【万字总结】图像处理数据增强、网络正则化方法大总:cutmix、cutout、shakedrop、mixup、 Label smoothing等(附代码)

一、目录
原文链接:
二、介绍
近年来,深度学习促进了计算机视觉领域的长足发展,在许多具有挑战性的视觉任务中取得了最先进的性能,如目标识别、语义分割、图像字幕和人体姿势估计。这些改进大部分归功于卷积神经网络(CNN),它能够学习图像的复杂层次特征表示。随着待解决任务的复杂性增加,此类模型的资源利用率也随之增加:内存占用、参数、操作计数、推理时间和功耗。现代网络通常包含数千万到数亿个学习参数,这些参数为这些任务提供了必要的表征能力,但是不断增加的表征能力也增加了过度拟合的概率,导致泛化能力差。
为了消除过度拟合的可能性,可以应用几种不同的正则化技术,例如数据增强或在激活、参数或数据中明智地添加噪声。在计算机视觉领域,数据增强由于其易于实现和有效性而几乎无处不在。简单的图像变换,如镜像或裁剪,可以用来创建新的训练数据,可以用来提高模型的鲁棒性和准确性。大型模型也可以通过在训练过程中添加噪声来正则化,无论是添加到输入、权重还是梯度中。为了提高模型精度,噪声最常见的用途之一是dropout,它会在训练期间随机地降低神经元的激活,从而阻碍特征检测器的共同适应。
与前面提到的简单增强方法不同,该文章主要介绍近年来图像处理领域数据增强和网络正则化的新方法,如Stochastic Depth , Cutout, Mixup 和 CutMix 等,并在最后给出了实现代码和比较评估结果。
三、方法
1. StochDepth
论文地址: Deep Networks with Stochastic Depth
方法简述:
深的网络在现在表现出了十分强大的能力,但是也存在许多问题。主要是梯度消散、前向传播中信息的不断衰减、训练耗时长等问题。本文主要是提出随机深度,在训练时使用较浅的深度(随机在resnet的基础上bypass掉一些层),在测试时使用较深的深度,较少训练时间,提高训练性能,最终在四个数据集上都超过了resnet原有的性能(cifar-10, cifar-100, SVHN, imageNet)。
文章主要的训练对象是残差第一篇提出的未改进的ResNet,即下图
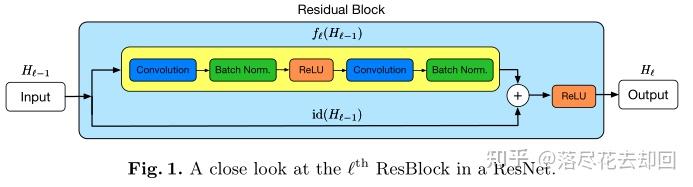

通过设置一个参数bℓ∈{0,1}(服从二项分布),将原来的残差块输入输出计算公式进行改变:
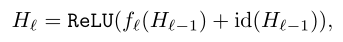
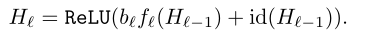
在每个mini-batch中,当bℓ=1时该残差块不作任何改变,记为存活;当bℓ=0时该残差块变为一个恒等变换。同时作者还加入了一个参数pℓ即第ℓ个残差块的存活概率,文中对各个残差块设置了线性递减的存活概率,其中第一个残差块的存活概率p0始终为1(永远不会被丢弃),最后一个残差块的存活概率pL始终为0.5,中间各残差块的存活概率计算公式为:(是线性的)
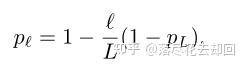
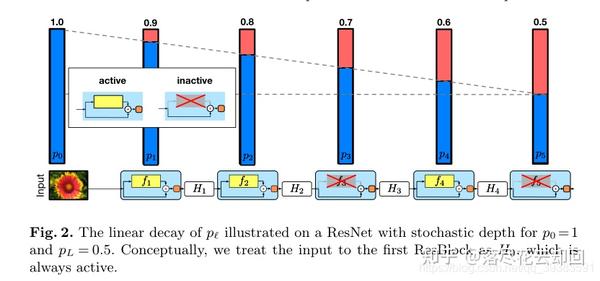

