2021年,Pre-train+finetune还是“新”范式吗?乘风破浪的Prompt-base methods

最近确定了一个研究课题,为了找方法和灵感读了大量prompt的论文,文章的列表参考的是这个开源项目
总之本意是,读论文太枯燥输入累了码点字来点输出。希望能和大家讨论起来。有些观点仅代表我个人认知,而且还没有做相关的实验,可能不是很准确,所以还望大家指正。
那我们现在开始吧!
作为任务和发现的prompt
prompt的起源可以追溯到GPT2[1],T5[2],GPT3[3]的一些发现。比如GPT2、3中(GPT3更加清晰地认识到了这点),当我们输入带有指令的文本,以文本摘要为例“summarization:”接在我们要进行文本摘要的文本前面,GPT就会输出生成文本摘要,无独有偶T5将类似的方式用于微调步骤(finetune),虽然本意可能是为了将各种NLP任务(包括文本分类,情感分析,文本摘要等)统一成text2text任务,但是也得到了同样的结论,也就是说,对于大规模文本上的预训练模型,我们给予合适的引导、激发(prompt),可以使得其中含有的信息更好地被展现出来,来做各种各样的任务。
prompt诞生之初就有着研究上的得天独厚的优越性。研究它似乎可以解决当下(2020中~2021中)nlp的诸多痛点,pretrain+finetune带来的每一个任务都需要维护一整个大模型带来的诸多不便,预训练模型少样本(zero/few-shot)下表现不尽人意,文本生成无法有效控制,难以进行领域迁移,以及对于预训练模型的低效率利用,灾难性遗忘等等等等…另一个角度是随着GPT3的诞生,指数级的预训练参数量让诸多研究者发现自己根本无力(精力和体力上的)参与这场已经根本早就不novel的竞赛(可能从这时候起提出新的预训练目标就不算是什么novel的事了吧),转而向如何找到更加高效利用这些模型参数的方式。
Adapter-用附加结构调度预训练模型的开端
其实更小更高效的模型结构在很早就有研究者在探索了,其中很有前瞻性的工作当属Adapter[4],简而言之它在transformer的“关节”(勿怪)位置加入了小参数的带有skip机制的压缩映射,在使用时将原来transformer的其它参数照抄复制并且冻结,单独训练adapter插入到关节位置的小映射矩阵,取得了很好的trade off来的性能(1%参数量,性能牺牲不大,比简单的少finetune几层高效地多)。Adapter我们可以看做其为一种“模型上的激发”,即用模型中插入某些结构,用其参数更好地调度pretrain中已经学到的知识,在2019年这个时间点做出了非常有前瞻性的尝试。
LAMA-语言模型中的Language,Fact,Common Sense,World View
语言模型作为本质的预训练模型中所含有的真的只有语言信息吗?或许还有知识,常识,甚至别的东西。越来越多的研究者在2019年开始试图从BERT[5]中掘金,研究者们开始使用预训练模型做信息检索等任务,探究是否真的能够在预训练语言模型中得到相关的知识,在这个背景下,LAMA[6]数据集也应运而生。这个数据集提供了大量的用于挖掘语言模型中信息的完形填空模板,比如“Obama worked as _”作为用来挖掘语言模型中是否含有奥巴马的职业这个信息的prompt,从这个时候prompt就逐渐被引导向完形填空,而不是仅仅指示作为前缀。这个数据集也成为了后来很多prompt工作的出发点、工具和baseline。
LPAQA-尝试通过选择和组合消除prompt模板选取的影响
越来越多的研究者发现,人工设计的不同的prompt模板会造成性能上的差异,即这些模板对于任务有时候和人想的还不太一样,有些表现的蛮好想有些表现的就不好,所以LPAQA[7]利用原有的LAMA模板以一种非常自然的方式提出更合理的方法去进行使用,分为两步进行1、选择。2、整合。选择阶段其通过一些测试去选择那些在验证集上表现好的模板用来为各个任务使用,整合阶段其将模板的值进行直接平均或者根据验证集上表现进行加权平均。这一套流程非常直觉地将各个prompt模板整合了起来,作者不知道的是,接下来的几项工作,彻底引爆了prompt领域。
PET,iPET以及改进-PET宇宙的大爆炸
PET[8]实际上是LPAQA的同期工作,但是他的特殊之处在于不仅仅将目光局限在信息挖掘,而是尝试把预训练prompt下语言模型的能力推广到一切有监督问题比如最经典的文本分类问题上。PET另一个贡献就是他把prompt“模式激发”的范式规范了起来,从此也成了后续研究的某种意义上的现行标准:
以文本分类为例,原有的输入文本为x,输出标签为y,使用模式P将x重新构建,使用verbalizer将y进行映射得到新的x和y,用其进行微调。
pattern P: x作为原来的文本输入映射到对应的prompt构造的修饰过的(构造了一个完形填空问题,比如做二元情感分类,本来是通过一句话判断一个标签,“I love this movie.”,变成了构造出来的prompt后的“I love this movie. It’s [MASK]”,然后来预测mask位置词的分布)


