Effective Approaches to Attention-based Neural Machine Translation 中英文对照翻译

中英文对照及完整版参见
Effective Approaches to Attention-based Neural Machine Translation
Minh-Thang Luong Hieu Pham Christopher D. Manning
Computer Science Department, Stanford University, Stanford, CA 94305
{lmthang,hyhieu,manning}@http://stanford.edu
摘要
通过在翻译过程中选择性地关注源句子的部分内容,attention 机制近来已被用于改进神经机器翻译(NMT)。 但是,探索基于attention 的 NMT 体系结构一直没有多少工作。 本文考察两种简单而有效的 attention 机制:一种始终关注所有源词的全局 方法和一种每次仅查看源词子集的局部 方法。 我们在英语和德语两个方向上展示两种方法在WMT翻译任务上的有效性。 在局部 attention 的情况下,我们获得比非 attention 系统高出5.0 BLEU点的显着效果,这些系统非 attention 系统已经结合 dropout 等已知技术。 我们使用不同 attention 架构的集成模型在WMT'15英语至德语翻译任务中获得最新的最佳成果,其中25.9 BLEU点数比现有由NMT和n-gram reranker 支持的最佳系统提高了1.0 BLEU点。1
1 介绍
神经机器翻译(NMT)在从英语到法语[Luong et al. 2015]和英语到德语[Jean et al. 2015]等大规模翻译任务中获得了最先进的表现。 NMT很吸引人,因为它需要最少的领域知识并且在概念上很简单。 Luong et al. 2015 的模型对所有源词进行读取,直到句尾符号<eos> 。 然后它开始每次生成一个目标单词,如图1所示。 NMT通常是一个大型的神经网络,它以端到端的方式进行训练,并且能够很好地推广到很长的单词序列。 这意味着模型不必像标准MT那样明确地存储巨大的短语表和语言模型;因此,NMT占用的内存很小。 最后,实现NMT解码器很容易,不像标准MT中的高度复杂的解码器[Koehn et al. 2003]。
图1: 神经网络机器翻译 — 用于将源序列A B C D翻译为目标序列X Y Z的堆叠循环体系结构。 这里,<eos> 标记句子的结尾。
与此同时,“attention”概念最近在训练神经网络中越来越受欢迎,允许模型学习不同模态之间的对齐,例如在动态控制问题中图像对象与代理动作之间的对齐[Mnih et al. 2014],在语音识别任务中的语音帧和文本之间[? ],或者在图像标题生成任务中图像的视觉特征与其的文本描述之间[Xu et al. 2015]。 在NMT的背景下,Bahdanau et al. 2015 已成功应用这种 attention 机制来联合翻译和对齐单词。 据我们所知,目前还没有任何其他工作正在探索使用基于 attention 的 NMT 架构。
在这项工作中,我们设计了两种新颖的基于attention 的模型:一种全局 方法,其中所有源词都被关注,一个局部 方法,其中一次只考虑源词的一个子集。 前一种方法类似于[Bahdanau et al. 2015]的模型,但体系结构更简单。 后者可以被看作是[Xu et al. 2015]提出的hard 和soft attention 模型之间有趣的混合: 它的计算成本比全局模型或soft attention 要低;与此同时,与hard attention不同,局部 attention 几乎在任何地方都是可微分的,这使得它更易于实现和训练。2 另外,我们还研究了我们的基于attention 模型的各种对齐函数。
在实验上,我们证明我们的两种方法在英文和德文的WMT翻译任务中都是有效的。 我们的 attention 模型比已经包含已知技术(例如dropout)的非attention 系统获得高达5.0 BLEU的提升。 对于英文到德文的翻译,我们实现了WMT'14和WMT'15的最佳(SOTA)结果,超过以前的由 NMT 模型和n-gram LM rerankers 支持的SOTA系统 1.0 BLEU。 我们在学习、处理长句的能力、attention 架构的选择,对齐质量和翻译输出进行广泛的分析以评估我们的模型。
2 神经网络机器翻译
神经网络机器翻译系统是一个直接建模条件概率p(y|x)的神经网络,将源语句x1,…,xn翻译到目标语句y1,…,ym。3 NMT的基本形式包括两个组成部分:(a) 编码器 计算每个源语句的表示s 和(b) 解码器 每次生成一个目标单词,因此条件概率可分解为:

