透过Transformer重新看OCRNet

最近基于Transformer结构设计的骨干网络在视觉的很多任务上都取得了很好的结果,我们在这里也透过Transformer结构重新梳理一下我们的OCRNet[1]和Transformer[2]的联系,本文讨论的内容大部分也都已经更新在最新的arXiv版本[3]。
首先我们先回顾一下OCRNet原始的网络结构:
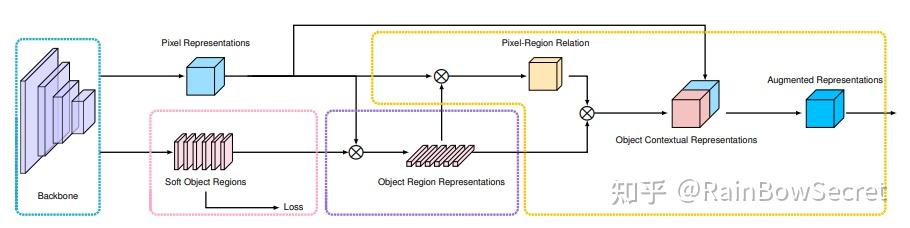

具体来说,上图包含如下几个步骤:
- 根据骨干网络中间层Pixel Representations预测Soft Object Regions (K个Soft Masks, 每个Mask对应于一个语义类别);
- 根据Soft Object Regions对网络深层的Pixel Representations加权求和得到Object Region Representations (每一类都对应于一个Object Region Representation);
- Pixel Representations作为Query, Object Region Representations作为Key-Value, 送入Cross-Attention,输出作为Object Contextual Representations; 然后把Object Contextual Representations和输入的Pixel Representation拼接在一起经过融合之后得到Augmented Representations,最后加一个分类器用于预测最后的语义分割结果;
首先我们这里给出基于(Self-)Attention的计算范式,
下面就让我们一起从Transformer结构的视角重新解读一下OCRNet的这3个步骤:
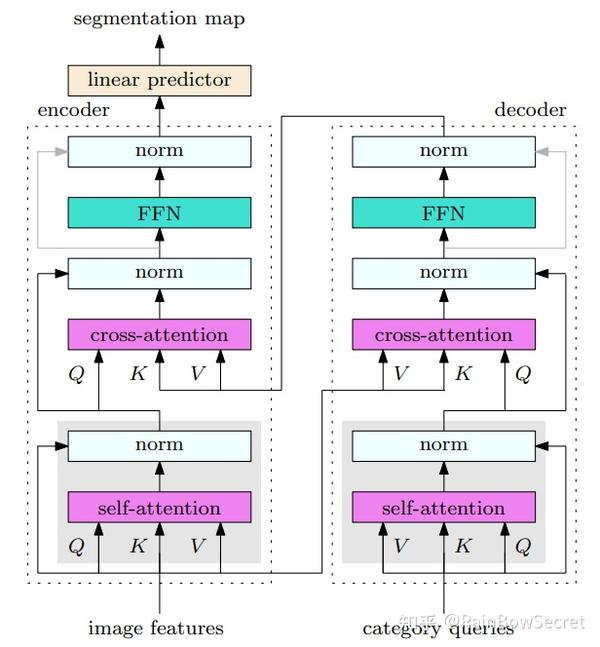

