
轻松掌握 MMDetection 中常用算法(七):CenterNet


文@000007
0 摘要
在大家的千呼万唤中,MMDetection 支持 CenterNet 了!!
CenterNet 全称为 Objects as Points,因其极其简单优雅的设计、任务扩展性强、高速的推理速度、有竞争力的精度以及无需 NMS 后处理等优点,受到了用户广泛的关注,从官方仓库 xingyizhou/CenterNet 的 5.5k star 可见其受欢迎程度。既然叫做 CenterNet,那么其最大亮点就是提出了一种强任务扩展的框架,可以将大部分任务都归纳为预测中心+基于中心点的偏移属性,例如目标检测是中心点+基于中心点的宽高属性偏移;关键点检测是中心点+基于中心点的人体关键点偏移预测等等。
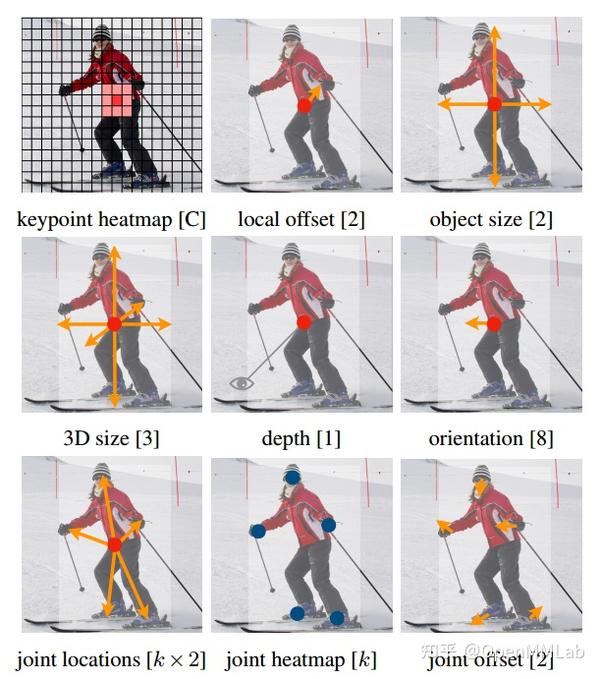

除了上述所提通用做法,其还是一个速度和精度平衡,anchor-free 算法,由于其简单的设计思想、无需NMS、无需复杂的FPN结构、超参少的特点,在很多对速度有要求或者比赛中都有采用,也比较容易部署,应用非常广泛的。
项目地址:https://github.com/open-mmlab/mmdetection
欢迎 star~
1 算法核心实现
由于 CenterNet 比较出名,而且大部分源码都是基于 CornerNet,故本文不进行详细分析。对于目标检测而言,其输出主要包括两条分支,一个是中心点 heatmap 回归分支;一个是基于中心点的宽高属性预测分支,为了提高中心点的预测精度,还引入了额外的 offset 回归分支,回归用于量化误差导致的中心点偏移,heatmap 和 offset 回归的做法参考自 CornerNet。
由于 MMDetection 中已经实现了 CornerNet,为了方便代码复用,在 CenterNet 复现中大量复用了相关代码,例如数据增强、后处理等等。
1.1 Backbone
考虑到 Hourglass-104 和 ResNet-101 等大模型的训练时间以及 DLANet 网络的复杂性,我们优先考虑采用 ResNet-18 作为复现的 base 模型(DLANet 由于结构的复杂性以及代码易读性,我们计划单独提一个新的 PR 进行复现,后续会发布),其配置为:
backbone=dict(
type='ResNet', depth=18, norm_eval=False, norm_cfg=dict(type='BN')) 需要特别注意:由于 ResNet-18 模型比较小,而且 CenterNet 训练 epoch 非常长为140,所以最好是所有 BN 层都参与训练,故修改更改默认设置为 norm_eval=False。
1.2 Neck
为了代码解耦,我们将 CenterNet 模型也切分出了 Neck 模块,对应模型是 `CTResNetNeck`,主要完成上采样操作。
neck=dict(
type='CTResNetNeck',
in_channel=512,
num_deconv_filters=(256, 128, 64),
num_deconv_kernels=(4, 4, 4),
use_dcn=True), 由于输入和输出特征图是相差 4 倍,ResNet-18 输出特征图最大是下采样 32 倍,故需要上采样 3 次。
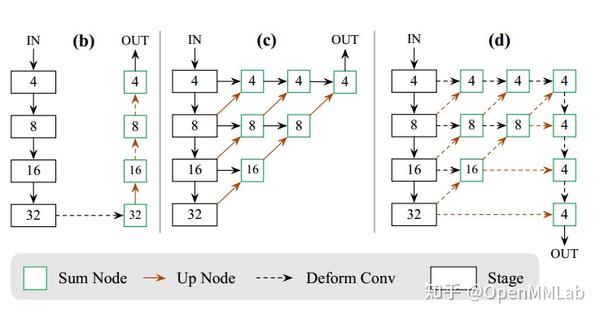