解码器中建模这种概率分解的一个自然选择是循环神经网络(RNN)架构,目前大部分NMT工作如[Kalchbrenner and Blunsom 2013; Sutskever et al. 2014; Cho et al. 2014; Bahdanau et al. 2015; Luong et al. 2015; Jean et al. 2015]都这样做。 然而,它们在解码器所使用的RNN体系结构以及编码器如何计算源语句表示s方面有所不同。
Kalchbrenner和Blunsom 2013 使用带有标准隐藏单元的解码器以及对源语句表示进行卷积神经网络编码。 另一方面,Sutskever et al. 2014和Luong et al. 2015将带有长期短期记忆(LSTM)隐藏单元的多层RNN堆叠在一起同时用于编码器和解码器。 Cho et al. 2014、Bahdanau et al. 2015和Jean et al. 2015 在两个组成部分中都采用了一种不同版本的RNN — 带有受LSTM启发的隐藏单元,门控循环单元(GRU)。4
更详细地说,人们可以将解码每个单词yj 的概率参数化为:

其中g 为转换函数,其输出为一个词汇大小的向量。5 这里,hj 为RNN 隐藏单元,下面这样计算:
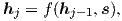
其中f 计算给定前一隐藏状态的当前隐藏状态,可以是普通的RNN单元、GRU或LSTM单元。 在[Kalchbrenner and Blunsom 2013; Sutskever et al. 2014; Cho et al. 2014; Luong et al. 2015]中,源语句的表示s 在初始化解码器状态时只用一次。 然而,在[Bahdanau et al. 2015; Jean et al. 2015]和这项工作中,s 在事实上表示源语句隐藏状态的一个集合,在翻译的整个过程中都会查看这些源语句隐藏状态。 这种方法被称为 attentional 机制,我们将在下面讨论。
在这项工作中,依据[Sutskever et al. 2014; Luong et al. 2015],我们使用堆叠的 LSTM 架构用于我们的 NMT 系统,如图1 所示。 我们使用[Zaremba et al. 2015]中定义的LSTM 单元。 我们的训练目标如下公式所示:
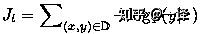
其中D为我们并行训练的语料库。
3 基于 attention 的模型
我们各种基于 attention 的模型分为两大类:全局 和局部。 这两个类别的区别在于“attentional”是放在所有来源语句位置上还是仅放在少数源语句位置上。 我们分别在图2和3中说明这两种模型类型。
这两种类型模型的共同之处在于,在解码阶段的每个时间步骤t 中,两种方法都首先在堆叠LSTM的顶层将隐藏状态ht 作为输入。目标是获得一个上下文向量ct,捕获相关的源端信息以帮助预测当前目标单词yt。 虽然这些模型在获得上下文向量ct 的方式上有所不同,但它们共享相同的后续步骤。
具体来说,给定目标隐藏状态ht 和源侧上下文向量ct,我们使用一个简单的连接层组合来自两个矢量的信息以产生注意力隐藏状态,如下所示:
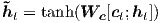
注意向量
ht 然后通过softmax层馈送以产生如下预测分布:

我们现在详细介绍每个模型类型如何计算源端上下文向量c t。
3.1 全局 attention


图2: 全局 attention 模型 — 在每个时间步骤t 处,模型基于当前目标状态ht 和所有源状态hs 推断可变长度 对齐权重向量at 。 根据at,全局上下文向量ct 然后计算为所有源状态的加权平均值。
全局 attention 模型的思想是在推导上下文向量ct 时考虑编码器的所有隐藏状态。 在这个模型类型中,变长对齐向量at 的大小等于源侧的时间步长的数量,它通过比较当前目标隐藏状态ht 和每个源隐藏状态hs 得到:
at(s)=align(ht,hs) =

这里,score为基于内容的函数,我们考虑三种不同的选择:
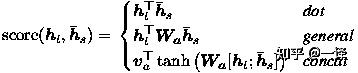
此外,在我们早期构建基于 attention 的模型的尝试中,我们使用基于位置的函数,其中对齐分数仅从目标隐藏状态ht计算,如下:

给定对齐向量作为权重,将上下文向量ct 计算为所有源隐藏状态下的加权平均值。6
与[Bahdanau et al. 2015]的比较 — 尽管我们的全局 attention 方式在本质上类似于Bahdanau et al. 2015提出的模型,有几个关键差异反映了我们如何从原始模型中进行简化和泛化。 首先,我们只需在编码器和解码器的顶层LSTM层使用隐藏状态,如图2所示。而Bahdanau et al. 2015 将双向编码器中将前向和后向源隐藏状态和非堆叠的单向解码器中的目标隐藏状态连接起来。 其次,我们的计算路径更简单:我们从ht →at →ct →ht,然后进行预测,等式(5)、等式(6)和图2有详细解释。 然而,在任何时刻t,Bahdanau et al. 2015 从前一个隐藏状态构建 ht-1 →at →ct →ht,然后再预测之前再添加一个deep-output 和一个 maxout 层。7 最后,Bahdanau et al. 2015 只使用一个对齐函数concat 积进行了实验;而我们显示其他方法更好。
3.2 局部 attention
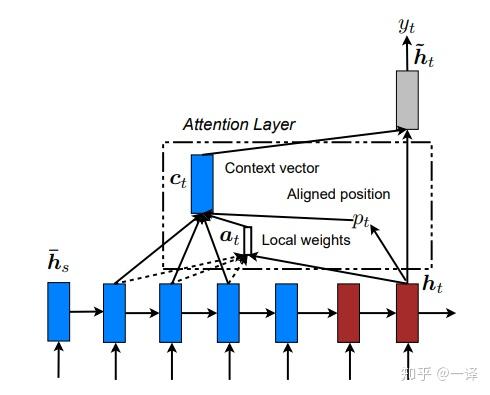

图3: 局部 attention 模型 — 模型首先为当前目标单词预测一个对齐好位置pt 。 然后使用以源位置pt为中心的窗口来计算上下文矢量ct — 窗口中源隐藏状态的平均值。 权重at 从当前目标状态ht和窗口中的这些源状态hs 推断。
全局 attention 的缺点是对于每个目标单词它必须关注源语句的所有单词,这很消耗资源并且可能使翻译更长的序列(例如段落或文档)变得不切实际。 为了解决这个不足,我们提出了一个局部 attention 机制,它每个目标单词选择只关注一小部分源位置。
这个模型从Xu et al. 2015 提出的用于处理图像标题生成任务的soft 和hard attention 模型之间的权衡取得了灵感。 在他们的工作中,soft attention是指全局 attention 方法,其中权重被“softly”地放置在源图像中的所有补丁上。 而hard attention,一次选择图像的一个补丁进行关注。 尽管在推断时间上花费较少,但hard 注意模型是不可微分的,并且需要更复杂的技术,如方差减少或强化学习来训练。
我们的局部注意机制有选择性地集中在一个小窗口的上下文,并且是可微分的。 这种方法的优点是避免了软注意力的昂贵计算,同时比hard 注意法更易于训练。 具体来说,在时刻t 模型首先为每个目标单词生成一个对齐位置pt。上下文向量ct 通过窗口[pt -D, pt+D] 内的源隐藏状态集合加权平均计算得到;D 根据经验选择。8 与全局方法不同,局部对齐向量at 是固定维度的,即∈ℝ2D+1。 我们考虑这个模型的以下两种变体。
单调 对齐(local-m) — 我们简单地设置pt = t,假设源和目标大体上是单调对齐的。 对齐向量at 根据公式(7)定义。9
可预测的 对齐(local-p) — 我们的模型不再假设单调对齐,而是预测一个对齐位置,如下所示:
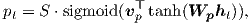
Wp 和vp 是模型的参数,它们将用于学习来预测位置。 S 为源语句的长度。 sigmoid 的结果使得pt ∈ [0,S ]。 为了使对齐点靠近pt,我们放置一个以pt 为中心的高斯分布。 具体而言,我们的对齐权重现在定义为:
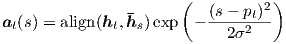
我们使用与等式(7) 中相同的align 函数,标准方差依据经验设置为σ =

