CoTNet-重磅开源!京东AI Research提出新的主干网络CoTNet,在CVPR上获得开放域图像识别竞赛冠军

| 该原创内容首发于我爱计算机视觉,转载请获得授权并标明出处
机器学习/深度学习算法/计算机视觉/多模态交流群
群里每天都会进行论文的分享,加群方式见文末!!!
最近创建了一个关于Attention、重参数、MLP、卷积的项目,复现了一些经典和最新论文的核心代码,帮助大家更好的理解论文的核心思想,目前已有超1k的star。链接放下面了,欢迎大家star呀~~~
写在前面
基于Self-Attention的Transformer结构,首先在NLP任务中被提出,最近在CV任务中展现出了非常好的效果。然而,大多数现有的Transformer直接在二维特征图上的进行Self-Attention,基于每个空间位置的query和key获得注意力矩阵,但相邻的key之间的上下文信息未得到充分利用。
本文设计了一种新的注意力结构CoT Block,这种结构充分利用了key的上下文信息,以指导动态注意力矩阵的学习,从而增强了视觉表示的能力。作者将CoT Block代替了ResNet结构中的3x3卷积,来形成CoTNet,最终在一系列视觉任务(分类、检测、分割)上取得了非常好的性能,此外,CoTNet在CVPR上获得开放域图像识别竞赛冠军。
论文和代码地址


论文地址:https://arxiv.org/abs/2107.12292
代码地址:https://github.com/JDAI-CV/CoTNet
核心代码:https://github.com/xmu-xiaoma666/External-Attention-pytorch#22-CoTAttention-Usage
Motivation
起初,CNN由于其强大的视觉表示学习能力,被广泛使用在各种CV任务中,CNN这种局部信息建模的结构充分使用了空间局部性和平移等边性。但是同样的,CNN由于只能对局部信息建模,就缺少了长距离建模和感知的能力,而这种能力在很多视觉任务中又是非常重要的。


Transformer由于其强大的全局建模能力,被广泛使用在了各种NLP任务中。受到Transformer结构的启发,ViT、DETR等模型也借鉴了Transformer的结构来进行长距离的建模。然而,原始Transformer中的Self-Attention结构(如上图所示)只是根据query和key的交互来计算注意力矩阵,因此忽略了相邻key之间的联系。
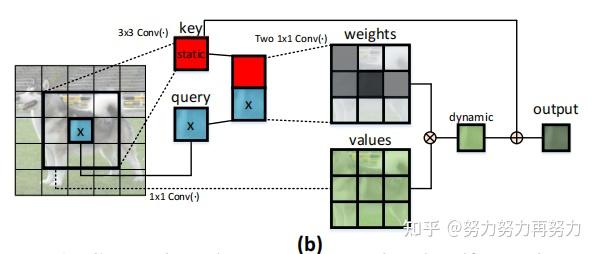

基于此,作者提出了这样一个问题——“有没有一种优雅的方法可以通过利用二维特征图中输入key之间的上下文来增强Transformer结构?”因此作者就提出了上面的结构CoT block。传统的Self-Attention只是根据query和key来计算注意力矩阵,从而导致没有充分利用key的上下文信息。
因此作者首先在key上采用3x3的卷积来建模静态上下文信息,然后将query和上下文信息建模之后的key进行concat,再使用两个连续的1x1卷积来自我注意,生成动态上下文。静态和动态上下文信息最终被融合为输出。(简单的说,就是作者先用卷积来提取了局部了信息,从而充分发掘了key内部的静态上下文信息)
方法
3.1. Multi-head Self-attention
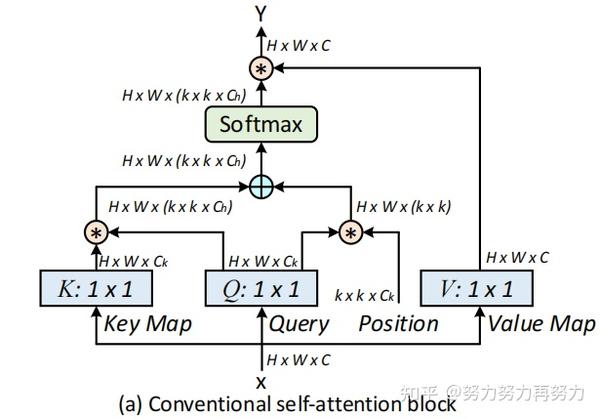
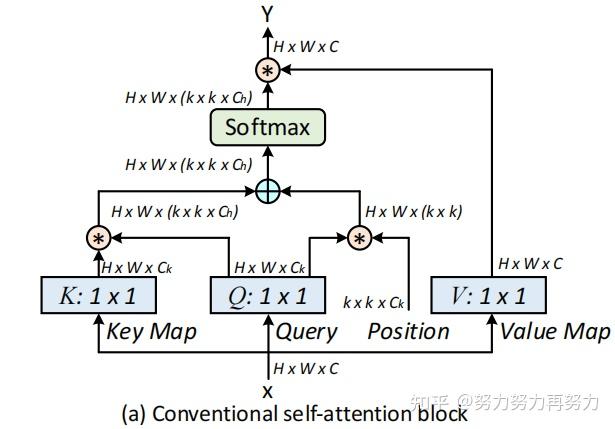
目前在视觉的backbone中,通用的可扩展的局部多头自我注意(scalable local multi-head self-attention),如上图所示。首先用1x1的卷积上X映射到Q、K、V三个不同的空间,Q和K进行相乘获得局部的关系矩阵:

由于原始的Self-Attention对输入特征的位置是不敏感的,所以还需要在Q上加上位置信息,然后将结果与关系矩阵相加:
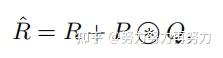
接着,我们还需要对上面得到的结果进行归一化,得到Attention Map:
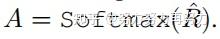
得到Attention Map之后,我们需要将kxk的局部信息进行聚合,然后与V相乘,得到Attention之后的结果:
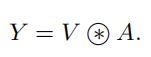
3.2. Contextual Transformer Block
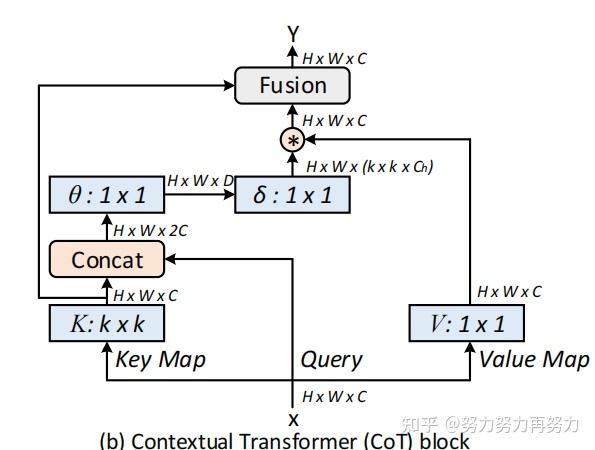

传统的Self-Attention可以很好地触发不同空间位置的特征交互。然而,在传统的Self-Attention机制中,所有的query-key关系都是通过独立的quey-key pair学习的,没有探索两者之间的丰富上下文,这极大的限制了视觉表示学习。
因此,作者提出了CoT Block,如上图所示,这个结构将上下文信息的挖掘和Self-Attention的学习聚合到了一个结构中。
首先对于输入特征,首先定义了三个变量(这里只是将V进行了特征的映射,Q和K还是采用了原来的X值)。作者首先在K上进行了kxk的分组卷积,来获得具备局部上下文信息表示的K,(记作),这个可以看做是在局部信息上进行了静态的建模。接着作者将和Q进行了concat,然后对concat的结果进行了两次连续的卷积操作:
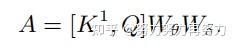
不同于传统的Self-Attention,这里的A矩阵是由query信息和局部上下文信息交互得到的,而不只是建模了query和key之间的关系。换句话说,就是通过局部上下文建模的引导,增强了自注意力机制。
然后,作者将这个Attention Map和V进行了相乘,得到了动态上下文建模的:
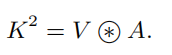
最后CoT的结果为局部静态上下文建模的和全局动态上下文建模的fuse之后的结果。
3.3. Contextual Transformer Networks
CoT的设计是一个统一的自我关注的构建块,可以作为ConvNet中标准卷积的替代品。
因此,作者用CoT代替了ResNet和ResNeXt结构中的3x3卷积,形成了CoTNet和CoTNeXt。
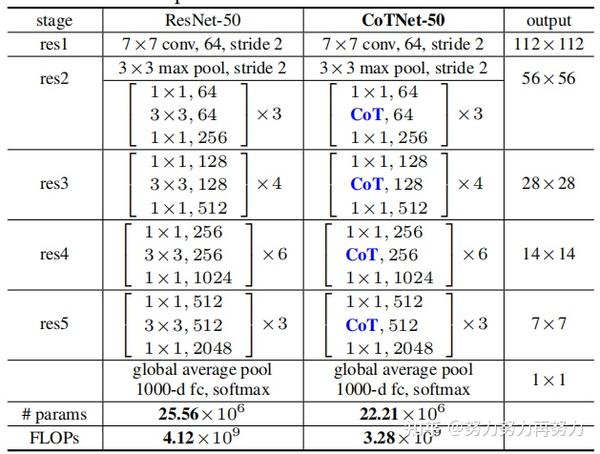

