
蒸馏神经网络到底在蒸馏什么?(设计思想篇)

阅读更多,欢迎关注公众号:paper_reader
Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean."Distilling the knowledge in a neural network." arXiv preprint arXiv:1503.02531 (2015)
1 引言
蒸馏神经网络[1],是14年Hinton提出来的一个概念,其最本质的思想是来源于昆虫记里面的故事:
“蝴蝶以毛毛虫的形式吃树叶积攒能量逐渐成长,最后变换成蝴蝶这一终极形态来完成繁殖。”
虽然是同一个个体,但是在面对不同环境以及不同任务时,个体的形态却是非常不同。不同的形态是为了完成特异性的任务而产生的变化,从而使个体能够更好的适应新的环境。
比如毛毛虫的形态是为了更方便的吃树叶,积攒能量,但是为了增大活动范围提高繁殖几率,毛毛虫要变成蝴蝶来完成这样的繁殖任务。蒸馏神经网络,其本质上就是要完成一个从毛毛虫到蝴蝶的转变。
因为在使用神经网络时,训练时候的模型和实际应用的模型往往是相同的,就好像一直是一个毛毛虫,既做了吃树叶积累能量的事情,又去做繁殖这项任务,既臃肿又效率低下。
所以使用同样形态的模型,一方面会导致模型不能针对特定性的任务来快速学习,另一方面实际应用中如果也是用训练时非常庞大的模型会造成使用开销负担过重。
蒸馏神经网络想做的事情,本质上更接近于迁移学习(Transfer Learning [2]),当然也可从模型压缩(Model Compression)[3]的角度取理解蒸馏神经网络。
Hinton的这篇论文严谨的数学思想推导并不复杂,但是主要是通过巧妙的实验设计来验证了蒸馏神经网络的可行性,所以本专题主要从蒸馏的思想以及实验的设计来介绍蒸馏神经网络。而本文主要介绍设计思想部分。
2 设计思想
在用神经网络训练大规模数据集时,为了处理复杂的数据分布:一种做法是建立复杂的神经网络模型,例如含有上百层的残差网络,这种复杂的网络往往含有多达几百万个参数;
另一种做法往往会混合多种模型,将几个大规模的神经网络在同一个数据集上训练好,然后综合(ensemble)多个模型,得到最终的分类结果。
但是这种复杂模型,一是在新的场景下重新训练成本过高,二是由于模型过于庞大而难以大规模部署(deployment)。
所以,最基本的想法就是将大模型学习出来的知识作为先验,将先验知识传递到小规模的神经网络中,之后实际应用中部署小规模的神经网络。这样做有三点依据:
- 大规模神经网络得到的类别预测包含了数据结构间的相似性;
- 有了先验的小规模神经网络只需要很少的新场景数据就能够收敛;
- Softmax函数随着温度变量(temperature)的升高分布更均匀。
数据结构间的相似性:
神经网络模型在预测最终的分类结果时,往往是通过softmax函数产生概率分布的:
q_i=\frac{exp(z_i/T)}{\sum_jexp(z_i/T)} (1)
这里将T定义为温度参数,是一个超参数,q_i是i类的概率值大小。
比如一个大规模网络,如ImageNet这样的大网络,能够预测上千种类别,正确类别的概率值能够达到0.9,错误类的概率值可能分布在10^-8~10^-3这个区间中。虽然每个错误类别的的概率值都很小,但是10^-3还是比10^-8高了五个数量级,这也反映了数据之间的相似性。
比如一只狗,在猫这个类别下的概率值可能是0.001,而在汽车这个类别下的概率值可能就只有0.0000001不到,这能够反映狗和猫比狗和汽车更为相似,这就是大规模神经网络能够得到的更为丰富的数据结构间的相似信息。


将大规模神经网络的soft target作为训练目标
由于大规模神经网络在训练的时候虽然是通过0-1编码来训练的,由于最后一层往往使用softmax层来产生概率分布,所以这个概率分布其实是一个比原来的0-1 编码硬目标(hard target)更软的软目标(soft target)。这个分布是由很多(0,1)之间的数值组成的。
同一个样本,用在大规模神经网络上产生的软目标来训练一个小的网络时,因为并不是直接标注的一个硬目标,学习起来会更快收敛。
更巧妙的是,这个样本我们甚至可以使用无标注的数据来训练小网络,因为大的神经网络将数据结构信息学习保存起来,小网络就可以直接从得到的soft target中来获得知识。
这个做法类似学习了样本空间嵌入(embedding)信息,从而利用空间嵌入信息学习新的网络。
随着温度上升,软目标分布更均匀
公式(1)中,T参数是一个温度超参数,按照softmax的分布来看,随着T参数的增大,这个软目标的分布更加均匀。
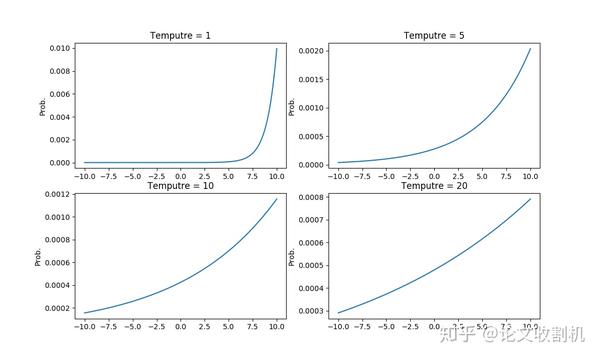

因此:
- 首先用较大的T值来训练模型,这时候复杂的神经网络能够产生更均匀分布的软目标;
- 之后小规模的神经网络用相同的T值来学习由大规模神经产生的软目标,接近这个软目标从而学习到数据的结构分布特征;
- 最后在实际应用中,将T值恢复到1,让类别概率偏向正确类别。
所以,蒸馏神经网络取名为蒸馏(Distill),其实是一个非常形象的过程。
我们把数据结构信息和数据本身当作一个混合物,分布信息通过概率分布被分离出来。首先,T值很大,相当于用很高的温度将关键的分布信息从原有的数据中分离,之后在同样的温度下用新模型融合蒸馏出来的数据分布,最后恢复温度,让两者充分融合。这也可以看成Prof. Hinton将这一个迁移学习过程命名为蒸馏的原因。
阅读更多,欢迎关注公众号:paper_reader
http://weixin.qq.com/r/LSiAmBnEvETDrV37930- (二维码自动识别)
参考文献:
[1] Hinton,Geoffrey, Oriol Vinyals, and Jeff Dean. "Distilling the knowledge in aneural network." arXiv preprint arXiv:1503.02531 (2015).
[2] Pan,Sinno Jialin, and Qiang Yang. "A survey on transfer learning." IEEE Transactionson knowledge and data engineering 22.10 (2010): 1345-1359.
[3] Buciluǎ, Cristian, Rich Caruana, andAlexandru Niculescu-Mizil. "Model compression." Proceedings of the12th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2006.