如上图整体所示,Transformer的输入包括2部分,一部分是image representations输入Transformer Encoder用于增强特征表示,另外一部分是category queries输入到Transformer Decoder中可以用于编码不同语义类别的上下文信息。在原始OCRNet中,我们省略了灰色部分的操作,即pixel representations和region representations上的Self-Attention操作 (最新的MaskFormer[4]中也有验证Self-Attention对结果影响很小),我们会重点解读一下这里的Cross-Attention操作。
- Decoder Cross-Attention中的输入包括category queries: \mathbf{Q} \in \mathbb{R}^{d \times N_{\rm{category-query}}} , 和image features:\mathbf{K} \in \mathbb{R}^{d \times N_{\rm{image-feature}}} ,\mathbf{V} \in \mathbb{R}^{d \times N_{\rm{image-feature}}} , 其中 d 是特征维度, N_{\rm{category-query}} 是query个数也是语义别的个数, N_{kv} 是key-value的样本个数也是image features的空间维度, 其attention map的计算如下:
\begin{align} a_{ij} = \frac{e^{\frac{1}{\sqrt{d}}\mathbf{q}_{i}^\top \mathbf{k}_{j}}}{Z_i}~~ \text{where}\space Z_i = \sum\nolimits_{j=1}^{N_{kv}} e^{\frac{1}{\sqrt{d}}\mathbf{q}_{i}^\top \mathbf{k}_{j}}. \label{eqn:attentionweight} \end{align}
其中, a_{ij} 是第 i 个category query和第 j 个image features key-value的关联度,这里计算得到的K个category queries和image features之间的attention map对应于原始OCRNet中的 Soft Object Regions,然后基于如下的attention操作得到的特征对应于OCRNet中的Object Region Representations (原始论文中的公式(4),即 \mathbf{f}_k = \sum_{i \in \mathcal{I}} {\tilde{m}_{ki}} \mathbf{x}_i. ):
\begin{align} \operatorname{Attn}(\mathbf{q}_{i}, \mathbf{K}, \mathbf{V}) = \sum\nolimits_{j=1}^{N_{kv}} \alpha_{ij}\mathbf{v}_{j}, \label{eqn:attentionfeature} \end{align}
这里的category queries做法也类似于最近的ViT[5]和CaiT[6]中的Class Embeddings,我们这里是每一个类都有一个自己的embedding而非所有类别公用同一个embedding,如果我们直接把Cross-Attention同时用于category query和image features,便可以得到如下框架:
- Encoder Cross-Attention接收Transformer Decoder输出的Object Region Representations作为key-value信息,image features作为query信息,因此这里就类似原始OCRNet中的公式(3) \mathbf{y}_i = \rho(\sum_{k=1}^K w_{ik} \delta(\mathbf{f}_k)) 用于利用Object Region Representations去增强每个像素特征从而得到Object Contextual Representations 。
综上可以看出OCRNet方法背后的思想同Transformer的做法有不少共通之处,另外最近也有2篇非常不错的图像语义分割方面工作MaskFormer[4]和K-Net[7]都提出了很有意思的基于Transformer Encoder + Decoder的视角与思路。我们在这里主要从思路层面谈一下这2篇工作和我们OCRNet[3]的联系和区别,如有认识不准确,欢迎批评指正。
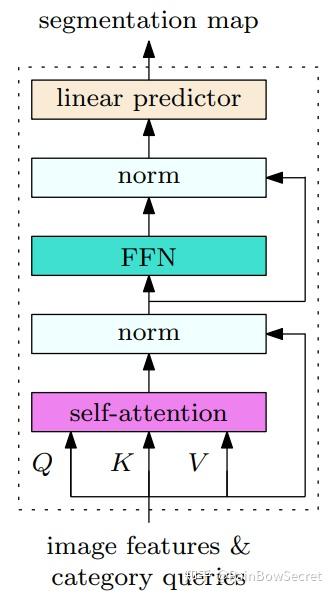
首先我们重新画图对比几种方法:




根据2张图的对比可以看出,3种方法(MaskFormer, K-Net,OCRNet)都是分别对pixel representations和region representations做cross-attention来互相传播信息,即pixel representations和region representations之间的交互。区别在于:
- ·MaskFormer和K-Net都是利用更新后的region representations上预测region class,然后利用region representations和pixel representations的内积作为region map,然后结合region map和region class来产生最后的semantic segmentation map。并且MaskFormer和K-Net都会迭代这个预测过程多次,比如说MaskFormer迭代预测6次而K-Net迭代预测3~4次。
- OCRNet是利用更新后的pixel representations直接预测segmentation map,这里region representations被作为为object region context信息用来增强了pixel representations, 只迭代1次。
综上,我们可以这3种方法的共同点在于都是利用Transformer结构来建模Pixel Representations和Region Representations/Mask Representations/Kernel Representations之间的信息传播,不同点在于最后产生分类预测(Recognition, 即Class Prediction)和分割预测结果(Grouping, 即Mask Prediction)的方式不同。当然MaskFormer和K-Net相比OCRNet也具有更大的灵活性,尤其是MaskFormer的Query信息具有很好的扩展性,是值得关注的语义分割研究方向!
参考
- ^Object-Contextual Representations for Semantic Segmentation, ECCV2020 https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123510171.pdf
- ^Attention Is All You Need, NIPS2017 https://papers.nips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
- ^Segmentation Transformer: Object-Contextual Representations for Semantic Segmentation, arXiv:1909.11065 https://arxiv.org/pdf/1909.11065.pdf
- ^abPer-Pixel Classification is Not All You Need for Semantic Segmentation, arXiv:2107.06278 https://arxiv.org/pdf/2107.06278.pdf
- ^An image is worth 16x16 words: Transformers for image recognition at scale, ICLR2020 https://openreview.net/forum?id=YicbFdNTTy
- ^Going deeper with Image Transformers,arXiv:2103.17239 https://arxiv.org/abs/2103.17239
- ^K-Net: Towards Unified Image Segmentation, arXiv: 2106.14855 https://arxiv.org/abs/2106.14855