可以看出,CoTNet-50的参数和计算量比ResNet-50略小。
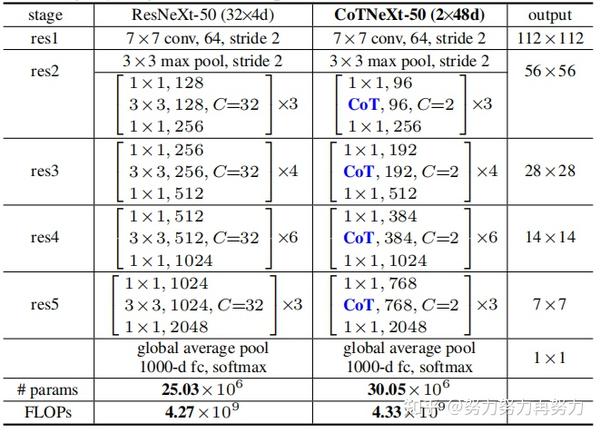

与ResNeXt-50相比,CoTNeXt-50的参数数量稍多,但与FLOPs相似。
实验
4.1. Image Recognition
4.1.1. Performance
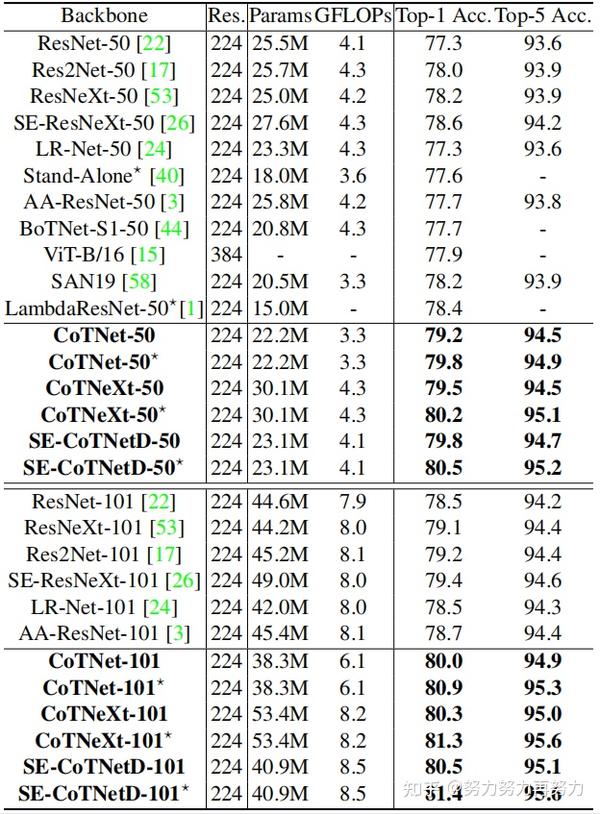

如上表所示,在相同深度(50层或101层)下,top-1和top-5结果都表明本文的方法比卷积网络和Attention-based网络性能更好。
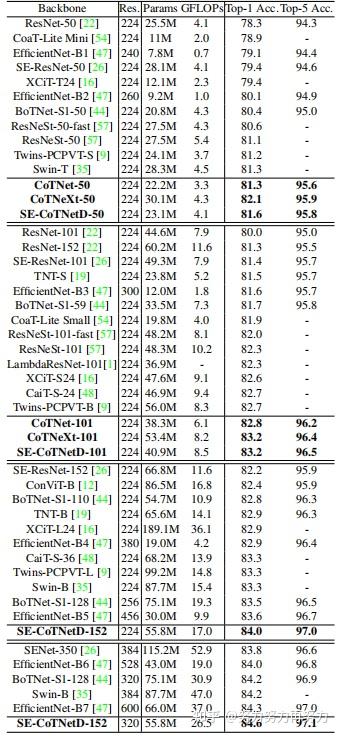
上表表明了,本文方法相比于一些SOTA方法,也有比较大的性能优势。
4.1.2. Inference Time vs. Accuracy
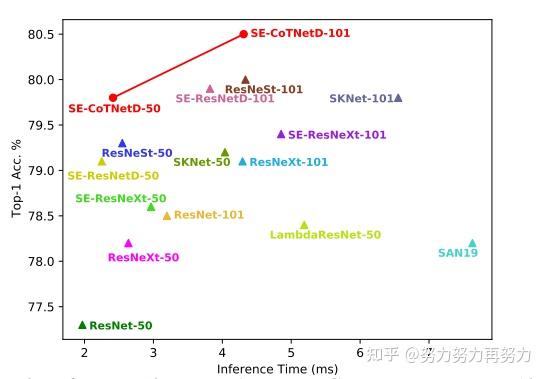

