
精读深度学习论文(25) Siamese Network

人间有味是清欢
0. 前言
- 花絮:
- 之前参加kaggle比赛拿到 9/528 的成绩(我的笔记:Kaggle(1) 鲸鱼识别)。
- 比赛结束后,排名第一的大佬(比排名第二精度高了14个点……)分享了自己的解决方案:
- 解决方案地址,个人想要好好学习一下这个方案,并翻译成中文(已获得作者同意)。
- 这个方案就是基于 Siamese Network 的,所以就有了这篇笔记。
- 参考资料:
1. 素质四连
- 要解决什么问题?
- 用于处理类别多(或类别数量不确定)、每一类样本少的分类任务。
- 一般碰到的分类问题都是类别较少,每一类样本较多的情况(如ImageNet的图像分类任务)。
- 用了什么方法解决?
- 提出了一种思路:将输入映射为一个向量,比较向量之间的“距离”来判断两个输入之间的“分类”。
- 基于上述思路设计了 Siamese Network,每次输入两个样本计算损失函数。
- 常用的softmax只需输入一个样本就能计算对应的损失函数。
- 人脸识别中的 triplet loss,一次需要输入三个样本才能计算损失函数。
- 提出了 Constrastive Loss 用于训练。
- 效果如何?
- 本论文效果怎么样我不清楚,但在参加的kaggle竞赛中,排名第一的大佬(精度比第二名高了10个点……)就用了 Siamese Network 结构。
- 还存在什么问题?
- 2008年的论文了……就看个思路,一部分细节已经没有什么价值了。
2. 模型思路
2.1. 问题的提出与解决方案
- 分类问题:
- 一:分类数量较少,每一类的样本数量较多,如ImageNet、VOC等数据集。
- 二:分类数量较多(或无法确定具体数量),每一类样本数量较少,如人脸识别任务。
- 常用解决方案(普通图像分类模型,如VGG, ResNet等):常用于解决第一类分类问题。对第二类分类问题效果不佳。
- Metric Learning:
- 总体思路:将输入数据经过模型转换为一个向量,比较不同向量间的“距离”来判断不同输入数据之间的关系,构建损失函数。
- 不同向量间的“距离”指的是什么?
- 可以参考:CSDN文章 - 向量空间中各类距离的意义。
- 联想:感觉跟NLP中的 word2vec 一个思路。
2.2. 数学符号描述
- 输入数据:
X_1, X_2, X_2',其中X_1, X_2属于同一类别,X_2'与X_1, X_2属于不同类别。 - 模型
G_W:其中W就是该模型的参数,而G_W(X)的功能就是将输入数据X转换为一组向量。 - 距离
E_W(X_1, X_2):用于描述两个输入数据转换为向量后,两个向量之间的距离。 - 假设使用L1距离,则
E_W(X_1, X_2) = ||G_W(X_1) - G_W(X_2)||
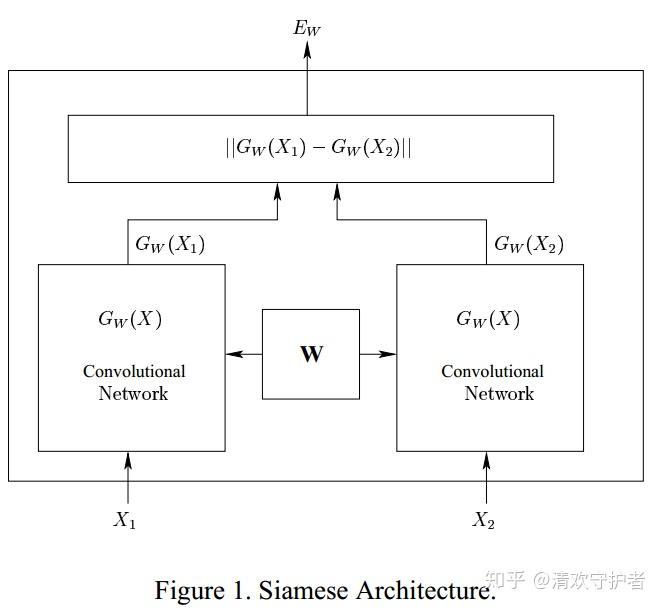
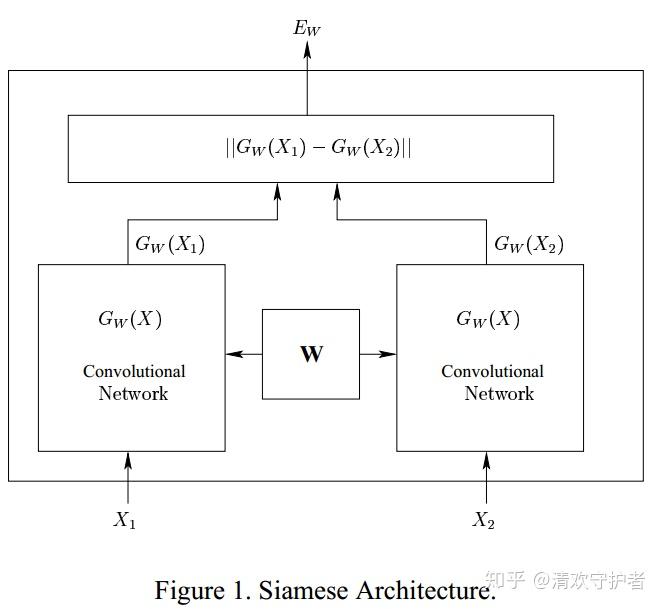
2.3. 论文截图
- 不同输入
X_1, X_2通过统一G_W得到两个向量G_W(X_1), G_W(X_2),计算两个向量之间的L1距离获得E_W。
3. Contrastive Loss 损失函数设计
- 损失函数定义如下:
Y代表X_1, X_2是否属于同一类别。输入同一类别为0,不属于同一类别为1。P代表输入数据数量。i表示当前输入数据下标。L_G代表两个输入数据属于同一类别时的损失函数(G,genuine)。L_I代表两个输入数据不属于同一类别的损失函数(I,imposter)。
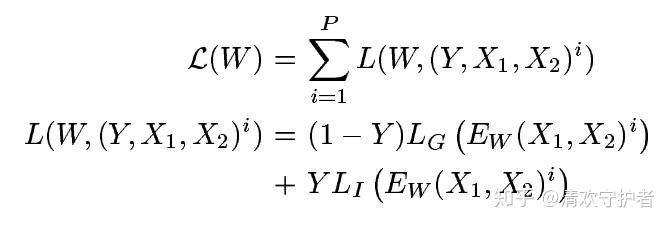