以上的随机丢弃方法只用于训练当中,在测试时仍使用深层的网络,即所有的残差块都为存活状态。
核心代码展示:
class StoDepth_BasicBlock(nn.Module):
expansion = 1
def __init__(self, prob, multFlag, inplanes, planes, stride=1, downsample=None):
super(StoDepth_BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
self.prob = prob
self.m = torch.distributions.bernoulli.Bernoulli(torch.Tensor([self.prob]))
self.multFlag = multFlag
def forward(self, x):
identity = x.clone()
if self.training:
if torch.equal(self.m.sample(), torch.ones(1)):
self.conv1.weight.requires_grad = True
self.conv2.weight.requires_grad = True
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
else:
# Resnet does not use bias terms
self.conv1.weight.requires_grad = False
self.conv2.weight.requires_grad = False
if self.downsample is not None:
identity = self.downsample(x)
out = identity
else:
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
if self.multFlag:
out = self.prob * out + identity
else:
out = out + identity
out = self.relu(out)
return out2. Label smoothing
论文地址:Rethinking the Inception Architecture for Computer Vision
方法简述:
Label smoothing 是Inception-V3提出来的,对于分类问题,常规做法时将类别做成one-hot vector,然后在网络最后一层全链接的输出后接一层softmax,softmax的输出是归一的,因此我们认为softmax的输出就是该样本属于某一类别的概率。由于标签是类别的one-hot vector, 因此表征我们已知该样本属于某一类别是概率为1的确定事件,而其他类别概率都为0。
softmax:

其中 zizi 一般叫做 logits ,即 未被归一化的对数概率 。我们用 p 代表 predicted probability,用 q 代表 groundtruth 。在分类问题中loss函数一般用交叉熵,即: cross entropy loss:
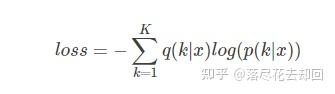
交叉熵对于logits可微,且偏导数形式简单: ∂loss∂zk=p(k)−q(k)∂loss∂zk=p(k)−q(k) ,显然梯度时有界的(-1到1)。 对于groundtruth为one-hot的情况,即每个样本只有惟一的类别,则 q(k)=δk,yq(k)=δk,y ,yy 是真实类别。其中 δδ 是Dirac函数。要用predicted label 去拟合这样的函数具有两个问题:首先,无法保证模型的泛化能力(generalizing),容易导致过拟合; 其次,全概率和零概率将鼓励所属类别和非所属类别之间的差距尽可能拉大,而由于以上可知梯度有界,因此很难adapt。这种情况源于模型过于相信预测的类别。
因此提出一种机制,即要使得模型可以 less confident 。思路如下:考虑一个与样本无关的分布 u(k)u(k) ,将我们的 label 即真实标签 q(k)q(k)变成 q′(k)q′(k) ,其中:
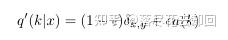
可以理解为,对于 Dirac 函数分布的真实标签,我们将它变成以如下方式获得:首先从标注的真实标签的Dirac分布中取定,然后,以一定的概率 ϵϵ ,将其替换为在 u(k)u(k) 分布中的随机变量。因此可以避免上述的问题。而 u(k)u(k) 我们可以用先验概率来充当。如果用 uniform distribution 的话就是 1/K 。该操作就叫做 label-smoothing regularization, or LSR 。
对于该操作的数学物理含义可以用交叉熵的概念说明:
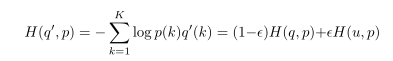
可以认为 loss 函数分别以不同的权重对 predicted label 与标注的label 的差距 以及 predicted label 与 先验分布的差距 进行惩罚。根据文章的报告,可以对分类性能有一定程度的提升。
核心代码展示:
import torch.nn as nn
import torch.nn.functional as F
class LabelSmoothingCrossEntropy(nn.Module):
def __init__(self, eps=0.1, reduction='mean'):
super(LabelSmoothingCrossEntropy, self).__init__()
self.eps = eps
self.reduction = reduction
def forward(self, output, target):
c = output.size()[-1]
log_preds = F.log_softmax(output, dim=-1)
if self.reduction=='sum':
loss = -log_preds.sum()
else:
loss = -log_preds.sum(dim=-1)
if self.reduction=='mean':
loss = loss.mean()
return loss*self.eps/c + (1-self.eps) * F.nll_loss(log_preds, target, reduction=self.reduction)3. Cutout
论文地址: Improved regularization of convolutional neural networks with cutout
方法简述:
Cutout与random earsing的出发点是一致的,都是针对机器视觉中存在的目标遮挡问题。通过对训练数据模拟遮挡,一方面能解决现实中遮挡的问题,另一方面也能让模型更好的学习利用上下文的信息。
作者描述了两种Cutout的设计理念:
- 开发了一种有针对性的方法,专门从图像的输入中删除图像的重要特征,为了鼓励网络考虑不那么突出的特征。做法为删除最大激活的特征,具体是:在训练的每个epoch过程中,保存每张图片对应的最大激活特征图(输出的最大特征激活点),在下一个训练回合,对每张图片的最大激活图进行上采样到和原图一样大,然后使用阈值划分为二值图,盖在原图上再输入到cnn中进行训练。因此,这样的操作可以有针对性的对目标进行遮挡。如下图所示。


