
IJCAI-18 阿里妈妈搜索广告转化预测总结( 29 / 0.13939 )

数据下载链接:链接:https://pan.baidu.com/s/1aRTPrfk3fqR-pyuAAlsvbA 密码:2mz7
github链接:bettenW/IJCAI18_Tianchi_Rank29
队名“去网吧里偷耳机”
前后两个半月的奋战告一段落,这次也是我第一个从始至终参与的比赛.中间不仅经历了排名跌宕起伏的刺激,而且结识很多大佬,从中学习比赛的经验.更重要的是有队友的团队协作,不再是单打独斗,思维局限。感谢队友的骚套路。
接下来奉上此次比赛完全方案,干货满满!!
本文内容:
- 赛题分析
- 特征构造
- 特征选择
- 模型选择与评估
- 最终融合
- 不足与总结
1.赛题分析
比赛题目是"搜索广告转化预测",需要通过人工智能技术构建预测模型预估用户的购买意向,即给定历史广告点击相关的用户(user)、广告商品(ad)、检索词(query)、上下文内容(context)、商店(shop)等五类信息的条件下预测接下来日期广告产生购买行为的概率(pCVR).
结合淘宝平台的业务场景和不同的流量特点,官方定义了以下两类挑战:
(1)日常的转化率预估
(2)特殊日期的转化率预
grouped_df = train.groupby(["day", "hour"])["is_trade"].aggregate("mean").reset_index()
grouped_df = grouped_df.pivot('day', 'hour', 'is_trade')
plt.figure(figsize=(12,6))
sns.heatmap(grouped_df)
plt.title("CVR of Day Vs Hour")
plt.show()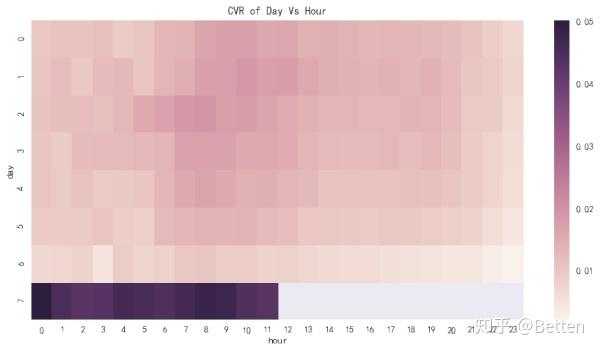

从图中可以看出7号的转化率高出平日一大截,据此推断7号为双十一。所以复赛较初赛而言得改变策略。
1.1 评估指标
通过logarithmic loss(记为logloss)评估模型效果(越小越好), 公式如下:


其中N表示测试集样本数量, y_i 表示测试集中第i个样本的真实标签, p_i 表示第i个样本的预估转化率。这类评估函数常用logloss和AUC,简单的说logloss更关注和观察数据的吻合程度,AUC更关注rank order.
1.2 相关比赛
在此之前有过多场类似比赛,都可以帮助选手迅速了解比赛,同时学到更多的思路方案.
