
ISO随便开!神经网络学习降噪算法解析

在做机身测试时,高ISO时的噪声表现一定是大家的关注重点,但从噪声的构建来看,弱光下很大程度的噪声都源自传感器自身的光电结构(散粒噪声的主要来源之一就是光子在传感器表面随即入射产生的光电子),同时也严格受制于制造工艺(热噪声、闪烁噪声、暗电流、光响应非一致性等现象,以及涉及带隙基准源、参考电压模块、列放大、模数转换等硬件设计),也就是说,硬件端解决噪声的唯一方法就是时间,等待半导体进步的时间。
但麻烦的是,我们目前已经接近摸到成像传感器的天花板,这个部分以前我比较详细分析过,就不再延伸了,当然,通过增大传感器面积来硬怼还有救,但这明显无视了成本和营销的问题,纯属天方夜谭满嘴跑航母,所以对于图像降噪,未来的发展势必将会以软件算法为绝对核心。


对摄影来说,我们的目的很单纯:弱光高ISO拍摄的照片跟低ISO效果接近就行,这个或许硬件端很长时间甚至不可能达到境界,在当下的AI深度学习算法加持下,已经基本实现了……NVIDIA最近跟芬兰阿尔托大学和美国麻省理工合作,使用Tesla P100 GPU集群,在谷歌TensorFlow学习系统下以cuDNN加速库,专门针对图像降噪领域进行了深度学习算法研究。
这次研究与以往的降噪学习不同点在于,一般的神经网络深度学习需要一个目标值,以图像降噪处理来说,就是需要一个ISO 100时的高信噪比目标值,让ISO 12800的输入值通过算法来达到与之近似的水准。但NVIDIA这一套新算法直接以高噪声输入为源进行学习,最终得到的结果与传统方案几乎一致,而且因为不需要目标值,结构更简单,所以速度明显更快。
基本原理:从信息学来看,弱光下的单次低噪声长曝,就是多次高噪声短时曝光的均值,因此,针对不同的情况,单纯使用不同的损失函数来“盲恢复”数据可以大大减少开销(不用再去学习低噪声目标值),训练效率大大提高。
所以,问题的关键在损失函数上了,首先是最简单的高斯噪声,因为是非常符合中心化处理流程的正态分布,在这里使用的损失函数为:

在本方案中为L2损失函数,这个函数的最小值会出现在符合算数平均值分布的对象中,而fθ (x)代表神经网络算法,x,y为输入源组。这个训练采用RED30网络结构,训练素材为50000张照片的256X256像素区域裁剪图,高斯噪声均方差随机取值0-50:
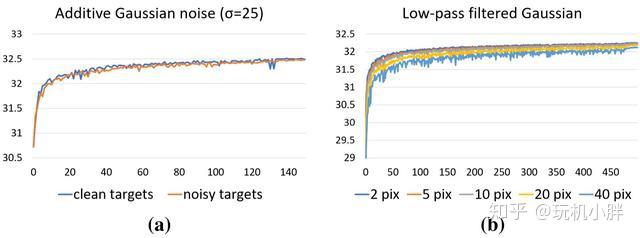

上图a中的蓝色曲线是以低噪声图像为学习目标的曲线,橙色则是以输入的高噪声图像为源的曲线,可以看到两条曲线的重合率非常高,换句话说就是在高斯噪声这个模型下,NVIDIA的这套方案效率很高,完全不输传统方案。
图b则是将高噪声的输入源图像进一步用不同像素宽度的低通滤镜来进行模糊化(原图与10像素宽度低通过滤的区别对比如下),然后再使用神经网络学习来复原,可以看到低频噪声的恢复难度更高,但最终效果差别也不算很巨大。


除了高斯分布噪声之外,另外还加入了泊松分布噪声分布和二项分布噪声的测试,泊松分布其实很有意义,因为散粒噪声就基本服从于泊松分布,虽然也符合数据中心化流程,但它的强度与信号值正相关(以散粒噪声为例,它的取值就是信号值的平方根),损失函数依然是L2,噪声幅度为0-50。而二项分布噪声的训练方法与泊松分布噪声类似,但变量取值0-0.95,以下为对比图。