verbalizer v:然后将y中的每一个标签映射为一个词,比如接着刚刚那个例子,正样本标签为词“good”,负样本标签为词“negative”。
那么PET方法思想做的就是用这些新构建出来的x,y对去finetune预训练模型,然后也用这些去测试。
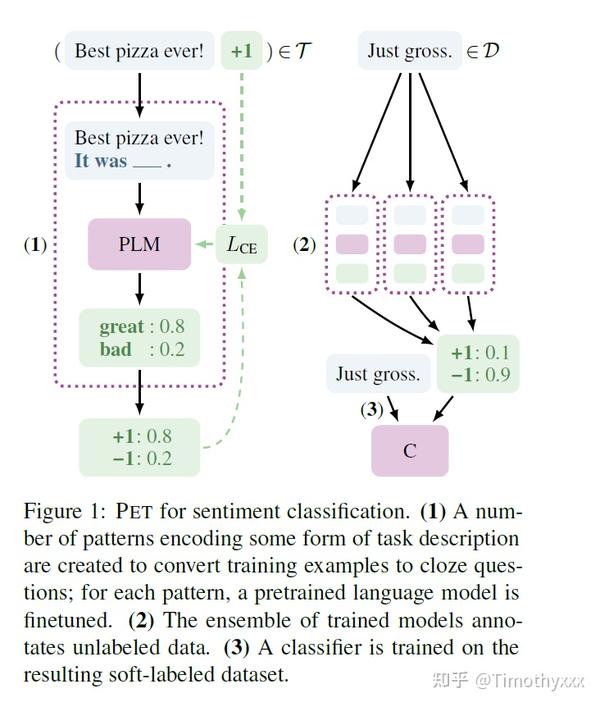

每个完形填空的模板对应着一个训出来的PET模型,作者使用这些模型给无标签的数据(本篇工作假定无标签数据很好获取)打上软标签(soft-label),使用类似知识蒸馏的办法去用这些软标签训练一个新的PET模型最终使用。这就是完整的PET方法了,其实大家可以看到,和LPAQA的那两步还是非常非常相似的。
作者在论文中还提出来iPET模型,使用多个PET之间的交互与迭代在PET的基础上逐步地将无标签数据打上标签加到每一簇数据中使其倍增,每一次倍增同时训练PET,通过模型之间交互提升数据与训练的质量。在多个包括MNLI的文本分类任务下的实验证明相较于传统的有监督finetune学习,PET系列方法在多个任务上尤其是few shot setting下具有很好的表现。


方法为什么work,从某种角度上可能是因为finetune过程更好地顺承了pretrain过程的任务,更好地调度了pretrain的知识。当然这都只是猜测之一,所以侧面反应文章非常地有启发性。
此外作者后续还追加提出了为了进行除了文本分类以外的任务所必须要使用的多个完形填空的空位的版本,以及自动寻找更好的label到word(或者是一堆word)的映射v的改进[10],跟着自己掀起的浪潮extend自己的工作,这个我们后面继续说…
ALBERT+PET>GPT3,被干翻的few shot性能
2020年年初到快年中时,OpenAI 的GPT3[3]论文发表。以其庞大的参数量与最强的few shot甚至zero shot能力令人瞠目结舌。但是GPT这种模型却有一个很致命的问题是在传统的few shot setting finetune方法在自然语言理解NLU任务上的结果不是很令人满意,研究者们也暂时没有去想什么好的解决办法。PET原班人马几乎是同时揪着这一个问题把GPT拉到自己新提出方法可以解决的SuperGLUE以及其他任务上,提出了ALBERT(参数量大概是GPT3的千分之一这个量级)+多token改良版PET[9](多token改良后可以使其不仅仅支持文本分类,还可以支持问答等)的模型,并将其与GPT进行battle,以小博大,充分证明了方法的优越性。
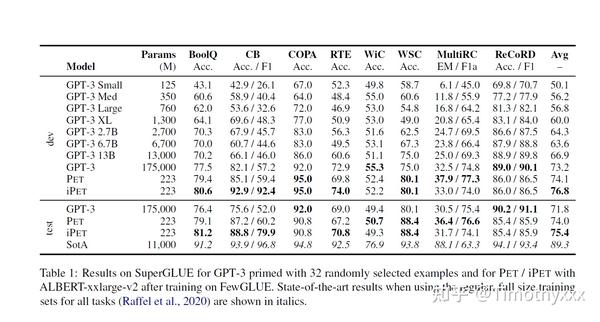