。 注意,pt 是一个实数;而s 是一个整数 位于窗口中间位置pt。10
与[Gregor et al. 2015]的比较 — 它已经提出一个可选择的注意力 机制用于图像生成认为,与我们的局部注意力非常类似。 他们的方法允许模型选择不同位置和缩放的图像。 相反,我们对所有目标位置使用相同的“缩放”,这极大地简化公式并且仍然取得良好的性能。
3.3 Input-feeding 方法
在我们提出的全局和局部方法中,attention 的决策是独立进行的,这不是最好的方式。 而在标准MT中,在翻译过程中经常保持一个coverage 集以跟踪哪些源词已被翻译。 同样,在attention NMT中,应该考虑到过去的对齐信息共同作出决定。 为了解决这个问题,我们提出了一种input-feeding 方法,其中attention 向量ht 在下一个时间步骤与输入串联,如图4所示。11 这种联接有两重效果:(a)我们希望使得模型更完整地关注前面对齐的选择(b) 我们创建一个非常深度的网络,在水平和垂直方向同时扩展。


图4: Input-feeding 方法 — Attention 向量ht 作为输入送给下一个时间步骤以告知模型过去的对齐决策。
与其他工作比较 — Bahdanau et al. 2015使用与我们的ct 类似的上下文向量来构建随后的隐藏状态,这也可以实现“coverage”效果。 然而,没有分析这种连接是否有用,正如本文所做的那样。 另外,我们的方法更 general;如图4所示,它可以应用于通用堆栈循环体系结构,包括非 attention 模型。
Xu et al. 2015 提出一种 双重 attention 方法,在图片标题生成过程中,将一个额外的约束添加到训练的目标来确保模型关注图像的所有部分。 这种约束对于捕获我们前面提到的NMT中的coverage 效应也很有用。 但是,我们选择使用 input-feeding 方法,因为它为模型灵活地决定它认为合适的任何 attention 限制。
4 实验
我们在两个方向上评估我们的模型对英语和德语之间的WMT翻译任务的有效性。 newstest2013(3000个句子)被用作开发集来选择我们的超参数。 翻译的性能基于newstest2014(2737条语句)和newstest2015(2169条语句),用大小写敏感的BLEU值[Papineni et al. 2002]表示。 依据[Luong et al. 2015],我们使用两种类型的BLEU报告翻译的质量(a) tokenized12 BLEU 以用来与已有的 NMT 工作进行比较 (b) NIST13 BLEU 以用来与 WMT 结果进行比较。


表1:WMT'14 English-German 结果— 显示的是各种系统在newstest2014 上的perplexities (ppl) 和tokenizedBLEU 分值。我们用粗体突出显示最好的系统,并在连续系统之间以斜体字给出逐步的改进。local-p表示局部attention 和预测式的对齐。我们用圆括号指出每个attention模型使用的对齐分值函数。
4.1 训练细节
我们所有的模型都使用WMT'14训练数据进行训练,这些训练数据由4.5M 个句子对(116M个英文单词,110M个德文单词)组成。类似于[Jean et al. 2015],我们将词汇量限制为两种语言中最常见的50K 个单词。 不在这些入围词汇表中的单词被转换成通用标记<unk>。
当训练我们的NMT系统时,依据[Bahdanau et al. 2015; Jean et al. 2015],我们过滤掉长度超过50个单词的语句对并洗乱mini-batch。 我们的堆叠LSTM模型有4层,每层有1000个单元,以及1000维嵌入。 在训练NMT时,我们采用和[Sutskever et al. 2014; Luong et al. 2015]相似的设置: (a) 参数均匀分布地初始化为[-0.1,0.1] (b) 使用普通的SGD训练10个周期 (c) 采用简单的学习速率调整 — 开始学习速率为1;5 个周期之后,每个周期的学习速率减半 (d) mini-batch 大小为 128 (e) 每当norm 超过5时就将normalized 梯度重新缩放。 另外,依据[Zaremba et al. 2015]的建议,我们还对 LSTM 使用概率为 0.2 的丢弃。 对于丢弃模型,我们训练12个时期,并在8个周期后开始将学习率减半。 对于局部 attention 模型,我们凭经验设定窗口大小D = 10。
我们的代码在MATLAB中实现。 在单个 GPU 设备 Tesla K40 上运行时,速度达到每秒 1K 个目标 单词。 完成模型训练需要7-10天的时间。
4.2 英德结果
我们将我们的NMT系统在英德任务中与各种其他系统进行比较。 它们包括WMT'14 [Buck et al. 2014] 中获胜的系统,它是基于短语的系统,其语言模型在庞大的单语文本Common Crawl 语料库上训练而成。 对于端到端的 NMT 系统,据我们所知,[Jean et al. 2015] 是唯一一个用这种语言对实验的工作,并且是目前的 SOTA 系统。 我们只提供一些关注模型的结果,稍后将在5中分析其余部分。
如表 1 所示,我们在一下情况下取得改进(a) [Sutskever et al. 2014] 提出的反向源语句 +1.3BLEU (b) 使用dropout +1.4BLEU。在此基础上 (c) 全局 attention 方法显著改进 +2.8BLEU,是我们的系统略微高于Bahdanau et al. 2015 的基础 attention 系统 (RNNSearch 行)。 当(d)使用 input-feeding 方法时,我们获得另一个显着改进 +1. 3 BLEU 并超越他们的系统。 局部 attention 模型和预测性的 alignments (local-p 行)证明可以更好,让我们在全局 attention 基础上进一步获得 +0.9 BLEU。 感兴趣的读者可以观察到之前[Luong et al. 2015] 中报到的perplexity 与翻译质量强相关的趋势。 总体而言,我们在非 attention 基线上取得了5.0 BLEU点的显着改善,其中已经包括已知的技术如源语句 reversing 和dropout。
[Luong et al. 2015; Jean et al. 2015]中提出的替换未知单词的技术再次增加 +1.9 BLEU,表明我们的 attention 模型确实学习到对未知单词的有用对齐。 最后,通过整合8种不同设置的不同模型,即使用不同的attention方法、有无丢弃等,我们能够取得一个的新的SOTA 结果23.0 BLEU,超越现有的最佳系统[Jean et al. 2015] +1.4 BLEU。