从左到右的每一列分别表示低噪声原图、高噪声输入图、本算法结果和各自相应的常规降噪算法结果。第一个行是高斯分布噪声,对比方案为BM3D,这个很熟悉了吧,就不多说了;第二行是泊松分布噪声,对比方案是ANSC:安斯科姆逆变换。安斯科姆变换在极低光照成像(比如航天、X光等)中应用很广,它的主要功能就是把服从泊松分布的信息转换为接近高斯分布的类型,而它的逆变换就主要用于降噪;第三行是二项分布噪声,对比方案是Deep Image Prior(DIP),这是一个非学习类的方案,但也是目前新晋(2017年发布)比较出色的“盲降噪”算法之一。
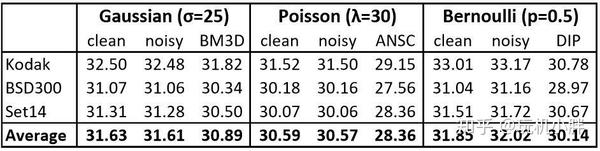

这就是三种分布噪声的的信噪比对比,数值越高越好。可以看到noisy选项,也即直接对高噪声输入源进行训练学习得到的结果,并不会比clean选项,也就是以低噪声目标值训练学习来得差,高斯/泊松/二项分布两者的差别只有-0.02dB/-0.02db/+0.17dB,二项分布噪声的测试结果甚至还更好,而与BM3D、ANSC、DIP的对比来看都有不同程度的领先,而且随后还从RED30切换到了更简单的U-Net结构,训练速度直接加快了10倍,结果差别也极小(高斯分布噪声降噪只比RED30结构的信噪比低0.2dB),所以在黑白噪声的抑制上,NVIDIA这套新算法确实相当厉害。
但,在数字成像系统里并不一定只有黑白噪声,更有可能出现随机赋值的彩色脉冲噪声,为了测试这个项目,先将有p=(0,1)的像素以[0,1]^3为函数进行随机色彩偏移,也就是p值越高,变成彩色噪点的像素越多,信噪比越低,像素偏色变化幅度呈狄拉克函数单峰型,噪点分布为均匀分布。在这个训练中使用了新的损失函数L0:
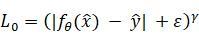
其中ε=10的-8次方,γ(Gamma)值在训练中从2到0线性下降,这个损失函数在脉冲噪声的训练和降噪实用中都有着还不错的效果:


对一张p=0.7的原图进行计算,L0函数可获得28.43dB的输出值,以低噪声目标值训练的方案所获取的也不过28.86dB,差别很小。
可以看到之前在高斯、泊松和二项分布噪声中表现很不错的L2损失函数在这个项目里栽了跟头,画面灰度太高。而另一个L1损失函数表达式为:

可以看到这个损失函数可恢复目标的中位值,对于有大量数据溢出(50%以内)的对象尤其有用。在脉冲噪声测试中p值为70时,L1的信噪比下降也很厉害,但稍好于L2。下图为脉冲噪声中L0、L1损失函数与p值、信噪比的变化曲线:


可以看到在p值接近0.5时,两者的差别不大,但超过0.5之后就是L0的天下了。事实上L1在本项目中的主要应用是图像文字消除:在图像上有0-0.5的比例像素存在被文本覆盖,而且文本为与原像素位置无关的彩色,这种情况下L2损失函数会取文本颜色的均值(中灰色)和正确色调的线性结合值,而且色差越大数值越大,最终成像呈现出来就是画面偏灰:


p=0.25时,可以看到有大量有色文字出现在画面中,但它的覆盖像素数始终是小于等于未受影响的像素数,这时候取中位值的L1损失函数显然效率更高,可以看到上图的对比,L1的信噪比L2高了8.86dB,只比以无覆盖的清晰照片为学习对象的训练法低了0.07dB。
这项研究对生产力的影响还能延伸到模型渲染领域,以在3D行业广泛应用的蒙特卡洛光线追迹为例,这项技术在有复杂模型的情况下噪波阈值的影响非常明显,阈值越小,画面噪声越小,画面越精细,但相应的渲染速度就会明显增加,除此之外就是通过大幅增加每像素采样次数来提高信噪比,而AI介入的神经网络深度学习同样可以应用在这个领域,而且效率还相当高。
首先,一如既往地要引入新的损失函数,因为是三维渲染,所以命名为LHDR,具体公式如下:
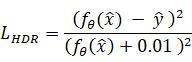
HDR顾名思义就是高动态范围,但HDR最终还是要顾及8bit显示输出,所以需要重新做色调映射,之前的L2损失函数存在映射非线性的问题,所以才有了这个变式,由来有点复杂,就不详细解读了,但这个损失函数的效果很不错,蒙特卡洛测试的参考对象是由8块Tesla P100 GPU加一颗40核心至强处理器渲染了40分钟,每像素采样次数达到131072次,几乎没有噪声的960 X 540分辨率图像,输入源为每像素64次采样,信噪比23.93dB的图像(下图a)。
使用LHDR损失函数分别以输入源、参考对象为目标进行神经网络训练,最终输出结果对比如下:


上图b是以高噪声图源为基础的训练计算结果,可以看到信噪比仅比参照131072次采样值来训练的图c低0.53dB,这两套方法在同一块Tesla P100 GPU上进行训练了12小时左右,为达到相同的信噪比输出水准(31.83dB),针对高噪声源的训练需要迭代4000次,而以低噪声目标值为源的训练只需迭代2000次,也就是说以高噪声为基础的神经网络训练方法,收敛率不及传统方法。但别忘了,得到低噪声目标值也需要很长的时间(本案例虽然只花了40分钟,但也要看看具体硬件配置啊亲),所以这项研究依然是很有现实意义。
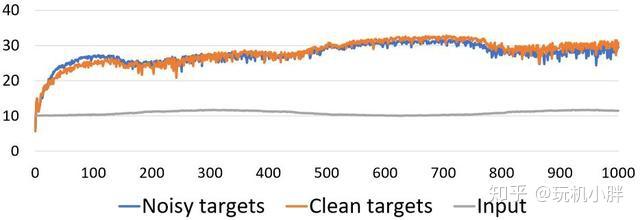

本次测试还加入了1000帧的动态图像降噪测试,因为目标是“动态”的,所以每像素的采样率都很低,在Titan V GPU上一帧512 X 512像素图像每像素采样8次需要190ms。以256 X 256像素在随机位置进行训练,一次需要11.25ms,总计8次,再加上机内渲染、均值输出,每一帧约耗时500ms(包括渲染、训练和输出到界面)。以低噪声目标值来进行匹配训练则需要越7分钟才能有1帧,但两者逐帧信噪比对比基本相同(如上图),效率差别一眼便知。
这套神经网络训练法在医疗行业也有一定程度的愿景,比如严重依赖压缩感知采样理论的核磁共振,所谓压缩感知就是用远小于奈奎斯特采样定律的采样率进行采样,并通过非线性重建算法来恢复信号,在核磁共振的应用中就是更少的照射量、更快的成像速度以及避免运动伪影等问题。
针对核磁共振成像,这套算法使用了2种损失函数,其一是L2,其二为:

这个函数看起来比较复杂,其实就是把输入源的fθ(x)进行傅里叶变换(空域变频域)后,再使用Rx替换输入源里的非零频率,最后再从频域逆变回空域,基本可以看做是L2损失函数的升级变式。训练方法是采用4936张256 X 256分辨率照片以U-net结构进行训练,在NVIDIA Tesla P100 GPU上耗时13小时、迭代300次之后,以高噪声为目标的训练可以从20.03dB的输入值提升到31.1dB,相同迭代次数下以低噪声为目标的训练结果为31.14dB,差别很小。
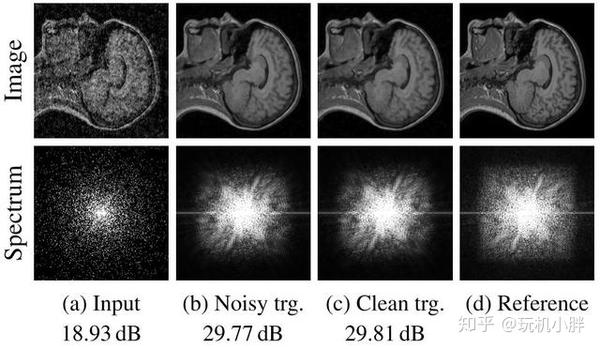

