。
2,现有的都是学习user-defined attribute,而忽略了latent representation
3,low-level信息和的空间是分离训练的,没有大一统的framework
本文便是对应着解决了以上问题。
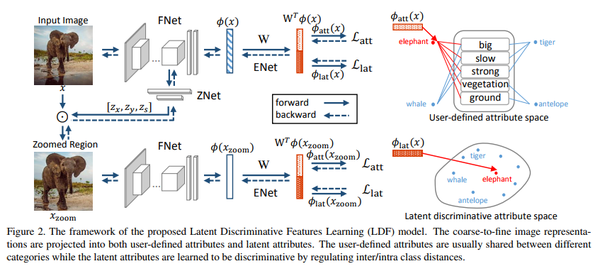

notation:
FNet:抽取img的feature;
ZNet: 定位最discriminative的区域并将其放大
ENet: 将img feature映射到另一个空间
下面我们先介绍各个子网络
FNet(The Image Feature Network)
这部分直接借用了已有的VGG19、GoogleNet,不细讲
ZNet(The Zoom Network)
这里的目的是定位到能够增强我们提取的特征的辨识度的region,这个region同时也要与某一个我们已经定义好了的attribute对应。
ZNet的输入是FNet最后一个卷积层的输出。
在这里运用某个已有的激活函数方法,将我们定位好了的region提取出来,即将crop操作在网络中直接实现。
然后,将ZNet的输出与original img做element-wise的乘法,最后,将region zoom到与original img相同的尺寸。
如图,再讲该输出输入到另一个FNet(第一个Fnet的copy)
ENet(The Embedding Network)
这里作者提出了一个score用于衡量img feature和attribute space的相似性(兼容性)


Enet将img feature映射到2k dim的空间中,1k是对应于已经定义了的label,并用softmax loss。
另1k则是对应潜藏属性,为了使这些特征discriminative,作者使用了triplet loss。
