
兼容性测试,你们怎么玩?


这样的问题可曾遇到?
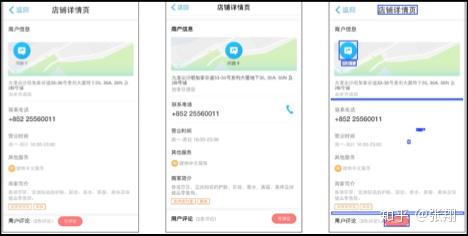

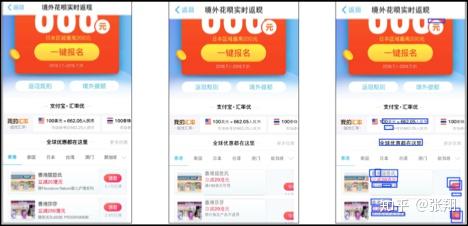

我们可能经常遇到兼容性问题,例如:
- 字体不对了
- 按钮位置不对了
- 某些内容展示不出了
- 内容超长换行了
- 按钮功能失效了
......
我们对兼容性的认识是什么?
兼容性的定义是什么?
百度百科
网页兼容性:指网页在各种浏览器上的显示效果可能不一致而产生浏览器和网页间的兼容问题
我们做兼容性测试的时候,一般是怎么做的呢?
首先组合所有的机型、浏览器、软件版本...
在不同的组合上,不断的做功能测试,试图找出看起来不对的地方。
然后我们会和开发一起研究,应该怎么加一下兼容性代码,进行容错。
而这段代码是否引起了其他组合上的兼容性问题,我们还需要做回归。
上线后,还总有一些漏测的地方。
真tm苦逼啊...
针对兼容性问题,我们的质量理念是什么?
>> 兼容性问题是测出来的,不是设计出来的
- 兼容性错误千奇百怪的,只有case by case发现问题并解决
- 机型/浏览器/CSS/JS/React… 组合越来越多,无法事先设计容错代码,验证成本非常高
>> 兼容性问题是看出来的,至少让它们看起来一样
- 兼容性体现出的不一样,是“看”出来的,属于图像领域
- 兼容性是找出“鹤立鸡群”、“与众不同”的少数派
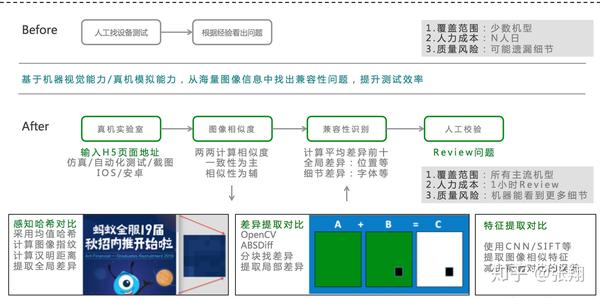
更聪明的做兼容性测试
>>> 真机实验室
首先我们在真机实验室进行仿真,解决机型/软件版本等组合问题;
并通过“录制-运行”自动化用例,在各组合上进行人机交互,触发被测对象的变化;
针对被测对象的每一个变化,进行“截图”
>>> 图像相似度与兼容性识别
在我们的理念里面,绝大多数的兼容性问题,是出现在特定的少量场景下的。
所以我们会从不同兼容性环境下面的100张图片中,找出最不一样的那几张。
所以我们的兼容性识别算法特别简单而有效:
- 计算每个图片和其他图片质检的相似度。
- 找出平均相似度最低的那几个图片,认为大概率出现兼容性问题。
在图像相似度部分,我们综合考量了以下方法:
<感知哈希>
简单来说,通过把图片压缩成8x8或32x32像素,形成一个64或1024位的指纹。在通过均值哈希、差异哈希以及更多变种,对指纹进行编码。再通过两个图片之间指纹编码的汉明距离,得出相似度。
把这种算法抽象到应用层面看,就是让两个图片在“全局宏观层面”,看是否存在不一样。