- 对于上述操作的进一步理解:由于网络经过训练后,输出特征的最大激活点会围绕在目标区域中,并且由于有针对性的遮挡,输出的最大激活点的位置(将要遮挡的位置)将不同于本次输入的位置(原先的位置已遮挡,此时不可能被激活),也就是说,在训练的每一代中,可以围绕目标的不同区域进行动态遮挡训练。而不像之前对输入图像进行数据增强,一张图片在整个训练过程只有一种遮挡模式。该操作有些像dropout,每次训练中都随机性的选择参与训练的节点,当然也势必会带来收敛速度的减慢。
- 虽然通过理论感知,这种有针对性的遮挡要比单纯随机遮挡高效,但实际效果区别却差不多,(至于为什么效果区别不大,并不理解,可能受二值化阈值的影响,需要自适应?仍有待继续研究)反而这种增加了更多计算量和内存,得不偿失。
2. 另外一种设计理念与random erasing及其类似,但实施起来要比random erasing简单,具体操作是:选择一个固定大小的正方形区域,然后将该区域填充为0即可,为了避免全0区域对训练的影响,需要对数据中心归一化到0。并且,与random erasing不同的是,其以一定概率(50%)允许擦除区域不完全在原图像中。
核心代码展示:
import torch
import numpy as np
class Cutout(object):
"""Randomly mask out one or more patches from an image.
Args:
n_holes (int): Number of patches to cut out of each image.
length (int): The length (in pixels) of each square patch.
"""
def __init__(self, n_holes, length=8):
self.n_holes = n_holes
self.length = length
def __call__(self, img):
"""
Args:
img (Tensor): Tensor image of size (C, H, W).
Returns:
Tensor: Image with n_holes of dimension length x length cut out of it.
"""
h = img.size(1)
w = img.size(2)
mask = np.ones((h, w), np.float32)
for n in range(self.n_holes):
y = np.random.randint(h)
x = np.random.randint(w)
y1 = np.clip(y - self.length // 2, 0, h)
y2 = np.clip(y + self.length // 2, 0, h)
x1 = np.clip(x - self.length // 2, 0, w)
x2 = np.clip(x + self.length // 2, 0, w)
mask[y1: y2, x1: x2] = 0.
mask = torch.from_numpy(mask)
mask = mask.expand_as(img)
img = img * mask
return img4. DropBlock
论文地址: DropBlock: A regularization method for convolutional networks
方法简述:
Dropout是一个非常好用的优化方法,然而它仅仅适用于全连接层,因为卷积层中的元素是空间相关的。当它应用到卷积层上时,即使消除了某些元素的部分权重和偏置,但这些元素在其它地方的权重和偏置也会将它的信息传递下去。为了解决这个方法,dropblock被提出了:它类似dropout,但它不止去除某一个元素,而是去除一个区域的元素,这样它就能在卷积层中发挥作用了。实验表明,它能够较好地提高模型准确度。
自从dropout被提出后,各种神经网络的归一化方法出现了。这些方法的思想是向神经网络中塞入各种各样的噪音,以防止它对训练数据过拟合。Dropblock的思想起源于cutout,它将输入图像的部分置零以让神经网络关注更多的特征来防止过拟合。而dropblock更进一步,它在每个特征图中都应用了cutout。
Dropblock的思路和dropout很像,其主要区别在于它不是丢弃独立的随机单元,而是丢弃特征途中连续的区域。其伪代码如下:
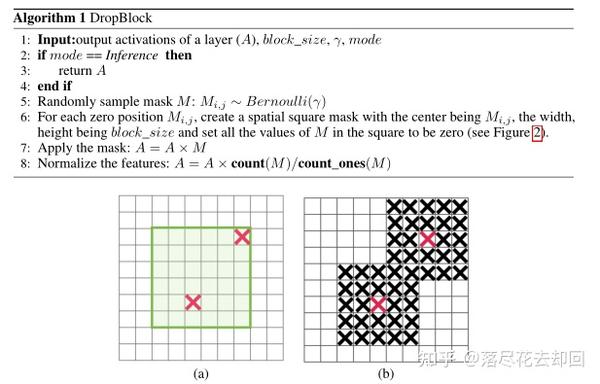