(b) 即为以 ResNet 为 backbone 的网络结构,(d) 是以 DLANet 为 backbone 的 CenterNet 网络结构(实际上 d 图和代码是对不上的,OUT 输出来自倒数第二层上采样输出,而不是上图中的倒数第一层)
为了提高性能,作者在上采样模块中引入了可变形卷积,实现结果表明提升了较多性能(从 26.0 提升到29.5),而且上采样模块是可学习的转置卷积,而非常用的双线性上采样模块。
layers = []
for i in range(len(num_deconv_filters)):
feat_channel = num_deconv_filters[i]
conv_module = ConvModule(
self.in_channel,
feat_channel,
3,
padding=1,
conv_cfg=dict(type='DCNv2') if self.use_dcn else None,
norm_cfg=dict(type='BN'))
layers.append(conv_module)
upsample_module = ConvModule(
feat_channel,
feat_channel,
num_deconv_kernels[i],
stride=2,
padding=1,
conv_cfg=dict(type='deconv'), # 转置卷积
norm_cfg=dict(type='BN'))
layers.append(upsample_module)
self.in_channel = feat_channel
return nn.Sequential(*layers) 需要注意一个细节:
if isinstance(m, nn.ConvTranspose2d):
# 采用 ConvTranspose2d 默认初始化方法
m.reset_parameters()
# 模拟双线性上采样 kernel 初始化
w = m.weight.data
f = math.ceil(w.size(2) / 2)
c = (2 * f - 1 - f % 2) / (2. * f)
for i in range(w.size(2)):
for j in range(w.size(3)):
w[0, 0, i, j] = \
(1 - math.fabs(i / f - c)) * (
1 - math.fabs(j / f - c))
for c in range(1, w.size(0)):
w[c, 0, :, :] = w[0, 0, :, :] 上述初始化过程非常复杂,实际上作者是希望 ConvTranspose2d 初始化时候能够提供类似双线性上采样层功能,故其初始化参数设置为了双线性上采样核,有助于收敛。而 `m.reset_parameters()` 存在的原因是 MMDetection 中的 `ConvModule` 会修改掉原始 ConvTranspose2d 层的初始化方式。
1.3 Head
拆解出 Neck 后,Head 模块就非常简单了,输出三个特征图,分别是高斯热图 (h/4, w/4, cls_nums),每个通道代表一个类别;宽高输出图 (h/4, w/4, 2),代表中心点距离左上边距值;中心点量化偏移图(h/4, w/4, 2):
def _build_head(self, in_channel, feat_channel, out_channel):
"""Build head for each branch."""