作者们为了使得iPET可以得到无监督数据满足他们的settings,在SuperGLUE基础上,构造了FewGLUE并且开源。
个人认为可能就是此时PET的few shot能力被展现出来(或许是之前原版文章的分类任务和SuperGLUE相比有点散装过家家?),它提出的范式(x套上prompt模板:pattern,标签转化为预测词:verbalizer,然后进行finetune)开始得到了足够的重视。
纵然有效,PET方法存在很多可以改进的地方,比如prompt的pattern都是手工设计的,纵使PET和iPET已经使用某些机制让他们之间可以进行更好地结合,但是手工设计的弊端并没被完全消除;第二点就是如何找到合适的标签到词的映射,映射到哪个词,以及一个标签对应一个词是不是不是很合理。这两点是看完PET之后很自然的一些改进方向。
从此,既然已经证明了PET范式的有效性,研究者们开始将注意力集中到自动化的prompt模板构造和自动化的映射到词映射的verbalizer构造这些PET范式的改进上。
Verbalizer的改进
PETAL--PET原班人马的快速补充
在PET原版本的定义中,标签对应的词是手工定义的;另一个方面,一个标签对应一个词,映射为 Y\rightarrow V (V为词表中的token)。这两点都是显而易见粗糙显然是不够合理的。所以PET原班人马立刻补充了一种自动寻找label和修复单映射的方法PET with Automatic Labels (PETAL)[10]。方法还是很简朴的,对于k个label的任务,词汇表大小为|V|,这个搜索最简单的一个表达就是在|V|^k 空间里进行一个遍历,通过遍历label和word的所有组合查看在训练集上的表现来选择最优化的label和word的映射。
但是这种方法的弊端是搜索空间过大,作者通过k-class classification task到k one-vs-rest classifications的转化将一个整个的搜索拆成了k次搜索空间为|V|的搜索。并给予了负样本的权重修正。
对于多标签问题他们将原本的verbalizer的映射 Y\rightarrow V 转化为 Y\rightarrow 2^V ,映射对应的元素是V的子集,其余的流程类似。
AutoPrompt--自动化的prompt模板和自动化的verbalizer
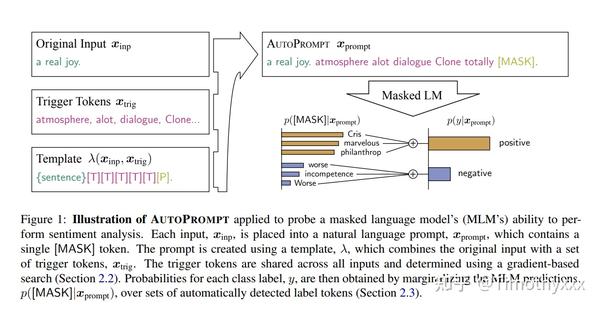
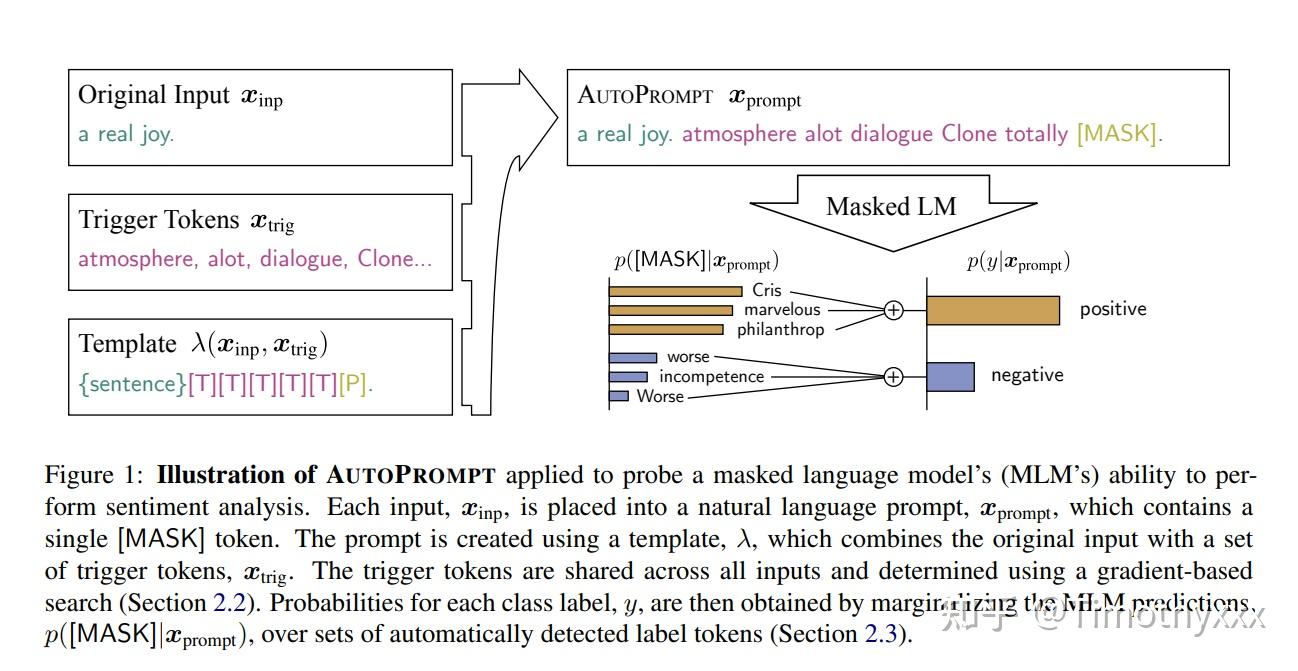
AutoPrompt[11]在构建prompt的部分提出的方法是自动化加入Trigger Tokens[T][T][T]...[T][T],同时在最后追加prediction位置[P](在这里面是[MASK])。那么这些词是如何选取的呢,作者借鉴了另一篇NLP对抗攻击的文章[12],那篇文章原本的目的是想加入某些token使得只要输入加上这些token,结果都会是固定的y。寻找这些token的方法是迭代地选择使得预测函数的一阶近似top-k大的那些词(其实实际上和正反向传播差不多啦),公式和迭代放两张图:
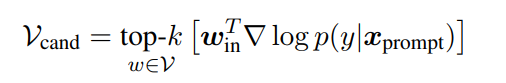