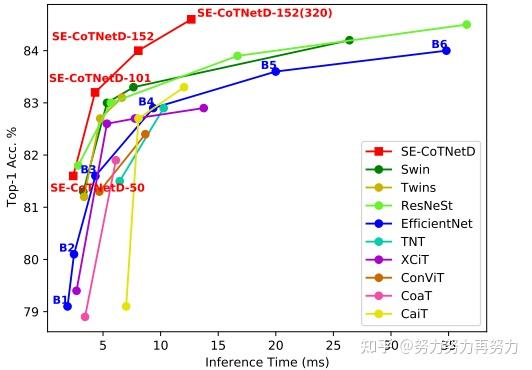

上表图展示了CoTNet和SOTA视觉backbone的inference time-accuracy 曲线。可以看出,CoTNet可以在更少的inference时间上达到更高的top-1准确率。
4.1.3. Ablation Study
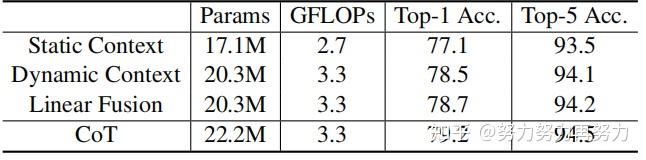

上表展示了不同模块ablation的实验结果,可以看出,静态上下文、动态上下文和线性融合都有各自的作用。
4.2. Object Detection
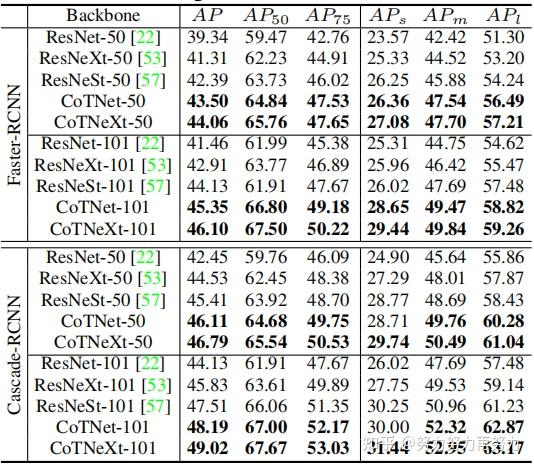

上表展示了COCO数据集上在不同预训练backbone中使用Faster-RCNN和Cascade-RCNN进行目标检测的性能比较,可以看出CoTNet相比于ResNet,性能提升明显。
4.3. Instance Segmentation
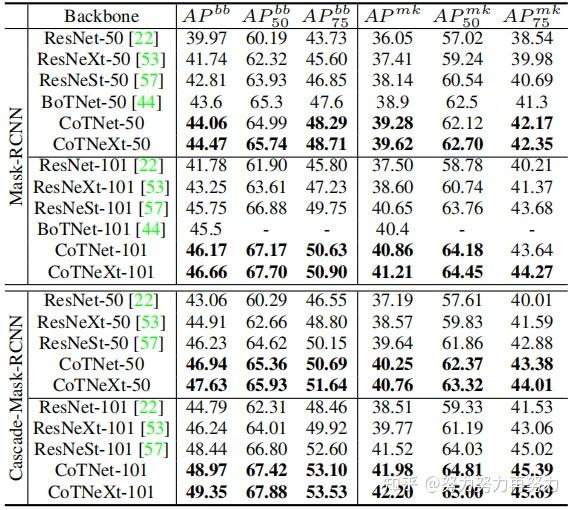

上表展示了具有不同预训练的视觉backbone的Mask-RCNN,在COCO数据集上的实例分割的性能。可以看出CoTNet相比于ResNet,性能提升明显。
总结
作者任务传统的Self-Attention在进行计算Attention Map的时候,只考虑了Q和K的关系,而忽略了K内部的上下文信息,因此作者提出了CoT 模块,利用输入key的上下文信息来指导自注意力的学习。
通过将ResNet结构中的3x3卷积替换成CoT模块,作者提出了CoTNet,并在分类、检测、分割任务上都做了实验,都取得了不错的性能。
═—═—═—═—═—分割线═—═—═—═—═—
机器学习/深度学习算法/计算机视觉/多模态交流群
群里每天都会进行论文的分享!!!
已建立机器学习/深度学习算法/计算机视觉/多模态交流群微信交流群!
想要进交流群进行学习的同学,可以直接扫github的图片(https://github.com/xmu-xiaoma666/External-Attention-pytorch/blob/master/tmpimg/wechat.jpg)
可以直接加我的微信号:xmu_xiaoma。
加的时候备注一下:**知乎+学校+昵称 **(不加备注不会接受同意,望谅解)。
会定期在群里分享一些近期的论文,欢迎大家一起学习交流哈~~~
欢迎大家关注公众号:FightingCV
强烈推荐大家关注努力努力再努力账号和FightingCV微信公众号,可以快速了解到最新优质的干货资源。