- 根据我们对两个向量间举例的定义,可以得到以下条件:
- 即不同类别向量间的距离 比 相同类别向量间距离 大。
- 两个向量之间距离越小,属于同一类别的可能性就越大。
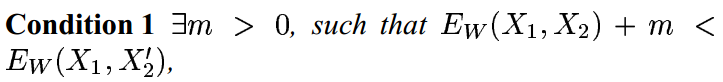

- 其他:
- 目标:优化
L时(L减小时),相同类别的E_W取值越来越小,不同类别的E_W的取值越来越大。 - 最重要的就是如何设计
L_G和L_I函数。 - 论文中的定义如下,但好像现在都不用了。
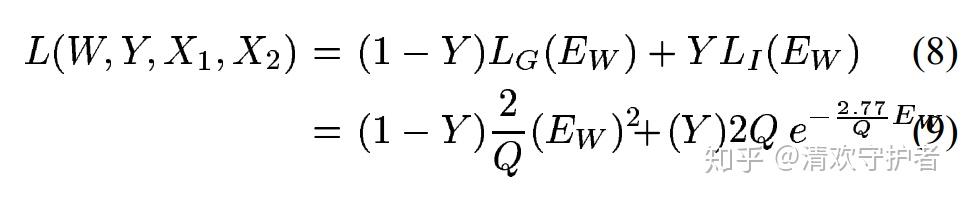

- 当我以
Contrastive Loss查找资料时,定义如下(参考这里): - 其中d表示两个向量间的距离。
- caffe中存在
constrastive loss就是这么定义的。
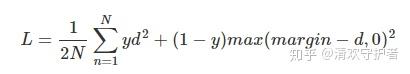
编辑于 2018-07-13 16:42