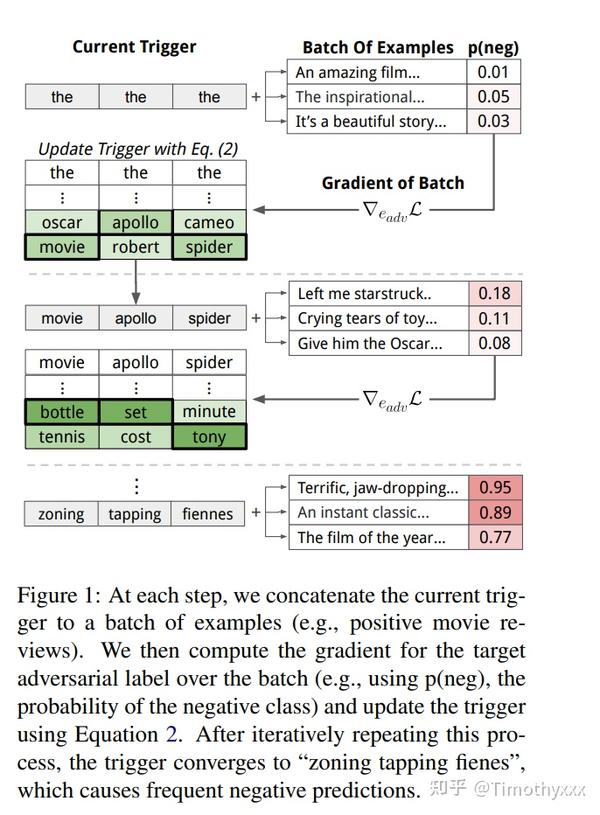

这个方法同样对verbalizer也进行了自动化的设计,简单来说就是先通过做正常的分类任务将 [MASK]位置得到的编码额外连接上训练一个标签分类矩阵,然后挨个词过掩码语言模型(MLM)来得到编码然后同样过这个矩阵来计算得分,取得分高的top-k作为该标签对应的token的集合,理由是这些使得标签分类矩阵分数高的词会和在原来分类问题那些对应位置的词高度相关(我认为作者这一块到底怎么选的词没太写明白),值得注意的是这篇工作里面已经认为一个标签对应很多token是很自然的事情了。
更多explanation和更多prompt模板
刚刚Autoprompt其实就提出来了一种prompt模板,但是同期的工作其实还有很多,都是角度不同,实验充分,方法极具启发性的工作。LM-BFF[13]就是其中一篇
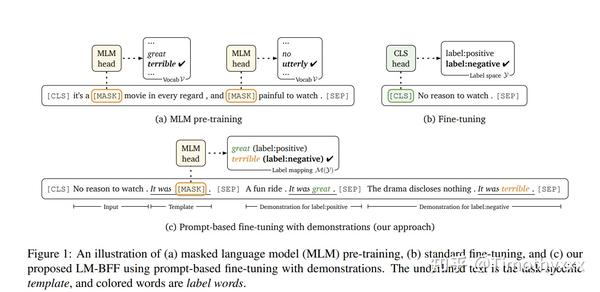