它的两个超参数为block_size和γ。前者决定了丢弃的块的大小,后者决定了丢弃多少激活的单元。经过实验,在每层使用不同的dropblock掩膜效果更好。
在实验中,我们往往在不同的特征图中都使用相同的block_size,然后使用下图公式计算γ:
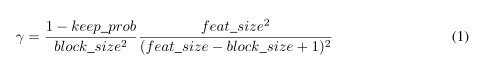

其中keep_prob即是dropout保留元素的概率,feat_size是整个图的大小。
核心代码展示:
import torch
import torch.nn.functional as F
from torch import nn
class DropBlock2D(nn.Module):
r"""Randomly zeroes 2D spatial blocks of the input tensor.
As described in the paper
`DropBlock: A regularization method for convolutional networks`_ ,
dropping whole blocks of feature map allows to remove semantic
information as compared to regular dropout.
Args:
drop_prob (float): probability of an element to be dropped.
block_size (int): size of the block to drop
Shape:
- Input: `(N, C, H, W)`
- Output: `(N, C, H, W)`
.. _DropBlock: A regularization method for convolutional networks:
https://arxiv.org/abs/1810.12890
"""
def __init__(self, drop_prob, block_size):
super(DropBlock2D, self).__init__()
self.drop_prob = drop_prob
self.block_size = block_size
def forward(self, x):
# shape: (bsize, channels, height, width)
assert x.dim() == 4, \
"Expected input with 4 dimensions (bsize, channels, height, width)"
if not self.training or self.drop_prob == 0.:
return x
else:
# get gamma value
gamma = self._compute_gamma(x)
# sample mask
mask = (torch.rand(x.shape[0], *x.shape[2:]) < gamma).float()
# place mask on input device
mask = mask.to(x.device)
# compute block mask
block_mask = self._compute_block_mask(mask)
# apply block mask
out = x * block_mask[:, None, :, :]
# scale output
out = out * block_mask.numel() / block_mask.sum()
return out
def _compute_block_mask(self, mask):
block_mask = F.max_pool2d(input=mask[:, None, :, :],
kernel_size=(self.block_size, self.block_size),
stride=(1, 1),
padding=self.block_size // 2)
if self.block_size % 2 == 0:
block_mask = block_mask[:, :, :-1, :-1]
block_mask = 1 - block_mask.squeeze(1)
return block_mask
def _compute_gamma(self, x):
return self.drop_prob / (self.block_size ** 2)5. Mixup
论文地址: mixup: Beyond Empirical Risk Minimization
方法简述:
mixup是一种运用在计算机视觉中的对图像进行混类增强的算法,它可以将不同类之间的图像进行混合,从而扩充训练数据集。在介绍mixup之前,我们首先简单了解两个概念:经验风险最小化(Empirical risk minimization,ERM)和邻域风险最小化(Vicinal Risk Minimization,VRM)。
“经验风险最小化”是目前大多数网络优化都遵循的一个原则,即使用已知的经验数据(训练样本)训练得到的学习器的误差或风险,也叫作“经验误差”或“训练误差”。相对的,在新样本(未知样本)上的误差称为“泛化误差”,显然,我们希望学习器的“泛化误差”越小越好。然而,通常我们事先并不知道新样本是什么样的,实际能做的是努力使经验误差越小越好。但是,过分的减小经验误差,通常会在未知样本上产生很差的结果,也就是我们常说的“过拟合”。
关于“泛化性”,通常可以通过使用大规模训练数据来提高,但是实际上,获取有标签的大规模数据需要耗费巨大的人工成本,甚至有些情况下根本无法获取数据。解决这个问题的一个有效途径是“邻域风险最小化”,即通过先验知识构造训练样本的邻域值。一般的做法就是传统的数据增强方法,比如加噪、翻转、缩放等,但是这种做法很依赖于特定的数据集和人类的先验知识。
Mixup是一种一般性(不针对特定数据集)的邻域分布方式,可以表示为,
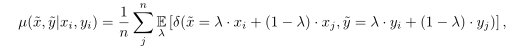