表2: WMT'15 English-German 结果 — WMT'15 中获胜的NIST BLEU 分值和我们在 newstest2015 上的最优分值。
WMT'15最新的结果 - 尽管我们的模型在数据略少的情况下接受了WMT'14培训,但我们在newstest2015上测试了它们,以证明它们可以很好地推广到不同的测试集。 如表 2 所示,我们的系统建立了一个新的 SOTA 性能 25.9 BLEU,超过现有由 NMT 和 5-gram LM reranker 支持的系统 +1.0 BLEU。
4.3 德语 - 英语结果
我们针对WMT'15翻译任务从德语到英语进行了一系列类似的实验。 While our systems have not yet matched the performance of the SOTA system, we nevertheless show the effectiveness of our approaches with large and progressive gains in terms of BLEU as illustrated in Table 3. attentional 机制让我们在此基础上获得 +2.2 BLEU 的改进, 我们再次从 input-feeding 方法获得 +1.0 BLEU。 使用更好的对齐函数、基于内容的点 乘与dropout 一起再次增加 +2.7 BLEU。 最后,当应用未知单词替换技术时,我们再次增加了 +2.1 BLEU,这说明了attention 在对齐罕见词中用处。
5 分析
我们进行广泛的分析,以更好地了解我们的模型在学习方面,处理长句的能力,注意力架构的选择以及对齐质量。 这里报告的所有结果都在英语 - 德语newstest2014上。


表3: WMT’15 German-English results – performances of various systems (similar to Table 1). base 系统已包含源语句的反向,我们并在此基础上添加了全局 attention、drop out、input feed ing 和unk 替换。
5.1 学习曲线
我们比较了表格1中列出的模型。 It is pleasant to observe in Figure 5 a clear separation between non-attentional and attentional models. 投入方式和本地关注模式也显示了他们降低测试成本的能力。 具有退出(蓝色+曲线)的非注意模型比其他非退出模型学习速度更慢,但随着时间的推移,它在减少测试错误方面变得更加稳健。
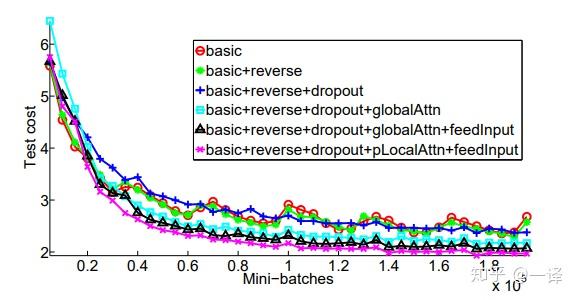