概括来讲这篇文章提出了两件事,第一件是使用demonstration来更好地调度MLM模型,这种做法可以说是把PET当时忘掉的初心捡起来了(详见PET的intro里面自己给自己的解释),而且证明是非常有效果;第二个很亮的点就是使用T5[2]来进行自动化的prompt的模板构造。
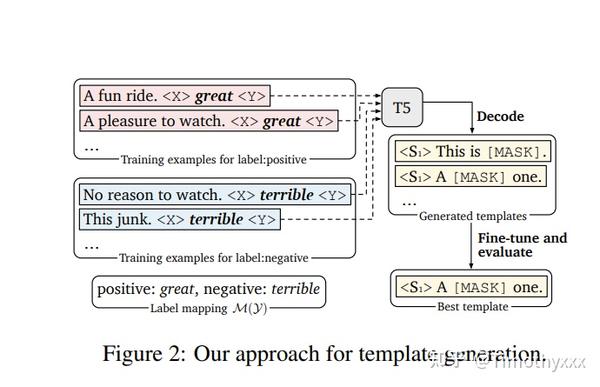

个人认为这篇文章的点真的很好地把握到了prompt的精髓,进而极具启发性:要想更加的few shot,一定不要把学到的知识浪费在迁移上面,学什么用什么才是效率最高的做法。对于T5来讲,既然他学习到的是这种span的替换,那么必然地直接使用span才是省力的做法。
更多的细节大家可以移步到作者本尊的blog。
被忽视的使用前标定--一些其它的工作
Calibrate Before Use--使用前记得先平衡一下分布
这篇文章[14]主要解决的痛点是few shot setting下的不稳定问题,文章分析了不同的不稳定的来源,包括few shot的样本(到底是这3个还是池子里面那3个呢?),顺序(ABC or ACB or CBA?),和模板。以及本身语言模型就是倾向于输出那些它经常见到的词这种固有一些性质。
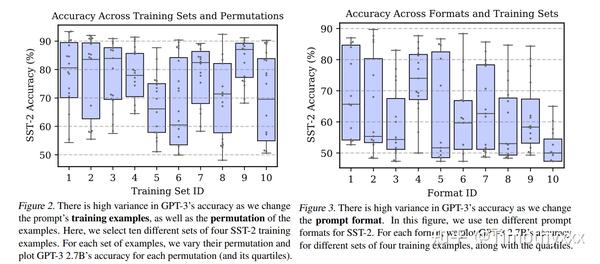

然后提出了一种使用语境无关的词的预测分布进行标定的方法:输入一个上下文无关的x(比如[MASK],或者N/A),它的分布向量p应该是均匀的,不均匀我们就让它是均匀的,通过乘以一个标定矩阵 diag(p)^{-1} 来达到这一点。文章通过大量实验证明这种方法的有效性。
ADAPET--有点像ELECTRA?
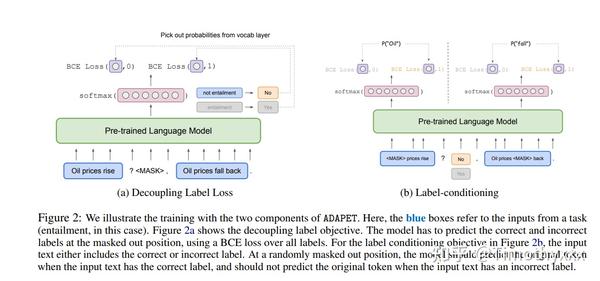

这篇文章主要抨击PET的点有两个,第一个就是PET计算不同label的概率仅仅是拿出来向量中他们对应的那些词的logits,然后算各自的占比,而将其他词都忽视掉了;第二点也是因为第一点使得PET在各个任务的处理上不够unified。所以ADAPET[15]转化了一下优化目标,变成了每一个标签的对应词组成的onehot和预测logits整体的交叉熵损失,更加地unified,同时还提出了一种label condition的方法,就是如果是对的label就将mask的词拉到原来的词,如果是改成错的了那就把它和正确词概率拉远,prompt训练时两种训练一起用。不得不说可以嗅出了一丝ELECTRA的味道。如果有兴趣去看SuperGLUE的榜单的话会发现和篇文章和iPET一上一下占了fewshot setting下的两个卡槽。
P-tuning到Prefix-tuning--GPT或许understand,我们也将跳出prompt模板,走向更加广义的融合prompt的新范式
P-tuning--从离散化模板到连续化模板
之前的prompt获得方案中,最终都是构建出一种人能看到的词(离散的token)来构建prompt输入,但是这篇文章的团队的核心动机在于认为这样的构建没有将prompt模板的潜力挖掘干净,进而导致了不稳定,组合低效等等固有的弊端。模型眼里是看到的是连续的embeddings矩阵而不是一定要是某些特定的词来构造出来的序列对应的embeddings序列,所以不如把prompt构建到输入embedding的那一步。很有启发性。
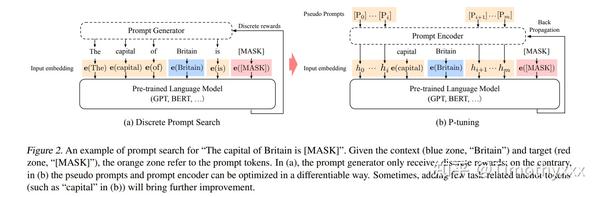

