
名字有什么关系呢?玫瑰不叫玫瑰,依然芳香如故:深度学习花书前言(下)

继续总结深度学习花书第一章前言下半部分,主要内容有:
- 深度学习历史悠久,在不同时期名字不同,代表不同的侧重点。
- 由于训练数据的增多和软硬件性能的提高,深度学习的模型越来越准确。
- 深度学习逐渐走向实用化。
你的名字
莎士比亚说过:“名字有什么关系呢?玫瑰不叫玫瑰,依然芳香如故。”深度学习在历史上也曾有多个名字,深度学习的历史可以追溯到1940年代。
在1940-1960年间,人们更多的是从神经科学找灵感,希望能够搭建能够模拟人脑工作模式的神经网络,这个时期的名字是人工神经网络(Artificial Neural Network) 或神经机械学(cybernetics)。感知机模型(perceptron)也是这个时期的产物。这个时期的模型大部分都是线性模型,对于非线性的关系不能进行很好的模拟所以有很大的局限性,深度学习研究就逐渐降温了。不过,这个时期为后来的深度学习打下基础,我们现在训练常用的随机梯度下降算法(stochastic gradient descent)就是源自处理这个时期的一种线性模型——自适应线性单元(Adaptive Linear Neuron)。虽然现在仍有媒体经常将深度学习与神经科学类比,但是由于我们对大脑工作机制的研究进展缓慢,所以实际上现在深度学习从业者已很少从神经科学中寻找灵感。
第二个阶段是1980-1990年代,这个时候更多的称为联结主义(connectionism)或并行分布式计算(parallel distributed computing),主要是强调很多的简单的计算单位可以通过互联进行更复杂的计算。这个时期成果很多,比如现在常用的反向传播算法(back propagation)还有自然语言处理中常用的LSTM(第十章讲递归神经网络时详谈)都来自与这个时期。之后由于很多AI产品期望过高而又无法落地,研究热潮逐渐退去。
第三个阶段就是2006年至今,由于软硬件性能的提高,深度学习逐渐应用在各个领域,深度学习研究重整旗鼓。“深度”学习的名字成为主流,意在强调可以训练更多层次更复杂的神经网络,“深”帮助我们开发更复杂的模型,解决更复杂的问题。
韩信点兵,多多益善
深度学习为什么又重新火热起来了呢?
主要是由于两点原因:1.我们有更大量的数据进行训练 2.我们有更好的软硬件可以支持更复杂的模型。
先说数据大小,如果自己动手训练过深度学习模型的话就会体验到数据集大小对预测准确率影响很大,即使是同一个模型,训练量的大小不同会造成最终效果天差地别,统计学上,通过小量数据训练延展到新数据是很困难的。随着世界数字化的趋势大数据的发展,我们有更多被标注的数据集,深度学习模型的准确度也因此受益。下图是一些按年份排序的一些经典数据集的大小(如果接触过tensorflow教程的小伙伴应该对MNIST,ImageNet,CIFAR不陌生)
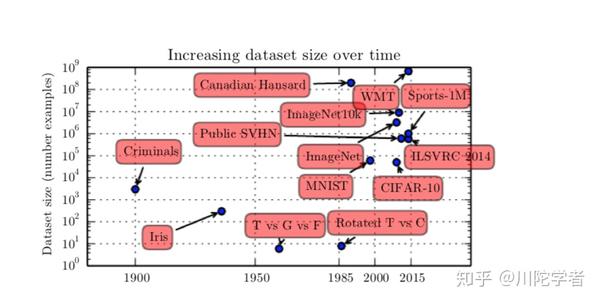
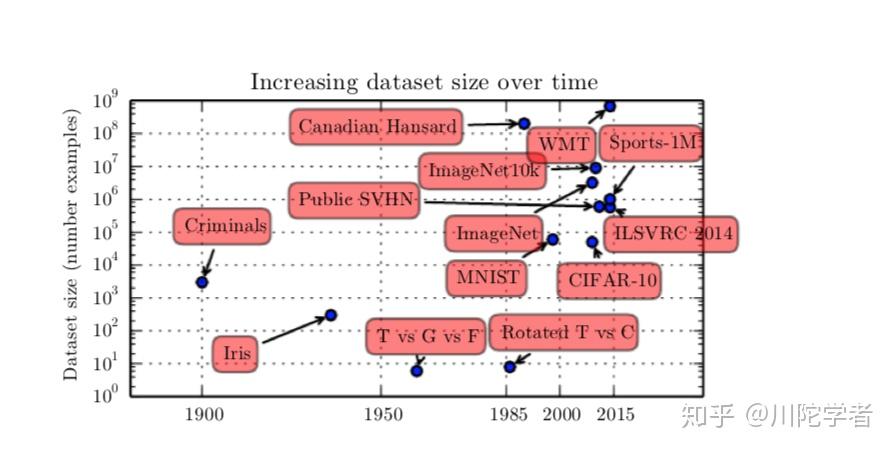
软硬件方面,由于更快的CPU,GPU的发展,更高速的网络传输,更好的分布式计算的软件支持,允许我们能打造更复杂的网络,模拟更复杂的逻辑,从而解决更复杂的问题。
梦想照进现实
随着模型准确度的提高,深度学习也逐渐得到更广泛的实际应用,比如图像识别,语音识别,机器翻译等领域。像DeepMind AlphaGo这种强化学习方面的应用更是掀起了全民AI热潮。与此同时,各种深度学习框架的出现如Caffe,Torch,Tensorflow等也方便更多人学习或利用深度学习模型。这些反过来又促进了深度学习行业的发展。
在一片繁荣下,深度学习的可解释性又常受诟病,对抗样本等的出现也让人思考深度学习的有效性,这都需要更多从业者去深入思考,而不能满足于黑箱成果,“路漫漫其修远兮,吾将上下而求索。”
前言部分总结完毕,可以大致对深度学习发展历程及要解决的问题有个大致了解,下次更新干货部分:基本功扎马步——深度学习花书第二章线性代数。