图5: 学习曲线 - 随着培训的进展,英语 - 德语NMT的newstest2014测试成本(ln困惑度)。
5.2 翻译长句的效果
We follow [Bahdanau et al. 2015] to group sentences of similar lengths together and compute a BLEU score per group.Figure 6 shows that our attentional models are more effective than the non-attentional one in handling long sentences: the quality does not degrade as sentences become longer. 我们最好的模型(蓝色+曲线)胜过所有长度桶中的所有其他系统。
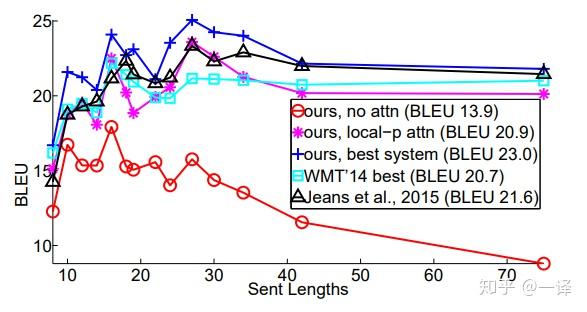

图6: 长度分析 - 不同系统作为句子的翻译质量变得更长。
5.3 Attention 架构的选择
我们研究了不同的关注模型(global, local-m,local-p)和不同的对齐函数(location,dot,general,concat)如章节3中所述。 由于资源有限,我们无法运行所有可能的组合。 但是,Table 4中的结果确实为我们提供了关于不同选择的一些想法。 基于位置的函数没有学习到很好的对齐:与使用其它对齐函数相比,在实现未知单词替换时,全局(位置) 模型只能获得很小的提升。14 对于基于内容 的函数,我们的实现concat 没有得到很好的性能,还需要更多的分析去理解其原因。15 有兴趣的读者可以观察到 dot 对于全局attention 工作的很好,而 general 对于局部attention 更好。 在不同的模型中,无论是 perplexity 还是 BLEU ,具有预测性对齐的attention 模型(local-p)都是最好的。
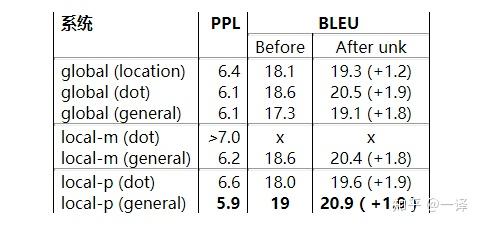

表4:Attention 的架构— 不同Attention 模型的性能。我们训练了两个局部m(dot)模型;两者的 ppl 都>7.0。
5.4 对齐质量
Attention模型的副产品是单词的对齐。 虽然[Bahdanau et al. 2015] 对某些示例句子进行可视化对齐,并观察到翻译质量的改进作为attention 模型如何工作的指示,但没有工作评估整个学习的对齐。 相反,我们着手使用对准误差率(AER)度量来评估对准质量。