P-tuning[16]使用LSTM进行prompt的encode然后于输入再加上一些anchor的embedding进行拼接,输入模型进行PET方式的训练,同时更新Pretrain Model和Prompr Encoder的参数(初始化也是一个需要注意的问题,这里我们先不谈)。这种很novel的连续化模板构建方法,更加充分地挖掘通过prompt构建带来的更深一步挖掘出来的BERT,以及GPT等生成模型的潜能。几个有趣的发现是,之前prompt领域几乎将所有的注意力集中到MLM模型上,而不是GPT这种Auto-regressive的模型上,因为其可能被认为在NLU领域上表现欠佳,但是这篇文章通过P-tuning方法构建出的连续化可导模板并且取得的良好效果说明了GPT同样也可以用于做非常好效果的NLU任务,由落后转向超越MLM,so GPT Understand, too, right?
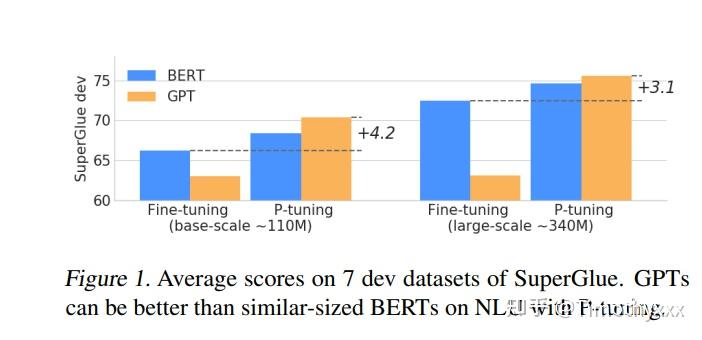

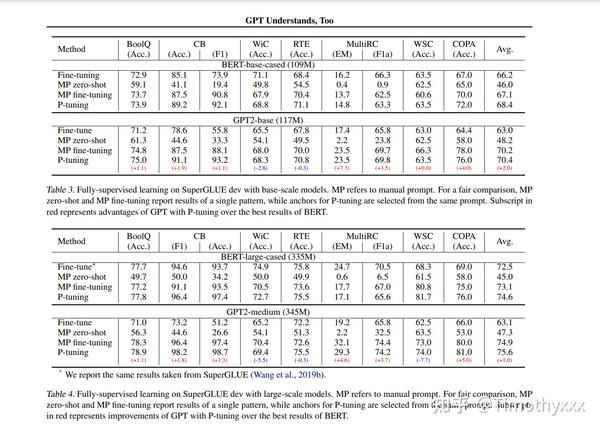
吸引我注意的还有一点是,在这篇文章发出来的时候(2021.3),P-tuning已经可以在SuperGLUE的fully setting下击败finetune方法了(注意之前很长一段时间的卖点是few shot, 全数据很多工作都不太提),结果如下图所示,这可能是一个非常好的信号。但是还是,由于其将包括pretrain模型所有参数全都进行训练了,所以或许还不能说是完全地优于finetune。

Prefix-tuning--模板构造方法的更严格的下界
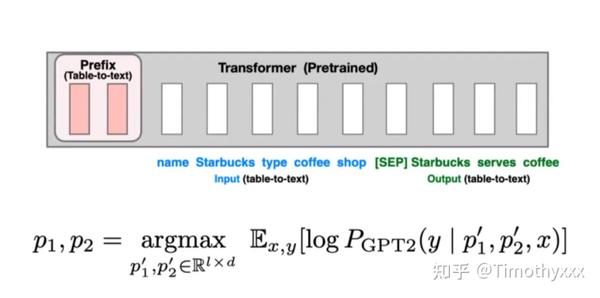
Prefix-tuning[17]方法是通过加可以训练的前缀矩阵来进行prompt模板构建,但是并不是基础版本的前缀矩阵+输入文本的embedding构成prompt输入到语言模型中,而是更加直接地用了一个更大的送到语言模型的每一层里面大前缀矩阵(而不是只在底层输入让上面去用语言模型交互),而且和P-tuning不同的是,它freeze了预训练模型,在text-to-table任务上和文本分类的类似cross domain setting上将和finetune和adapter等构成的baseline在参数量和性能综合考察下全面击败。
这篇文章通过实验得到的一个非常有趣的结论是:
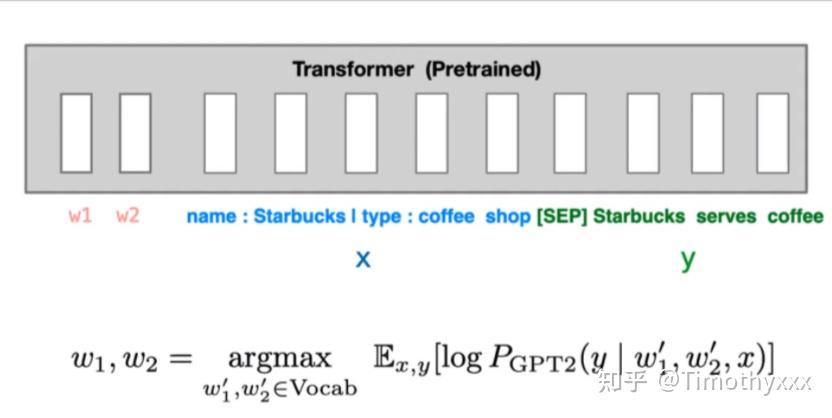
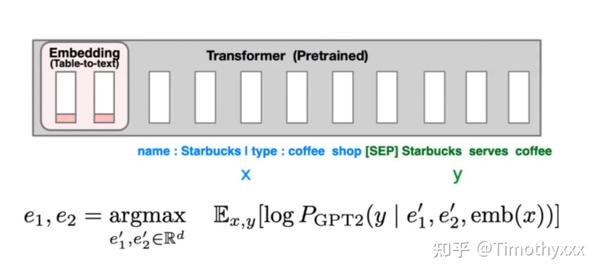
离散化模板构造(discrete prompting) < 连续化embedding模板构造(embedding-only< prefix-tuning,和P-tuning里面也下了类似的结论(但是Lisa Li在油管上有seminar可以看呀,英语是真滴溜),三种方法的三个示例图如下所示