其中,λ ~Beta(α, α),α ∈ (0, ∞)。从上式可以看出,mixup以线性插值的方式来构建新的训练样本:
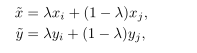
其中,(xi , yi ) 和 (xj , yj )是从原始训练数据中随机选取的两个样本,λ ∈ [0, 1]。α是mixup的超参数,控制两个样本插值的强度,当α → 0时,则退化到了ERM的情况。
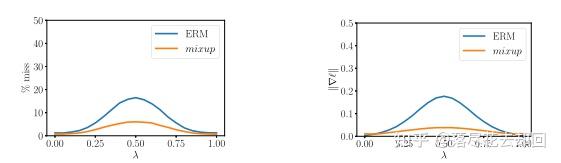

上图展示了mixup和ERM的性能对比图,可以看出mixup方法能够产生更鲁棒的结果。
核心代码展示:
def mixup_data(x, y, alpha=1.0, use_cuda=True):
'''Returns mixed inputs, pairs of targets, and lambda'''
if alpha > 0:
lam = np.random.beta(alpha, alpha)
else:
lam = 1
batch_size = x.size()[0]
if use_cuda:
index = torch.randperm(batch_size).cuda()
else:
index = torch.randperm(batch_size)
mixed_x = lam * x + (1 - lam) * x[index, :]
y_a, y_b = y, y[index]
return mixed_x, y_a, y_b, lam
def mixup_criterion(criterion, pred, y_a, y_b, lam):
return lam * criterion(pred, y_a) + (1 - lam) * criterion(pred, y_b)6. Manifold Mixup
论文地址: Manifold Mixup: Better Representations by Interpolating Hidden States
方法简述:
就是将mixup操作泛化到特征上;特征具有更高阶的语义信息,在其维度上插值可能会产生更有意义的样本。
(1)随机选网络的某层第k层(包括输入);
(2)传两批数据给网络,前向传播到第k层,得到隐藏标准gk;
(3)使用mixup
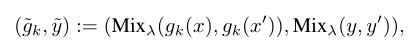
其中,