kaggle:outbrain click prediction
kaggle:Display Advertising Challenge
kaggle Click-ThroughRate Prediction
腾讯社交广告大赛
天池优惠券使用预测
TalkingData AdTracking Fraud Detection Challenge
2.特征构造
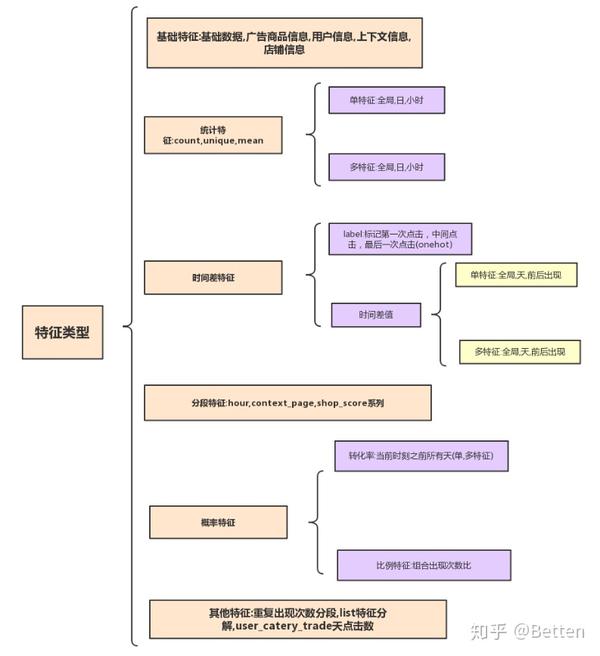
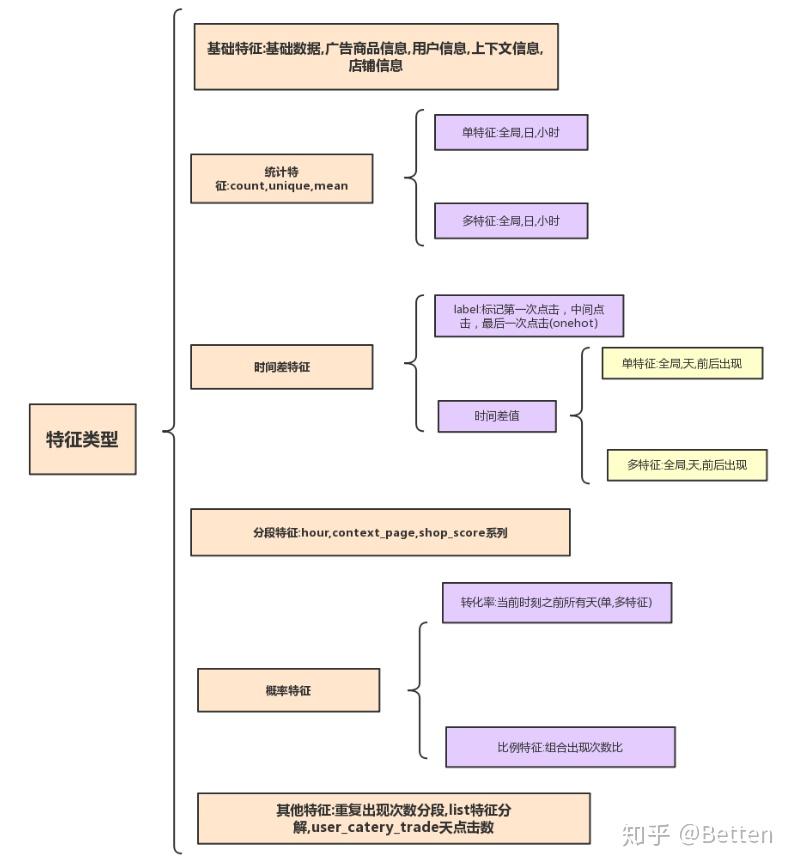
2.1基础特征
官方提供的原始特征(基础数据、广告商品信息、用户信息、上下文信息和店铺信息),其中context_tiemstamp取值是以秒为单位的Unix时间戳,需要对其进行转化.三个list特征也是需要进行预处理的.
# time
data['time'] = pd.to_datetime(data.context_timestamp, unit='s')
# list
data_item_category = data.item_category_list.str.split(';', expand=True).add_prefix('item_category_')
data_item_property = data.item_property_list.str.split(';', expand=True).add_prefix('item_property_')2.2统计特征
统计特征主要用到三种度量方式:count,unique,mean,分别从全局,天,小时三种时间粒度来构造.
2.3时间差特征
时间差特征在这次比赛中也算是trick的存在,从用户点击商品的时间差来反映用户购买商品的可能性,短时间内点击相同商品购买的可能性会比较大.我们分别:
- 从单特征,多特征进行组合构造
- 从全局,天统计首次点击与当前点击的时间差,最后次点击与当前点击的时间差
- 上一次点击和下一次点击与当前点击的时间差.
