
旷视提出纯基于 Transformer 的 2D HPE 模型:TokenPose,参数少、成本低、性能优

#姿态估计#
TokenPose: Learning Keypoint Tokens for Human Pose Estimation
在本次研究中,作者对混合和纯粹的基于 Transformer 的架构都进行了探索。提出 TokenPose-T 是一个纯基于 Transformer 的 2D 人体姿态估计模型。
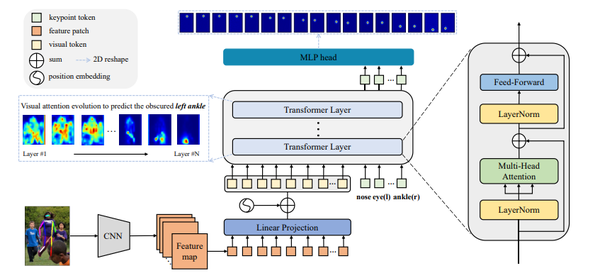

用 tokens 表示每个关键点实体,可以明确地将视觉线索学习和约束线索学习纳入到一个统一的框架中。
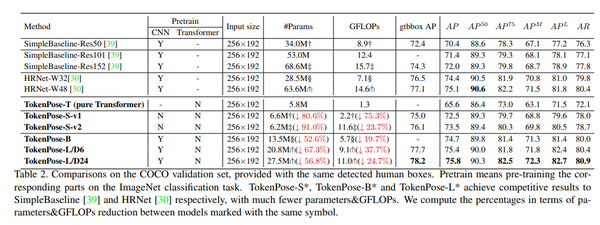
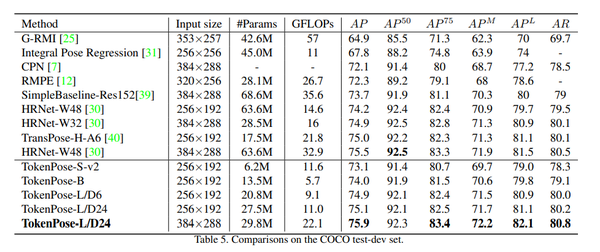
在两个经常使用的基准数据集:COCO 关键点检测数据集和 MPII 人体姿势数据集上进行了实验,结果表明 TokenPose 与现有基于 CNN 的同类产品相比,以更少的参数和计算成本实现了具有竞争力的最先进性能。
例如,TokenPose-S 和 TokenPose-L 在 COCO 验证数据集上分别实现了 72.5 AP 和 75.8 AP,参数显著降低 (↓80.6%;↓56.8%),GFLOPs(↓75.3%;↓24.7%)。


作者 | Yanjie Li, Shoukui Zhang, Zhicheng Wang, Sen Yang, Wankou Yang, Shu-Tao Xia, Erjin Zhou
单位 | 旷视;清华;东南大学;鹏城实验室
编辑于 2021-04-09 16:52
