
论文解读:如何毫无违和感地把美队盾牌放在罗马士兵手中

论文地址:https://arxiv.org/abs/1804.03189
论文代码地址:https://github.com/luanfujun/deep-painterly-harmonization
0.先睹为快——人工智能 P 图竟然毫无违和感
下面这些图片是人工智能算法 p 图的结果,从左到右三张图分别是原图、新增元素、机器输出结果:
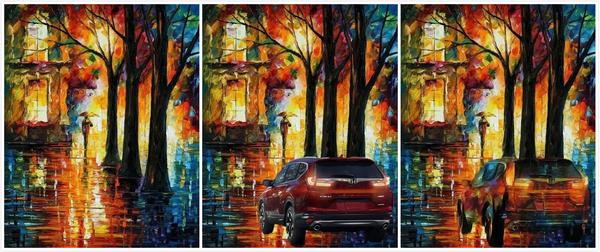





1.引言——当罗马士兵拿起美国队长的盾牌
在日常生活中,p 个图可能是一件很简单的事,大部分时候只需要进行抠图,然后复制粘贴即可,复杂一点的可能还需要进行其他的各种操作,这些操作使用 PS 基本都可以完成。但是如果我让你给 p 一幅图呢,你能做到吗?想想都很有难度的样子。不信我们举一个例子,我们给下面这位勇猛的古代展示 p 个图,让他像美国队长那般帅气地拿个盾牌。


对于像我这样一个不怎么会 p 图的人来说,就会复制粘贴,就会得到下图(左)所示的结果,但是对于一些大神,他们可能会得到更好的结果,如右图所示:


但是对于本文中的作者,大神中的大神,他得到的结果如下所示:

是不是毫无违和感?根本看不出来那个盾牌是后期 p 上的。点击论文的代码链接,访问作者的 GitHub 网址,你会发现更多神奇的操作。下面我们简单介绍一下作者是如何实现这种神奇的操作。
这里给出两幅大神操作图,左边的代表原图,中间的代表直接复制粘贴的图,右边的代表处理之后的图。




2.VGG 网络结构简介
这篇论文所使用的神经网络,源于一种名为 VGG 的网络架构。
VGG 由牛津大学的 Visual Geometry Group 提出,故而得名。在正式介绍前,我们简单的了解一下什么是 VGG 网络及其网络架构。
VGG 网络是 ILSVRC 2014 年竞赛的第二名,其 top-5 的准确率达到了 7.3%,第一名的 GoogleNet 的 top-5 的准确率打到了 7%。其网络结构总体来说与 LeNet 结构相同,但是有两点重要的不同:
1、网络变得更深,达到了 16-19 层,这也反应了一个事实,那就是网络越深,其表达能力越强。
2、网络中只使用了小型的卷积核模板,主要使用的是 3*3 的卷积模板,没出现像 AlexNet 中 11*11 那样大的卷积模板。模板变小,意味着网络参数的减少。
VGG 网络结构如下图所示:
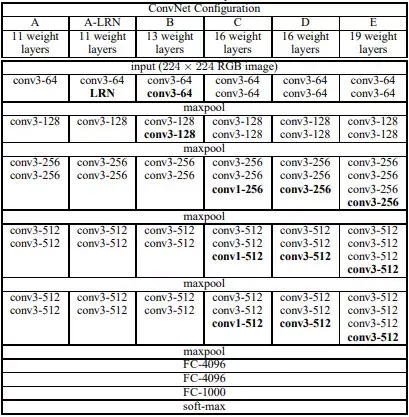
上图中展现了 A-E 几种不同的 VGG 网络结构,可以看到其总体的结构都是: 卷积+池化+全链接。VGG-19(E 模型) 就是我们本文介绍的论文中所使用的神经网络结构。
3.神经网络 P 图,已经做了多年
正所谓长江后浪推前浪(前浪死在沙滩上),本文作者能够达到这样一个高度,一部分是因为他站在了巨人的肩膀上。
本文中使用的技术叫做:深度绘画协调(Deep Painterly Harmonization),这也是这篇文章的标题。在过去的二十年里,图像协调技术(Image Harmonization)一直在快速的发展,我们可以将其理解为:将多张图片毫无违和感地拼接在一起。但是以往主要的手段都是研究人员,自己设定一个或者多个统计参数,例如:图片的亮度,图片的色温,图片的直方图特征等等,通过一定的手段使得不同图片中的参数结果尽量相同,从而达到了将图片“完美”拼接的目的。但是结果显然不尽如人意。为什么呢?
1、不同的图像风格可能对应不同的统计量,没有普适性,适用于这样风格图像的统计量可能并不适用于另一风格的图像。
2、统计量可以理解为全局特征,它反映的是整幅图片的风格。但是我们拼接的过程中,可能更注重的是拼接处的局部特征。
从 2012 年起,神经网络在图像分类和处理领域大放光彩,各种各样的神经网络架构脱颖而出,为整个图像领域注入了新鲜的血液。很多以前不能处理或者处理不好的领域,神经网络都展现了其强大的能力,特别是图像的识别领域。
在 2016 年 CVPR 会议上,Gatys 等大神就提出了使用神经网络来进行对图像进行风格转移,将一副图像的风格转移到另一幅图像上。正所谓,无图无真相,大家可以看看下面的结果图:


A 图是原图, B, C, D 分别是处理后的图像,每一幅图的左下角的图片,是我们欲学习的风格图。
4.核心技术:两步实现画面协调
结合 Gatys 的工作和其他研究人员的奋斗结果,为了实现基于绘画的 PS 神技,本文作者创造性的提出了“两步走”的战略思想。你可能要问,为什么要分两步呢?我个人猜测作者的灵感来自我国社会主义现代化建设“三步走”的战略(瞎猜的~)。当然,作者并不承认,作者的解释是因为一步走效果不好,所以就两步走了呗。
1、先产生一个中间结果,这个中间结果的效果比较比较接近最终目标,主要是在绘画的风格进行修改,使得我们想要粘贴的的图像的风格与原画相似。在这一步,主要的任务是风格的相似,不过于注重细节,从而使得整个网络结构具有更强的鲁棒性,对不同的风格图像都能进行相应的处理。
2、基于第一步的中间结果,我们进一步修改图片的质量,使得图片在视觉上效果更佳。在这一步中,我们更佳注重局部纹理信息。
上述两步可以使用如下的伪代码表示(摘自原文):
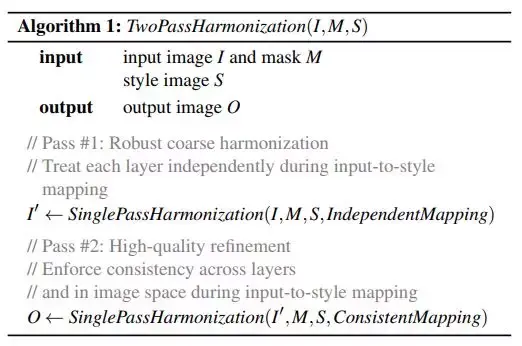

其中:
I 为输入图像,例如美国队长的盾牌;
S 为我们风格画作,例如那个勇士;
M 是模板,用来控制生成图片时, 每一个像素点应该由其周围的几个像素点构成,相当于起到一个局部化的作用。
我们通过一步处理,得到一个中间结果 I' ,然后在经过进一步的处理,得到最终的输出结果O。
其中 SinglePassHarmonization 的实现逻辑如下:


其中 ComputeNeuralActivations(I) 代表了当输入时 I 的时候, VGG 网络的输出。此输出并不是指 VGG 网络最后通过全链接网络的输出,而是指每一层卷积得到的特征图。通过输入图像的特征图与风格图像的特征图,我们对其进行匹配,然后重构出一张输出图片。
5.第一步: 粗协调
这一步的目的正如上述所说,用于对我们的输入图片 I 进行分风格上的改变,是指更加接近于我们的风格图像 S。如何做到这一点呢? 本文中使用的就是我们前面介绍的 VGG 网络。网络每个卷积层的输入都以代表原始图像的特征。

上图代表了 VGG 网络中的卷积层与 pool 层结构,对应于第二节 VGG 网络结构中的 E 结构。前两层的结构中,每一层有两个卷积层,例如 conv1_2 代表第一层卷积的第二层; conv2_1 则代表了第二层卷积的第一层。后面三层结构中,每一层都有四层卷积。例如 conv4_2 代表了第四层卷积的第二层。
在我们对输入图像 I 和风格图像 S 分别经过神经网络得到 F(I) 和 F(S) 之后,如上一节的算法2所示,我们对其进行匹配,匹配的算法过程如下所示:
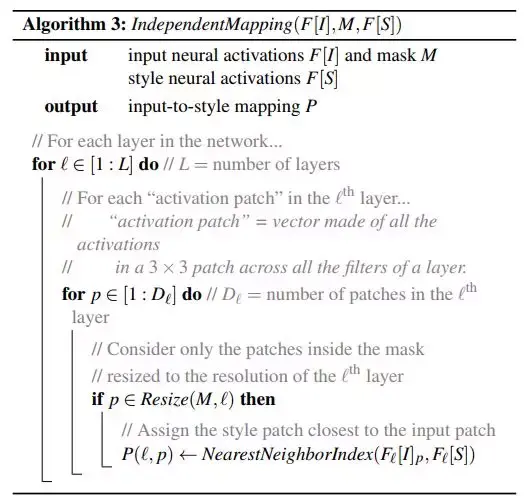