根据这种时间差特征,我们还能构造了先后点击标记特征,用户点击商品无非三个位置,首次点击,中间点击和末次点击,可以设想我们浏览电商网站,往往最后一次浏览购买可能性最大.
subset = ['user_id', 'day']
# 标记点击位置特征
data['click_user_lab'] = 0
pos = data.duplicated(subset=subset, keep=False)
data.loc[pos, 'click_user_lab'] = 1
pos = (~data.duplicated(subset=subset, keep='first')) & data.duplicated(subset=subset, keep=False)
data.loc[pos, 'click_user_lab'] = 2
pos = (~data.duplicated(subset=subset, keep='last')) & data.duplicated(subset=subset, keep=False)
data.loc[pos, 'click_user_lab'] = 3
# 构造时间差特征
subset = ['user_id', 'day']
temp = data.loc[:,['context_timestamp', 'user_id', 'day']].drop_duplicates(subset=subset, keep='first')
temp.rename(columns={'context_timestamp': 'u_day_diffTime_first'}, inplace=True)
data = pd.merge(data, temp, how='left', on=subset)
data['u_day_diffTime_first'] = data['context_timestamp'] - data['u_day_diffTime_first']
temp = data.loc[:,['context_timestamp', 'user_id', 'day']].drop_duplicates(subset=subset, keep='last')
temp.rename(columns={'context_timestamp': 'u_day_diffTime_last'}, inplace=True)
data = pd.merge(data, temp, how='left', on=subset)
data['u_day_diffTime_last'] = data['u_day_diffTime_last'] - data['context_timestamp']
data.loc[~data.duplicated(subset=subset, keep=False), ['u_day_diffTime_first', 'u_day_diffTime_last']] = -1上面代码我们构造了同一天内,用户点击位置的标记,以及首次末次与当前时刻的时间差。
# 帮助方便的获取相同样本的首条
data.duplicated(subset=subset, keep='first')2.4分段特征
分段特征主要是对小时,score,rate进行构造,这类离散化后的特征对异常数据有很强的鲁棒性,刻画出用户习惯操作和偏好。
2.5概率特征
概率特征我们主要构造了转化率特征和比例特征,其中转化率特征主要统计的是历史转化率,一是刻画转化率的变化情况,二是反应某个特征大概转化情况,特征我们进行了单特征和多特征组合构造转化率特征。比例特征用来刻画某类用户的偏好。
2.6其他特征
另外还有一些特征有很大表现能力,在数据集中发现存在很多用户在同一时间下进行多次点击,我们统计其出现次数(same_time_expo_cnt)。用户对相同商品点击次数对于次数大于2的进行标记(user_large2)。深入业务我们对predict_category_property进行了挖局,由于用户搜索某商品时显示预测的类别属性影响着用户点击情况,所以我们构造了预测类别属性与用户点击商品类别属性的交集个数与相似度。
def split_category(x,index):
tmp = []
for a in x:
tmp.append(a.split(':',1)[index])
return tmp
def split_property(x):
tmp = []
for a in x:
tmp.extend(a.split(',',a.count(",")))
return tmp
def check_same(a,b):
set_same = a & b
return list(set_same)
def do_list_feat(data):
# 逐步切分预测类别特征
data['predict_category_list'] = data['predict_category_property'].apply(lambda x:x.split(';',x.count(';')))
data['predict_category'] = data['predict_category_list'].apply(lambda x:split_category(x,0))
data['predict_category'] = data['predict_category'].apply(lambda x:set(x))