(4)继续前向传播得到输出;
(5)计算损失和梯度
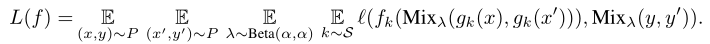

核心代码展示:
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10, per_img_std = False):
super(ResNet, self).__init__()
self.per_img_std = per_img_std
self.in_planes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.linear = nn.Linear(512*block.expansion, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x, target=None, mixup_hidden = False, mixup_alpha = 0.1, layer_mix=None):
if self.per_img_std:
x = per_image_standardization(x)
if mixup_hidden == True:
if layer_mix == None:
layer_mix = random.randint(0,2)
out = x
if layer_mix == 0:
#out = lam * out + (1 - lam) * out[index,:]
out, y_a, y_b, lam = mixup_data(out, target, mixup_alpha)
#print (out)
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
if layer_mix == 1:
#out = lam * out + (1 - lam) * out[index,:]
out, y_a, y_b, lam = mixup_data(out, target, mixup_alpha)
#print (out)
out = self.layer2(out)
if layer_mix == 2:
#out = lam * out + (1 - lam) * out[index,:]
out, y_a, y_b, lam = mixup_data(out, target, mixup_alpha)
#print (out)
out = self.layer3(out)
if layer_mix == 3:
#out = lam * out + (1 - lam) * out[index,:]