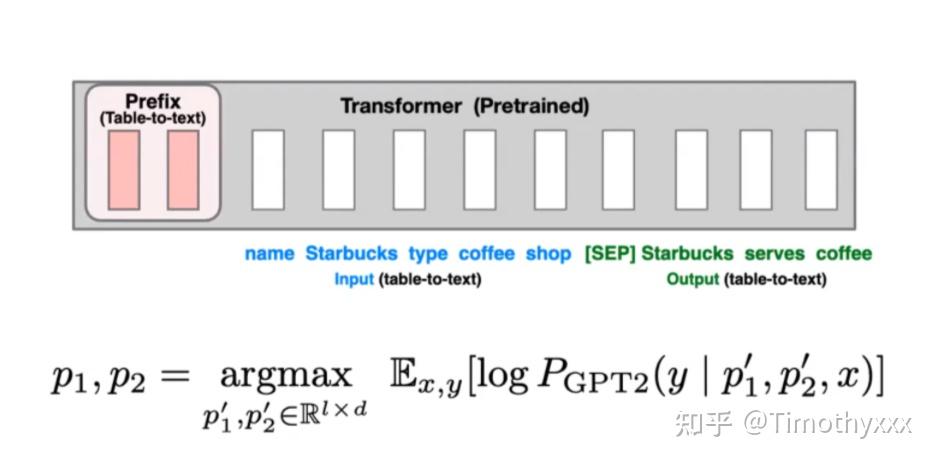
或许为prompt的构建提出了一个更加收官的严格的上界。
追平finetune的prompt tuning--大风起兮?
随着自动找寻prompt模板的坑迅速被填满,研究者几乎都早早认识到了并认可prompt的few shot能力,但是有一部分人觉得这个坑大抵也就这样了吧。可是Google 2021年4月的一项研究prompt tuning[18](和P-tuning Prefix-tuning也可以算是稍稍落后的同期研究)无异于是大厂也给这个领域打了一针强心剂。
研究者们整合了整合了同期的若干种方法,包括P-tuning,Prefix-tuning(又或许是独立的,这里我们就不清楚了)。通过将可调控的prompt可训练矩阵和正常的输入整合到一起作为输入,输入到freeze的预训练语言模型,仅仅训练prompt可训练矩阵,发现随着采取更加大的预训练模型(我们可以看到Model tuning和Prompt tuning都只有5个数据点,那是分别代表T5的small,medium,large,XL,XXL),prompt的方法追赶上了finetune的方法。至少在NLU领域的SuperGLUE上,freeze预训练模型的prompt终于战胜finetune了,意味着只要预训练模型足够大,我们采用一个很小的参数prompt只训练它,就可以调度猛兽,达到一样的效果,而且不是few shot,不是few shot,不是few shot。和P-tuning一样,战胜finetune意味着prompt将引来更多的注意力和更多的增长点。
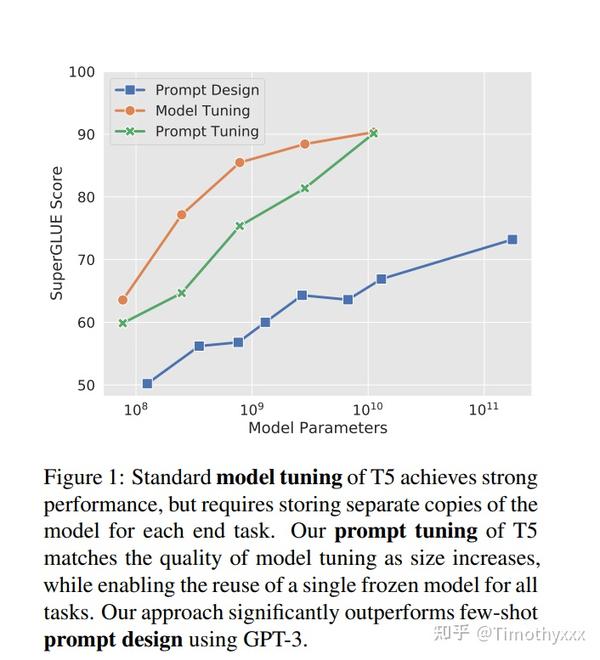