<差异提取>
简单来说,把两张图片叠加到一起,进行层叠消融的操作,找出“局部细节层面”的不一样。
在这种方法下,对分辨率差距较大的两张图片,容易出现误识别。我们在这个方法的实际应用中,会根据机型的分辨率进行分组后,再进行差异提取。
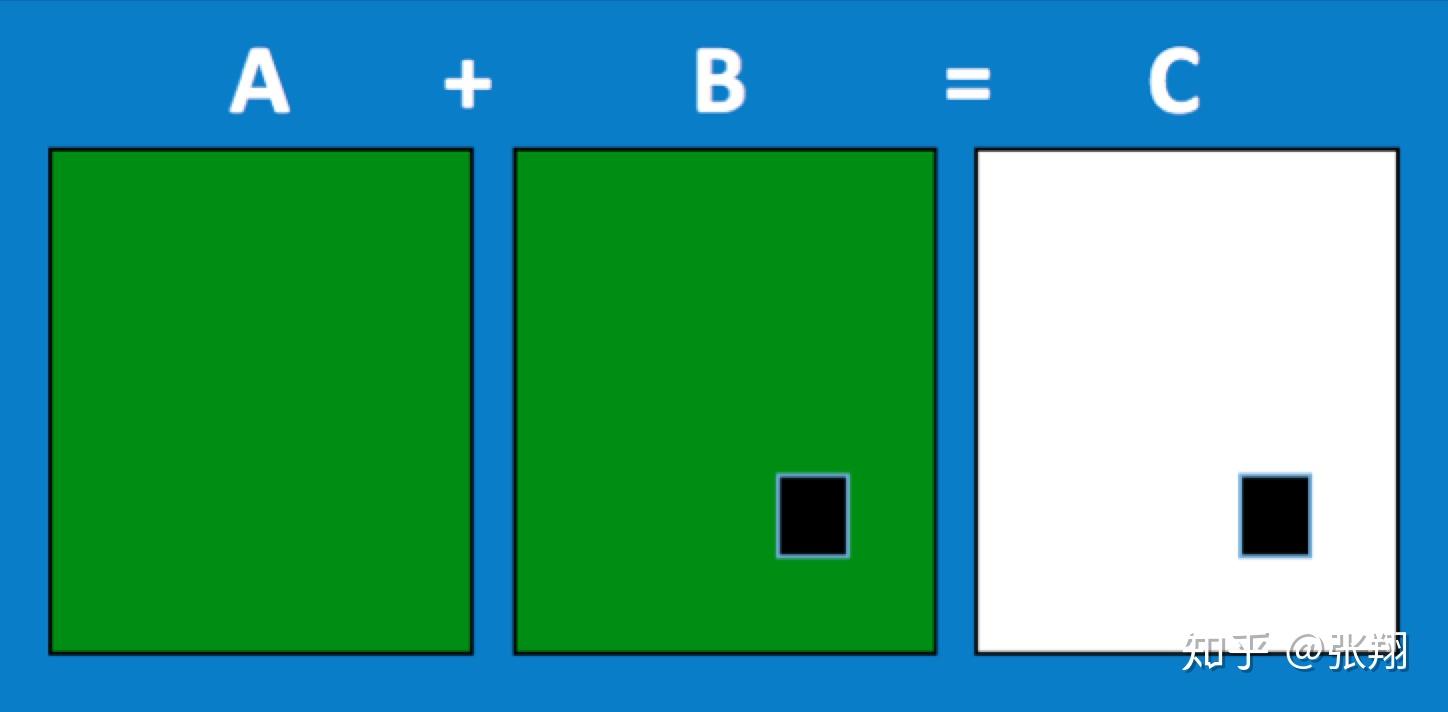

<综合模型>
在局部特征提取上,我们也尝试了CNN/SIFT等方式,但最后并未投入应用:CNN/SIFT在应对旋转、裁剪、压缩等情况下,能够做出很好的相似度识别;而在兼容性场景下,不存在旋转、裁剪、压缩等情况,所以也无需通过CNN等耗时的算法做特征提取,寻找局部差异。
在兼容性的应用场景下,也不是特别需要提高两张图片在“一致性”、“相似度”上的准确率,因为我们是从很多图片里面,找出最不一样的那一个。
在算法调研期间,也尝试过其他的算法模型,而经过我们的实验,最后还是采用了“感知哈希”和“差异提取”这两种效率最高的方法。在相同分辨率下使用“差异提取”,在不同分辨率下使用“感知哈希”。
>>> 人工校验
在机器先挑选出疑似有兼容性问题的图片之后,我们会把结果给到制作网页的PD/运营/RD等各方人员进行校验。如果发现是兼容性问题,在进行修改后,能够很快的进行“兼容性回归”,查看是否有新的影响。如果发现是Badcase,则会基于该badcase调优算法的参数(对比区块大小、压缩比等)

持续创新、效率提升
创新常常来自跨界的地方,大数据、算法在质量技术上,通常可以找到发挥“核武器”力量的场景。我常常会和团队同学说一句话:
“对新技术保持好奇心,对老问题尝试新解法”
温故而知新,可以为师矣;