layer = nn.Sequential(
nn.Conv2d(in_channel, feat_channel, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(feat_channel, out_channel, kernel_size=1))
return layer 高斯热图和 offset 图分支的 target 和 loss 计算方式都是完全采用了 CornerNet 算法,故本文不再赘述,而宽高输出图和 offset 一样,采用常规的 L1Loss,并且宽高输出图和 offset 分支仅仅在 heatmap 中心点处才会计算 loss,其余地方全部忽略。
CenterNet 后处理流程和 CornerNet 几乎一致,除了有额外的宽高预测图分支外。以上就是 CenterNet 全部流程,下面重点分析在复现过程中发现的一些细节。
2 复现细节
2.1 收敛速度
CenterNet 虽然很好,但是收敛速度比较慢,和 RetinaNet 等模型相比收敛速度慢的太多了,常规算法都仅仅需要 12 epoch 就能得到比较好的结果,而 CenterNet 需要 140。这主要是因为其正样本太少了,宽高预测和 offset 预测分支仅仅在 gt bbox 中心才算 loss。在 COCO 数据集上,为了能够达到还不错的性能,作者采用了非常多的数据增强手段。
2.2 超参设置
因为 CenterNet 算法发布比较早且很实用,故基于源码也有很多更好的第三方复现,在阅读源码过程中以及参考第三方复现 https://github.com/FateScript/CenterNet-better,我们相应的对 CenterNet 超参进行了调整,细节如下:
- 修复了源码中预训练模型均值和方差错误问题。torchvision 发布的模型均值和方差实际上和源码发布的不一样
- 因为超长的训练时间以及参考现代目标检测优化器设置,我们直接采用了 SGD+Momentum+Warmup 优化器,而没有采用原始的 Adam,结果表明在 ResNet18,且含 DCNv2 模型上,SGD 跑出的性能是 29.7,而 Adam 是 29.1
- 分布式训练中采用了 DDP 模式,而非源码中的 DP
- 当训练过程中某个 batch 内没有 gt bbox,那么 heatmap 分支会输出比较大的 Loss,导致梯度激增,后续难以得到比较好的性能,为了稳定训练过程,我们额外引入了梯度裁剪
经过上述改进,最终训练出来的 CenterNet 性能会比源码高大概 1.7 个点。如果想知道更多性能对比结果,可以参考 https://github.com/open-mmlab/mmdetection/pull/4602 。
在小模型 ResNet18-DCNv2 上多次训练,我们发现性能其实还是不太稳定,最低出现过 29.4 mAP,最高出现过 29.9 mAP,波动如此大的原因可能有多方面:
- 小模型在出现 loss 波动大的情况下,后续很难稳定,特别是当 loss 波动出现在后期
- CenterNet 数据增强比较多,可能会出现极端场景而影响最终性能
2.3 其他细节
以 ResNet18-DCNv2 为例,在作者所提的 flip 多尺度测试中,和常规的做法不同,其是在特征图上面进行平均,而不是单图得到 bbox 后,统一进行 nms 操作。为此,我们在 `mmdet/models/detectors/centernet.py` 中特意重写了这部分逻辑。
而且比较奇怪的是,三个输出分支中,正常来说应该是都要进行特征图平均,但是实际上 offset 分支是没有进行平均操作的。
center_hm = (center_hm[0:1] + self.flip_tensor(center_hm[1:2])) / 2
wh_hm = (wh_hm[0:1] + self.flip_tensor(wh_hm[1:2])) / 2
offset_hm = offset_hm[0:1] 实际测试发现,如果 offset 也进行特征图平均操作,mAP 会降低 0.2。
不管是单尺度测试还是 flip 测试,都没有采用 nms,只在多尺度测试时候才用了 nms。实际上发现如果对 flip 也进行 nms 操作,最终性能可以由 31.0 提升到31.6。
快速指引:
OpenMMLab:轻松掌握 MMDetection 整体构建流程(一)
OpenMMLab:轻松掌握 MMDetection 整体构建流程(二)
OpenMMLab:轻松掌握 MMDetection 中 Head 流程
OpenMMLab:轻松掌握 MMDetection 中常用算法(一):RetinaNet 及配置详解
OpenMMLab:轻松掌握 MMDetection 中常用算法(二):Faster R-CNN|Mask R-CNN
OpenMMLab:轻松掌握 MMDetection 中常用算法(三):FCOS
OpenMMLab:轻松掌握 MMDetection 中常用算法(四):ATSS
OpenMMLab: 轻松掌握 MMDetection 中常用算法(五):Cascade R-CNN