out, y_a, y_b, lam = mixup_data(out, target, mixup_alpha)
#print (out)
out = self.layer4(out)
if layer_mix == 4:
#out = lam * out + (1 - lam) * out[index,:]
out, y_a, y_b, lam = mixup_data(out, target, mixup_alpha)
#print (out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
if layer_mix == 5:
#out = lam * out + (1 - lam) * out[index,:]
out, y_a, y_b, lam = mixup_data(out, target, mixup_alpha)
lam = torch.tensor(lam).cuda()
lam = lam.repeat(y_a.size())
#d = {}
#d['out'] = out
#d['target_a'] = y_a
#d['target_b'] = y_b
#d['lam'] = lam
#print (out.shape)
#print (y_a.shape)
#print (y_b.size())
#print (lam.size())
return out, y_a, y_b, lam
else:
out = x
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out7. ShakeDrop
论文地址: ShakeDrop Regularization for Deep Residual Learning
方法简述:
来自大阪市立大学和Preferred Networks, Inc.。ShakeDrop 要比 Shake-Shake更加有效,不仅可以用到ResNeXt上,还能用到ResNet,Wide ResNet和PyramidNet上。
ShakeDrop与其他方法的比较:
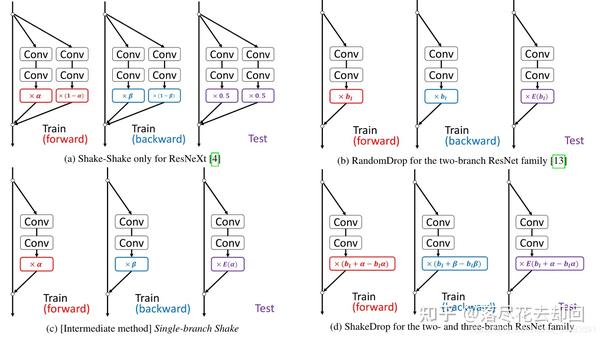
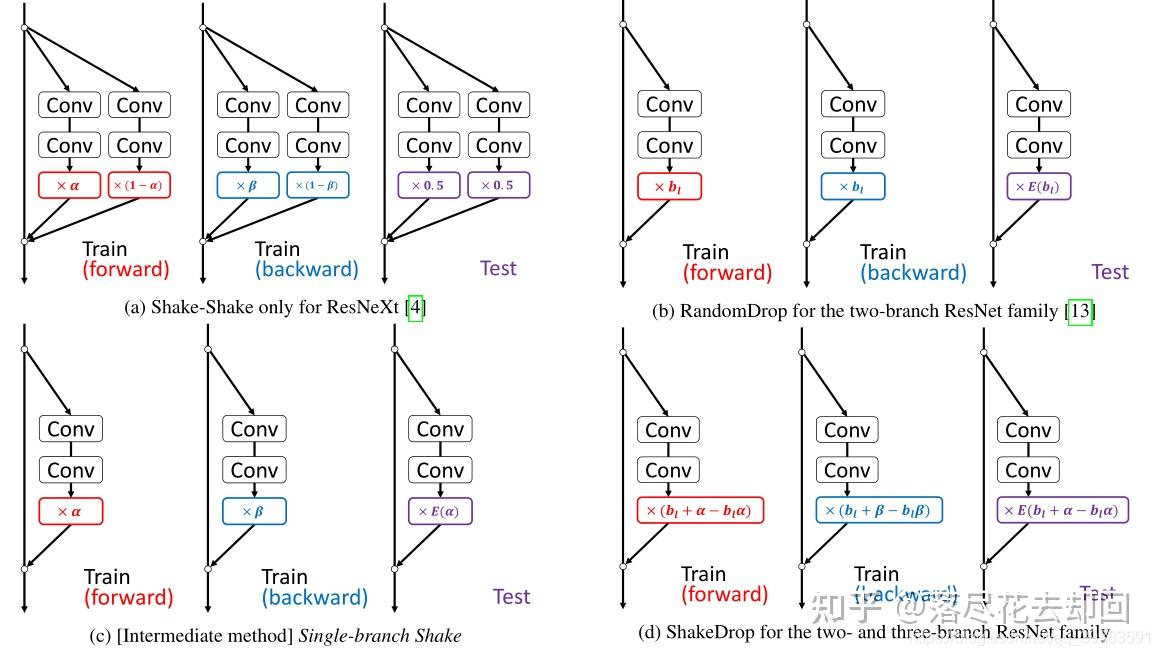
7.1 Shake-Shake
基本的ResNeXt构建块,有3个分支:
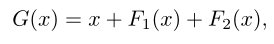
设α和β是由区间[0,1]上的均匀分布均匀抽取的独立随机系数。Shake-Shake可以写成:
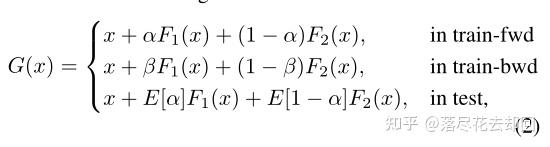