## 切分广告商品类别特征
data['item_category'] = data['item_category_list'].apply(lambda x:x.split(';',x.count(';')))
data['item_category'] = data['item_category'].apply(lambda x:set(x))
## 筛出商品类别和预测类别的交集
data['same_category_list'] = list(map(check_same,data['predict_category'], data['item_category']))
## 计算预测类别和广告商品类别的相似程度
data['same_category_num'] = data['same_category_list'].apply(lambda x:len(x))
data['predict_category_num'] = data['predict_category'].apply(lambda x:len(x))
data['same_category_prob'] = round(data['same_category_num']/data['predict_category_num'], 5)
## 逐步切分预测属性特征
data['predict_property'] = data['predict_category_list'].apply(lambda x:split_category(x,-1))
data['predict_property'] = data['predict_property'].apply(lambda x:split_property(x))
data['predict_property']= data['predict_property'].apply(lambda x:set(x))
## 切分广告商品属性特征
data['item_property'] = data['item_property_list'].apply(lambda x:x.split(';',x.count(';')))
data['item_property'] = data['item_property'].apply(lambda x:set(x))
## 筛出商品属类别和预测类别的交集
data['same_property_list'] = list(map(check_same,data['predict_property'], data['item_property']))
## 计算预测属性和广告商品属性的相似程度
data['same_property_num'] = data['same_property_list'].apply(lambda x:len(x))
data['predict_property_num'] = data['predict_property'].apply(lambda x:len(x))
data['same_property_prob'] = round(data['same_property_num']/data['predict_property_num'], 5)
return data3.特征选择
首先推荐一篇有关特征选择的文章
https://zhuanlan.zhihu.com/p/32749489
可以想象经过上述构造特征的过程能够上到数百个特征,但是我们又不可能对所有特征进行训练,因为里面可能包含很多冗余特征,同时我们需要在少特征的情况下达到多特征的效果(奥卡姆剃刀原理)。最常用的方法是相关系数法以及模型输出特征重要性的方法。
# lgbm输出特征重要性
lgb_clf = lgb.LGBMClassifier(objective='binary',num_leaves=35,max_depth=6,learning_rate=0.05,seed=2018,
colsample_bytree=0.8,subsample=0.9,n_estimators=20000)
lgb_model = lgb_clf.fit(train_x[features], train_x[target], eval_set=[(test_x[features], test_x[target])], early_stopping_rounds=200)
lgb_predictors = [i for i in train_x[features].columns]
lgb_feat_imp = pd.Series(lgb_model.feature_importances_, lgb_predictors).sort_values(ascending=False)
lgb_feat_imp.to_csv('lgb_feat_imp.csv')然而特征重要性的结果并不是很可靠,也不能反应特征相互组合对logloss的影响。故我们使用warpper的方式来进行特征选择。将前向搜索、后向搜索和随机搜索进行组合筛选出最终特征。
- 前向搜索
前向搜索说白了就是每次增量地从剩余未选中的特征选出一个加入特征集中,待达到阈值或者 n 时,从所有的 F 中选出错误率最小的。过程如下:
- 初始化特征集 F 为空。
- 扫描 i 从 1 到 n
如果第 i 个特征不在 F 中,那么特征 i 和F 放在一起作为 F_i (即 F_i=F\cup\{i\} )。