对于F(I) 中的每一层的每一个像素点,我们都会建立一个 P(l,p) 的映射关系,将其对应到每一层的 F(S) ,然后得到最终的映射关系 P。通过此映射关系,并基于 Gram 矩阵和 Gatys 损失函数我们可以重新构建出粗协调后的图像。
Gatys 损失函数的计算公式如下:
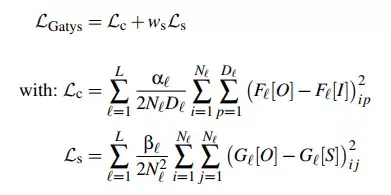
其中:
L 代表总共有多少卷积层;Nl 代表了第 l 层的卷积核个数;Dl 代表了在第 l 层有多少激活值;Fl[~] 是一个矩阵,其 (i,p) 位置的元素代表了第 l 层中,第 i 个卷积核中的第 p 个激活值;Gl = Fl Fl.T 代表了 Gram 矩阵。

第一列图像就是我们直接复制粘贴的结果,第二列图像是通过第一步粗协调后得到的结果,可以看到,虽然存在一些细节问题,但是整体的画风已经转变过来了。下面第二步,其主要任务就是解决这些线条不流畅,存起离群像素点问题,从而使得整体的视觉效果更佳。
6.第二步:优化改进
第二步中,我们同样要进行匹配,方法基本与算法 3 中所示的一致,唯一的不同之处在于,我们并不是对 F(I) 的所有层都进行匹配,我们只选择一层,我们选择第 lref,我们对这一层的特征图进行一个匹配,最终得到一个匹配关系 P(lref, p) 。接下来对此单层的匹配关系进行记忆不得处理,删除离群点,使得图像的在空间上更加具有一致性。之后呢,就把从这一层得到的匹配关系,赋值给其他各层,得到最终的 P(l, p)。
在得到此映射关系后,我们需要重构出输出图像。因为我们映射关系的 P(l, p) 的获取方法与第一步有所不同,所以其对应的 Gatys 损失函数也有所不同,除此之外,我们还需加上其他两项损失函数,来构造我们最终的损失函数,如下所示:
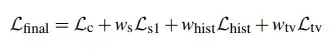
其中:

代表变形后的 Gatys 损失函数。

代表了由于图像模糊带来的损失,
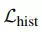
代表了直方图损失。
现在,问题来了,我们应该选择第几层的特征图片呢?在实际中可以根据自己的情况而定。在本文中,作者对比了不同层得到的结果,最终选择的是 conv4_1。


7.后续处理
虽然上述的“两步走”战略思想已经非常的成功了,我们人眼看上去看不出来很大的瑕疵,但是一件精美的艺术品是要经得住推敲的,当我仔细查看我们所得到的图片后,还是有很多细节值得改善的。
色度去噪 Chrominance Denoising
试验中发现,一些高频的噪声点会对色彩空间的影响较大,但是对图像的亮度却没有很大的影响。于是花,很自然的一种想法就是转换颜色空间,将 RGB 颜色空间转化为 Lab 颜色空间,然后对 a 方向和 b 方向进行滤波处理。这种方法可以处理一下较小的离群点,但是对于较大的离群点,没办法滤除。
块化合成 Patch Synthesis
在之前的每一步最后的图像重建过程中,我们是将所得的所有块化图像,相加平均,但是这样做的话很容易将图像的细节变得模糊。我们想的变法就是将没一个块化图像都分为卡通部分(低频信息)和纹理部分(高频信息)。然后我们只对卡通部分就行相加平均,得到的结果在加上纹理部分,即我们对纹理部分不进行平均,最终得到的结果,其细节部分将不会被模糊掉。


8.小结
在本篇文章中我们介绍了一种适用于绘画的“PS 技术”。主要的流程分为两步,第一步,首先将我们将绘画风格应用到我们的输入图像中,是指与绘画图像大致一致。在第二步中,我们更佳关注于细节的信息,对选择单一的一层特征图像,进行去噪处理,使得图像的整体视觉效果更佳理想。
最后,让我们一起来欣赏几幅机器 P 出的图:






关注集智AI学园公众号
获取更多更有趣的AI教程吧!
搜索微信公众号:swarm
AI集智AI学园QQ群:426390994
学园网站:http://campus.swarma.org
http://weixin.qq.com/r/FzpGXp3ElMDrrdk9928F (二维码自动识别)
商务合作|zhangqian@swarma.org
投稿转载|wangjiannan@swarma.org