总结来看,这项工作的侧重点在于探究在不同规模的预训练模型下,freeze并且是使用不同的prompt参数进行训练到底能在多大的程度上抹平和finetune整个pretrain模型之间的gap。结果还是非常地振奋人心的。
近期的一些prompt的工作(2021.7)
这个我开完组会更新叭。。
小总结
其实仔细想想,以一个最纯粹的想法来看,finetune到底会不会损失pretrain学到的知识呢?如果是,那么finetune就一定至少不会是调度pretrain语言模型的上界了,以为de facto的pretrain + finetune范式可能需要一场更加彻底地革命。从这一点看prompt相关的文章,可能思路也就逐渐清晰了起来。
当前的问题可能是,如何找到不拘泥于PET的prompt范式的新的调度方法,如何将prompt系列的思路用于各个细分领域。这些都有可能是一些下一步需要被探明的研究热点。
参考文献
[1] Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners.OpenAI blog,1(8), 9.
[2] Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., ... & Liu, P. J. (2019). Exploring the limits of transfer learning with a unified text-to-text transformer.arXiv preprint arXiv:1910.10683.
[3] Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., ... & Amodei, D. (2020). Language models are few-shot learners.arXiv preprint arXiv:2005.14165.
[4] Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., De Laroussilhe, Q., Gesmundo, A., ... & Gelly, S. (2019, May). Parameter-efficient transfer learning for NLP. InInternational Conference on Machine Learning(pp. 2790-2799). PMLR.
[5] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding.arXiv preprint arXiv:1810.04805.
[6] Petroni, F., Rocktäschel, T., Lewis, P., Bakhtin, A., Wu, Y., Miller, A. H., & Riedel, S. (2019). Language models as knowledge bases?.arXiv preprint arXiv:1909.01066.
[7] Jiang, Z., Xu, F. F., Araki, J., & Neubig, G. (2020). How can we know what language models know?.Transactions of the Association for Computational Linguistics,8, 423-438.
[8] Schick, T., & Schütze, H. (2020). Exploiting cloze questions for few shot text classification and natural language inference.arXiv preprint arXiv:2001.07676.
[9] Schick, T., & Schütze, H. (2020). It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners.arXiv preprint arXiv:2009.07118.
[10] Schick, T., Schmid, H., & Schütze, H. (2020). Automatically identifying words that can serve as labels for few-shot text classification.arXiv preprint arXiv:2010.13641.
[11] Shin, T., Razeghi, Y., Logan IV, R. L., Wallace, E., & Singh, S. (2020). Autoprompt: Eliciting knowledge from language models with automatically generated prompts.arXiv preprint arXiv:2010.15980.
[12] Wallace, E., Feng, S., Kandpal, N., Gardner, M., & Singh, S. (2019). Universal adversarial triggers for attacking and analyzing NLP.arXiv preprint arXiv:1908.07125.
[13] Gao, T., Fisch, A., & Chen, D. (2020). Making pre-trained language models better few-shot learners.arXiv preprint arXiv:2012.15723.
[14] Zhao, T. Z., Wallace, E., Feng, S., Klein, D., & Singh, S. (2021). Calibrate before use: Improving few-shot performance of language models.arXiv preprint arXiv:2102.09690.
[15] Tam, D., Menon, R. R., Bansal, M., Srivastava, S., & Raffel, C. (2021). Improving and simplifying pattern exploiting training.arXiv preprint arXiv:2103.11955.
[16] Liu, X., Zheng, Y., Du, Z., Ding, M., Qian, Y., Yang, Z., & Tang, J. (2021). GPT Understands, Too.arXiv preprint arXiv:2103.10385.
[17] Li, X. L., & Liang, P. (2021). Prefix-tuning: Optimizing continuous prompts for generation.arXiv preprint arXiv:2101.00190.
[18] Lester, B., Al-Rfou, R., & Constant, N. (2021). The power of scale for parameter-efficient prompt tuning.arXiv preprint arXiv:2104.08691.