表6: AER scores – results of various models on the RWTH English-German alignment data.
鉴于RWTH为508英语 - 德语Europarl句子提供的黄金排列数据,我们“强制”解码我们的注意力模型以生成与参考文献相匹配的翻译。 我们通过选择每个目标单词具有最高对齐权重的源词来提取仅一对一对齐。 Nevertheless, as shown in Table 6, we were able to achieve AER scores comparable to the one-to-many alignments obtained by the Berkeley aligner [Liang et al. 2006].16
我们还发现,由地方关注模型产生的路线比全球路线的AER更低。 The AER obtained by the ensemble, while good, is not better than the local-m AER, suggesting the well-known observation that AER and translation scores are not well correlated [Fraser and Marcu 2007]. 我们在附录A中显示一些对齐可视化。
5.5 示例翻译
我们在两个方向的表格5中展示样本翻译。 它吸引人注意观察注意模型在正确翻译“Miranda Kerr”和“Roger Dow”等名字时的效果。 非注意模型虽然从语言模型的角度产生明智的名称,但缺乏源头直接连接来做出正确的翻译。 我们还在第二个例子中观察到一个有趣的例子,它需要翻译双重否定短语“不兼容”。 The attentional model correctly produces “nicht … unvereinbar”; whereas the non-attentional model generates “nicht vereinbar”, meaning “not compatible”.17 The attentional model also demonstrates its superiority in translating long sentences as in the last example.
6 结论
在本文中,我们提出了两种简单而有效的神经机器翻译注意机制:始终注视所有源位置的全局方法和本地,仅适用于一次一个源位置的子集。 我们在两个方向上测试我们的模型在WMT翻译任务中的英语和德语之间的有效性。 Our local attention yields large gains of up to 5.0 BLEU over non-attentional models which already incorporate known techniques such as dropout. 对于英文到德文的翻译方向,我们的集成模型已经为WMT'14和WMT'15建立了最新的最新结果,优于现有的最佳系统,并由NMT模型和n -ML LM rerankers,超过1.0 BLEU。
我们已经比较了各种对齐功能,并阐明了哪些功能对于哪些注意模型最适合。 我们的分析表明,在许多情况下,基于注意力的NMT模型优于非注意模型,例如在翻译姓名和处理长句子时。
致谢
我们非常感谢Bloomberg L.P.的支持以及NVIDIA公司对Tesla K40 GPU的支持。 我们感谢Andrew Ng和他的团队以及Stanford Research Computing让我们使用他们的计算资源。 我们感谢Russell Stewart对模型的有益讨论。 最后,我们要感谢Quoc Le,Ilya Sutskever,Oriol Vinyals,Richard Socher,Michael Kayser,Jiwei Li,Panupong Pasupat,Kelvin Guu,斯坦福大学NLP小组成员和匿名评论员的宝贵意见和反馈。
参考文献
[Bahdanau et al. 2015] D. Bahdanau, K. Cho, and Y. Bengio. 2015. Neural machine translation by jointly learning to align and translate. In ICLR.
[Buck et al. 2014] Christian Buck, Kenneth Heafield, and Bas van Ooyen. 2014. N-gram counts and language models from the common crawl. In LREC.
[Cho et al. 2014] Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. 2014. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In EMNLP.
[Fraser and Marcu 2007] Alexander Fraser and Daniel Marcu. 2007. Measuring word alignment quality for statistical machine translation. Computational Linguistics, 33(3):293–303.
[Gregor et al. 2015] Karol Gregor, Ivo Danihelka, Alex Graves, Danilo Jimenez Rezende, and Daan Wierstra. 2015. DRAW: A recurrent neural network for image generation. In ICML.
[Jean et al. 2015] Sébastien Jean, Kyunghyun Cho, Roland Memisevic, and Yoshua Bengio. 2015. On using very large target vocabulary for neural machine translation. In ACL.
[Kalchbrenner and Blunsom 2013] N. Kalchbrenner and P. Blunsom. 2013. Recurrent continuous translation models. InEMNLP.
[Koehn et al. 2003] Philipp Koehn, Franz Josef Och, and Daniel Marcu. 2003. Statistical phrase-based translation. In NAACL.
[Liang et al. 2006] P. Liang, B. Taskar, and D. Klein. 2006. Alignment by agreement. In NAACL.
[Luong et al. 2015] M.-T. Luong, I. Sutskever, Q. V. Le, O. Vinyals, and W. Zaremba. 2015. Addressing the rare word problem in neural machine translation. In ACL.
[Mnih et al. 2014] Volodymyr Mnih, Nicolas Heess, Alex Graves, and Koray Kavukcuoglu. 2014. Recurrent models of visual attention. In NIPS.
[Papineni et al. 2002] Kishore Papineni, Salim Roukos, Todd Ward, and Wei jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In ACL.
[Sutskever et al. 2014] I. Sutskever, O. Vinyals, and Q. V. Le. 2014. Sequence to sequence learning with neural networks. In NIPS.
[Xu et al. 2015] Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron C. Courville, Ruslan Salakhutdinov, Richard S. Zemel, and Yoshua Bengio. 2015. Show, attend and tell: Neural image caption generation with visual attention. In ICML.
[Zaremba et al. 2015] Wojciech Zaremba, Ilya Sutskever, and Oriol Vinyals. 2015. Recurrent neural network http://regularization.In ICLR.