在只使用 F_i 中特征的情况下,利用交叉验证来得到 F_i 的错误率。 - 从上步中得到的 n 个 F_i 中选出错误率最小的 F_i ,更新 F 为 F_i 。
- 如果 F 中的特征数达到了 n 或者预定的阈值(如果有的话),
那么输出整个搜索过程中最好的 ;若没达到,则转到 2,继续扫描。
- 后向搜索
既然有增量加,那么也会有增量减,后者称为后向搜索。先将 F 设置为 \{1,2,...,n\} ,然后每次删除一个特征,并评价,直到达到阈值或者为空,然后选择最佳的 F 。
我们在此基础上还可以进行扩展,因为这种方式会导致局部最优,所以加入了模拟退火方式进行改善,不会因为新加入特征不能降低logloss而舍弃它,而是对此特征添加一个权重放入已选特征集。当然还有更加精细的方法,不过会耗费大量时间,下面给出更为精细的方法。
https://github.com/duxuhao/Feature-Selection?spm=5176.9876270.0.0.50902ef1upaZoy
4.模型训练与评估
4.1模型选择
此次比赛中我们尝试了多种模型,其中包含lgb,xgboost,deepfm,wide&deep,ffm等模型。但最后只用了lgb和xgb
4.2交叉验证
由于比赛每天只有一次评测机会,所以线下验证由为重要,另外初赛复赛场景不同。初赛我们用最后一天作为验证集,其余作为训练集。复赛需要预测特殊日期的转化率,由于7号和之前差异比较大,所以用七号上半天进行训练,选用最后俩个小时作为验证集。
5.最终融合
在此阶段我们尝试了多种方案,普通加权,Stacking,加权平均结合sigmoid反函数
5.1普通加权
这种方法更适合模型结果差异性较大,线上效果好的权重较大些,线上效果好的权重相对大些,反之权重相对小些。
5.2Stacking
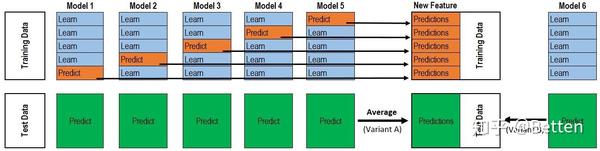

该图是一个基模型得到P1和T1的过程,采用的是5折交叉验证,所以循环了5次,拼接得到P1,测试集预测了5次,取平均得到T1。而这仅仅只是第二层输入的一列/一个特征,并不是整个训练集。再分析作者的代码也就很清楚了。也就是刚刚提到的两层循环。
5.3加权平均结合sigmoid反函数


首先将各个模型的结果代入到sigmoid反函数中,然后得到其均值,对其结果使用sigmoid函数。相较于普通的加权平均,这种方法更适合于结果具有较小差异性的。
def f(x):
res=1/(1+np.e**(-x))
return res
def f_ver(x):
res=np.log(x/(1-x))
return res经过队内讨论后,使用stacking结合sigmoid反函数的方法进行融合。用多个模型的结果作为新的特征进行训练,然后利用不同折数加参数,特征,样本(随机数种子)扰动,再使用加权平均结合sigmoid反函数得到最终成绩。
skf=list(StratifiedKFold(y_loc_train, n_folds=10, shuffle=True, random_state=1024))
for i, (train, test) in enumerate(skf):
print("Fold", i)
model.fit(X_loc_train[train], y_loc_train[train], eval_metric='logloss',/
eval_set=[(X_loc_train[train], y_loc_train[train]), (X_loc_train[test], /
y_loc_train[test])],early_stopping_rounds=100)
test_pred= model.predict_proba(X_loc_test, num_iteration=-1)[:, 1]
print('test mean:', test_pred.mean())
res['prob_%s' % str(i)] = test_pred
for i in range(10):
res['predicted_score'] += res['prob_%s' % str(i)].apply(lambda x: math.log(x/(1-x)))
res['predicted_score'] = (res['predicted_score']/10).apply(lambda x: 1/(1+math.exp(-x)))6.不足与总结
比赛中,最让我头疼的就是数据太大,没有服务器跑代码,多亏一位外校的师兄借服务器使用,不然很难达到这个成绩,虽然只能12点后使用。
模型最后阶段能用的不多,尤其是nn方面一直没有达到满意的效果,最后只能lgb和xgb融合。
当热这次比赛也学到很多东西,尝试了各种特征工程,模型调参,模型融合的方法,从队友那里总能获得新思路。相信下次比赛能够学到更多知识。
参考文献:
https://www.csie.ntu.edu.tw/~r01922136/slides/kaggle-avazu.pdf
https://www.csie.ntu.edu.tw/~cjlin/papers/ffm.pdf
[1701.04099] Field-aware Factorization Machines in a Real-world Online Advertising System
写在最后
知乎专栏目的传播更多机器学习干货,数据竞赛方法。欢迎投稿!
路漫漫其修远兮,吾将上下而求索。