上图a为采样率下降到了奈奎斯特定律10%的输入源,可以看到光谱响应比较小,信噪比18.93dB,图b则是以图a为源的训练结果,信噪比提升到29.77dB,而图d是完全采样的低噪声参考图,图c是以图d为目标的训练结果,信噪比29.81dB。所以跟之前的测试结果类似:都是以高噪声图像为输入源,但目标分别设置为低噪声参考图像(传统训练法)和高噪声图像自身盲降噪(本次提出的新方法),在输出信噪比上几乎没有区别,所以明显后者的工作效率高出很多,具备很高的应用前景。
不过,如果单单讨论摄影中的信噪比,有时候也不一定是越高越好,因为在不涉及这些第三方的神经网络训练,只在机内降噪这个领域讨论的话,不同类型的产品就会有不同的思路,总体来说高ISO降噪就是一个信噪比和锐度的“互换游戏”而已:随便拿你手里的相机对比拍摄一下关闭和开启最高程度高感降噪的照片,很容易就会发现关闭降噪虽然噪声变大,但部分细节还是依稀可见,而开启降噪后噪声和细节都同时被抹掉了,最极端的例子就是手机,比如爵士三摄在夜间拍摄多帧降噪100%放大会是介个样子:


完全找不到噪声的同时,图像也快马赛克化了,但手机降噪算法这样设计其实没问题,因为没什么人会在手机上数毛,这种细节问题大多数人都不会在意。在电脑上看相机照片就不一样了,恐怕大多数人都会忍不住放大来看仔细欣赏,而且还要应对打印的需求,所以相机端的机内降噪并不会特别“用力”,以RX100 M6为例,它的多帧降噪也只是加强弱光手持的实用性,并顺便抹掉一些明显的彩色噪点而已。
而且噪声也并不一定是过街老鼠,在视频领域即便10bit,色带断层也不会是什么很新鲜问题,再加上目前的电影电视播放信号也都只有8bit,而且蓝光光盘等还要有YUV到RGB的转换,都会导致色带断层,而弥补这些断层的方案之一,就是填补噪声。如果看电影的时候足够认真,或者所坐等足够近,其实不难发现部分电影在一些容易出现断层色带的位置(亮度较高、颜色过渡、灯光等),会有相对更明显的噪声,比如下面的对比图:
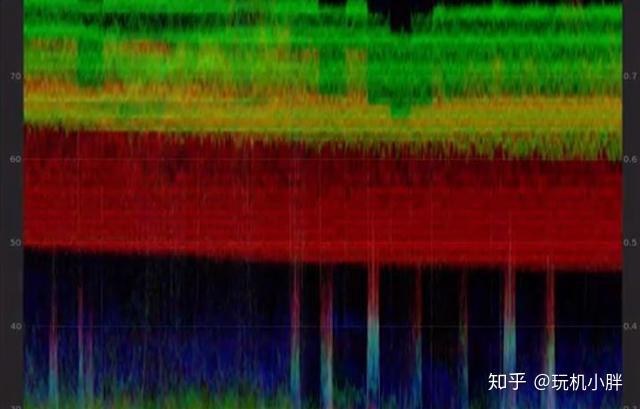

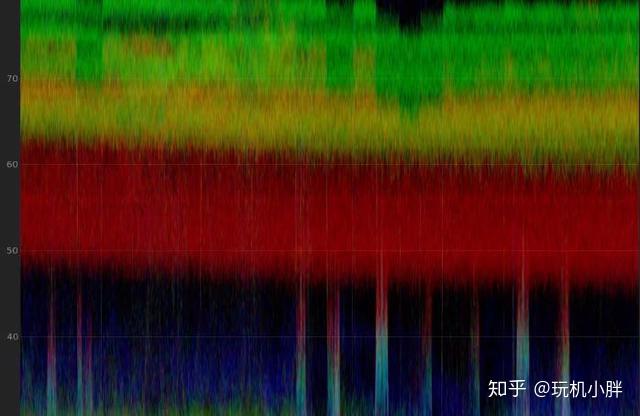

图1里比较明显的断层在填补噪声后,就得到了图2这种相对更好的效果,再加上观众对于动态视频的噪声又有颗粒感的美誉,所以在视频这个领域,噪声其实算是亦敌亦友的存在。
总的来说,现在的AI计算大环境很好,在类似NVIDIA这种硬软件都有几把刷子的厂商力推的大背景下,这些还停留在实验室端的算法距离量产应用的时间也不会太远。最近写了不少关于AI神经网络学习对图像处理的内容,关于这方面的内容以后应该还会更多,毕竟这是一个很重要的方向,也值得所有人的关注。