其中train-fwd和train-bwd分别表示训练的前向和后向。期望值E[α] = E[1-α] = 0.5。
为每个图像或批处理绘制α和β的值。
Shake-Shake的作者没有提供解释。
- Shake-Shake使梯度在一个分支上是原来正确计算梯度的α/β倍,在其他分支上是(1 - β)/(1 - α)倍。这个干扰似乎阻止了网络参数在局部极小值被捕获。
- Shake-Shake对两个残差分支的输出进行插值。
- 在特征空间中对两个数据进行插值,可以合成很多有意义的增广数据。因此,Shake-Shake前向传递的插值可以解释为合成合理的增强数据。
随机权重α的使用使我们能够生成许多不同的扩增数据。相反,在向后通过中,使用不同的随机权值β来干扰更新参数,期望通过增强SGD的效果,帮助避免参数陷入局部极小值。
7.2 RandomDrop
基本的ResNet构建块,它有一个两个分支架构,是:
RandomDrop通过丢弃一些随机选择的构建块,使得网络在学习中变得很浅。
输入层的第l个构建块如下所示:


其中,bl∈{0,1}是一个概率为P*(bl* =1) =E[bl] = pl的伯努利随机变量。线性衰减法则用于确定pl:

其中L为构建块的总数,PL=0.5。
RandomDrop可以被认为是Dropout的一个简化版本。主要的区别在于,RandomDrop丢掉的是层,Dropout丢掉的是元素。
7.3 ShakeDrop
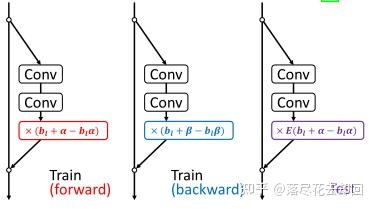
通过混合Shake-Shake和RandomDrop,就变成了ShakeDrop。
我们期望当选择原始网络时,学习被正确地促进,当选择强扰动网络时,学习被干扰,会变成上面图中的效果。
当α =β = 0时,ShakeDrop就变成了RandomDrop。
核心代码展示:
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
class ShakeDropFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, x, training=True, p_drop=0.5, alpha_range=[-1, 1]):
if training:
gate = torch.cuda.FloatTensor([0]).bernoulli_(1 - p_drop)
ctx.save_for_backward(gate)
if gate.item() == 0:
alpha = torch.cuda.FloatTensor(x.size(0)).uniform_(*alpha_range)
alpha = alpha.view(alpha.size(0), 1, 1, 1).expand_as(x)
return alpha * x
else:
return x
else:
return (1 - p_drop) * x
@staticmethod
def backward(ctx, grad_output):
gate = ctx.saved_tensors[0]
if gate.item() == 0:
beta = torch.cuda.FloatTensor(grad_output.size(0)).uniform_(0, 1)
beta = beta.view(beta.size(0), 1, 1, 1).expand_as(grad_output)
beta = Variable(beta)
return beta * grad_output, None, None, None
else:
return grad_output, None, None, None
class ShakeDrop(nn.Module):
def __init__(self, p_drop=0.5, alpha_range=[-1, 1]):
super(ShakeDrop, self).__init__()
self.p_drop = p_drop
self.alpha_range = alpha_range
def forward(self, x):
return ShakeDropFunction.apply(x, self.training, self.p_drop, self.alpha_range)8. CutMix
论文地址: CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features
方法简述:

- Mixup:将随机的两张样本按比例混合,分类的结果按比例分配;
- Cutout:随机的将样本中的部分区域cut掉,并且填充0像素值,分类的结果不变;
- CutMix:就是将一部分区域cut掉但不填充0像素而是随机填充训练集中的其他数据的区域像素值,分类结果按一定的比例分配。
上述三种数据增强的区别:cutout和cutmix就是填充区域像素值的区别;mixup和cutmix是混合两种样本方式上的区别:mixup是将两张图按比例进行插值来混合样本,cutmix是采用cut部分区域再补丁的形式去混合图像,不会有图像混合后不自然的情形。
优点:
- 在训练过程中不会出现非信息像素,从而能够提高训练效率;
- 保留了regional dropout的优势,能够关注目标的non-discriminative parts;
- 通过要求模型从局部视图识别对象,对cut区域中添加其他样本的信息,能够进一步增强模型的定位能力;
- 不会有图像混合后不自然的情形,能够提升模型分类的表现;
- 训练和推理代价保持不变。
核心代码展示:
import numpy as np
import random
from torch.utils.data.dataset import Dataset
from cutmix.utils import onehot, rand_bbox
class CutMix(Dataset):
def __init__(self, dataset, num_class, num_mix=1, beta=1., prob=1.0):
self.dataset = dataset
self.num_class = num_class
self.num_mix = num_mix
self.beta = beta
self.prob = prob
def __getitem__(self, index):
img, lb = self.dataset[index]
lb_onehot = onehot(self.num_class, lb)
for _ in range(self.num_mix):
r = np.random.rand(1)
if self.beta <= 0 or r > self.prob:
continue
# generate mixed sample
lam = np.random.beta(self.beta, self.beta)
rand_index = random.choice(range(len(self)))
img2, lb2 = self.dataset[rand_index]
lb2_onehot = onehot(self.num_class, lb2)
bbx1, bby1, bbx2, bby2 = rand_bbox(img.size(), lam)
img[:, bbx1:bbx2, bby1:bby2] = img2[:, bbx1:bbx2, bby1:bby2]
lam = 1 - ((bbx2 - bbx1) * (bby2 - bby1) / (img.size()[-1] * img.size()[-2]))
lb_onehot = lb_onehot * lam + lb2_onehot * (1. - lam)
return img, lb_onehot
def __len__(self):
return len(self.dataset)四、实验结果与完整代码




点击原文获取完整代码与使用方式:
原文链接:
