动态漫反射全局光照(Dynamic Diffuse Global Illumination)


引言
DDGI算法是一个基于Probe的GI算法,可以在动态的场景与光照中实时的生成漫反射的全局光照。完整的DDGI算法依赖于实时光线追踪的支持。但如果只需要支持静态场景与动态光源的话,也可以将光追提前到预计算阶段从而能在低端设备上运行。
光照探针(Probe)这个概念其实在现在很多GI算法中都有应用,我们首先需要在场景中摆放许多个的probe,每个probe会存储该probe所在位置接收到的光照信息,当我们需要渲染一个着色点时,只需要去查找该着色点周围的若干个probe,并将这些probe中存储的光照信息插值就可以得到着色点处的光照信息了。我们可以这样理解:probe本质上是对空间中光场函数的采样,使用probe插值计算着色点光照的过程,其实就是将采样得到的离散信号通过插值复原成原始的连续信号的过程。当然,从离散信号插值而来的连续信号和真正的原始信号之间是肯定是存在误差的,而当原始信号变化很快的地方(比如突变),该误差会尤其的大。故而在实际场景中,像室内外交界处等这样光照信息变化很大的地方,很多基于Probe的算法就会产生漏光或者漏阴影的错误。而DDGI算法则是将场景的几何信息存储进probe,从而大幅度减少漏光与漏阴影(原论文自称能避免漏光,实际上还是能看到一点点)。
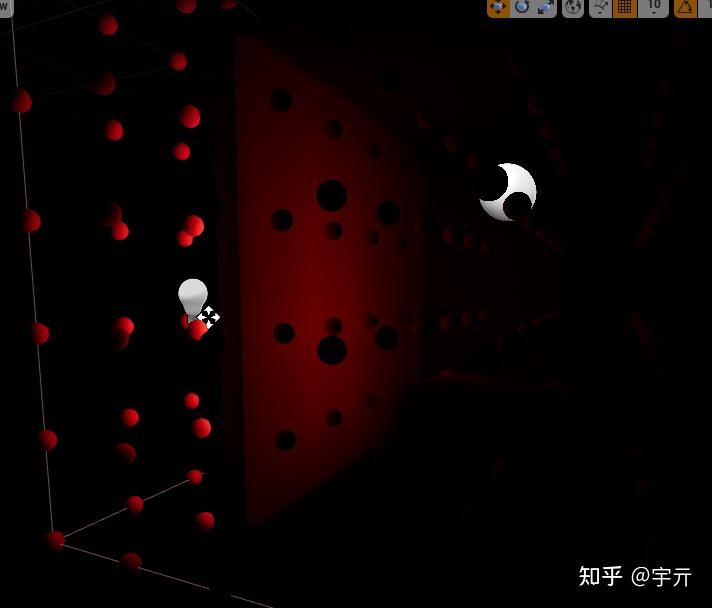
光源在墙壁外但是却照亮了墙内物体,这是因为墙内物体在采样probe的时候采样到了墙外高亮度probe,发生漏光
另外,在传统的probe算法中需要手动的摆放大量probe,这带来了额外的工作量且不支持动态场景。DDGI算法将一组probe打包成一个DDGI Volume(三维空间中的一个立方体区域),只需要将Volume拖进场景中Volume就会自动在其中放置probe,也可以将Volume绑定到摄像机上跟随摄像机移动以对摄像机附近的物体应用间接光照。
本文会分以下几个部分介绍DDGI算法:
- 第一部分介绍DDGI算法中提出的若干概念,同时会阐述DDGI Probe的数据结构,介绍DDGI的使用方式。
- 第二部分介绍如何使用DDGI Probe去渲染场景的间接光照
- 第三部分介绍如何使用实时光线追踪去生成DDGI Probe
- 第四部分介绍DDGI算法在实际应用中的若干优化技巧。
- 第五部分介绍DDGI的一个变种,在预计算阶段利用离线RayTracing烘焙出场景的几何信息,然后在运行阶段实时的更新光照。如此一来便可以在一些低端设备(甚至是移动设备)上运行,但也带来了一些问题:1. 不再支持动态场景几何。2. 需要更大的存储空间。3. 不再支持绑定到摄像机上的Volume。
阅读本文前你需要具备以下基础:
- 了解现代图形学渲染管线,至少掌握一门shader language
- 了解辐射度量学,熟悉辐射度量学常见物理量的含义。
- 了解蒙特卡洛路径追踪
- 了解阴影贴图,最好能了解一下VSM(Variance Shadow Map)
NVIDIA在UE4中实现了一个DDGI插件,叫RTXGI,该插件已经集成在了UE4的RTX分支: https://github.com/NvRTX/UnrealEngine
另外,NVIDIA也实现了一个DirectX的RTXGI SDK,不过该SDK需要申请才能下载: https://developer.nvidia.com/zh-cn/rtxgi
一、DDGI概述
1. 基本概念
DDGI Probe
摆放在场景中,记录了某一个位置的三个关于方向的函数:
- E(w) :probe从w方向的半球面接收到的irradiance。
- r(w) :probe往w方向看到的最近物体与probe距离。(存储半球面上的均值)
- r^2(w) :probe往w方向看到的最近物体与probe距离平方。(存储半球面上的均值)
DDGI Probe会将这些信息存储进一个纹理贴图中,然后通过双线性插值复原出一个关于方向的连续函数。
这里我们可以把probe理解成一个球面广角摄像机,那么r(w)和r^2(w)就可以分别看作是这个摄像机看到的深度和深度平方的加权平均,如果你曾经有了解过VSM算法,或许会对这个做法感到熟悉,VSM中我们使用深度和平方深度的均值来进行切比雪夫测试,从而估计物体处在阴影处的概率。在DDGI中,我们使用类似VSM的做法来估计probe与着色点之间存在遮挡物的概率,通过降低那些可能被遮挡的probe的权重来减少漏光与漏阴影。
后文将 E(w) 称为irradiance,将 r(w) 和 r^2(w) 直接称作depth。
DDGI Volume
一个立方体积区域,里面排布着DDGI Probe的网格(Gird)。在DDGIVolume内的着色点会被DDGI计算出来的间接光照亮。


DDGIVolume内的物体被间接光照亮,DDGIVolume外的物体未被间接光照亮
一般情况下我们另每个Volume中的probe数目为8x8x8,并在场景中应用多个Volume以覆盖整个场景,DDGI算法会对这些Volume中计算出来的间接光照进行插值然后应用到我们最终的渲染结果。
2. DDGI数据结构
DDGI Probe
probe中存储的是球面信息,需要将球面映射到二维平面再存储到纹理贴图中。DDGI采用了一个叫做八面体映射的方法,将球面映射到八面体再映射到正方形来存储。相比于传统立方体贴图,八面体映射的效率高,分布更均匀,且误差更低。该算法用语言描述比较复杂,直接看图会清晰很多:
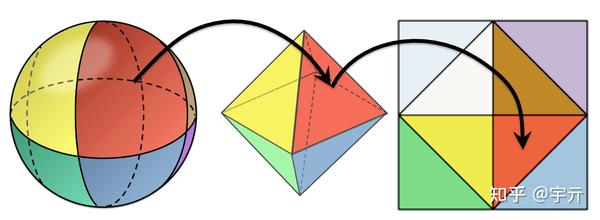
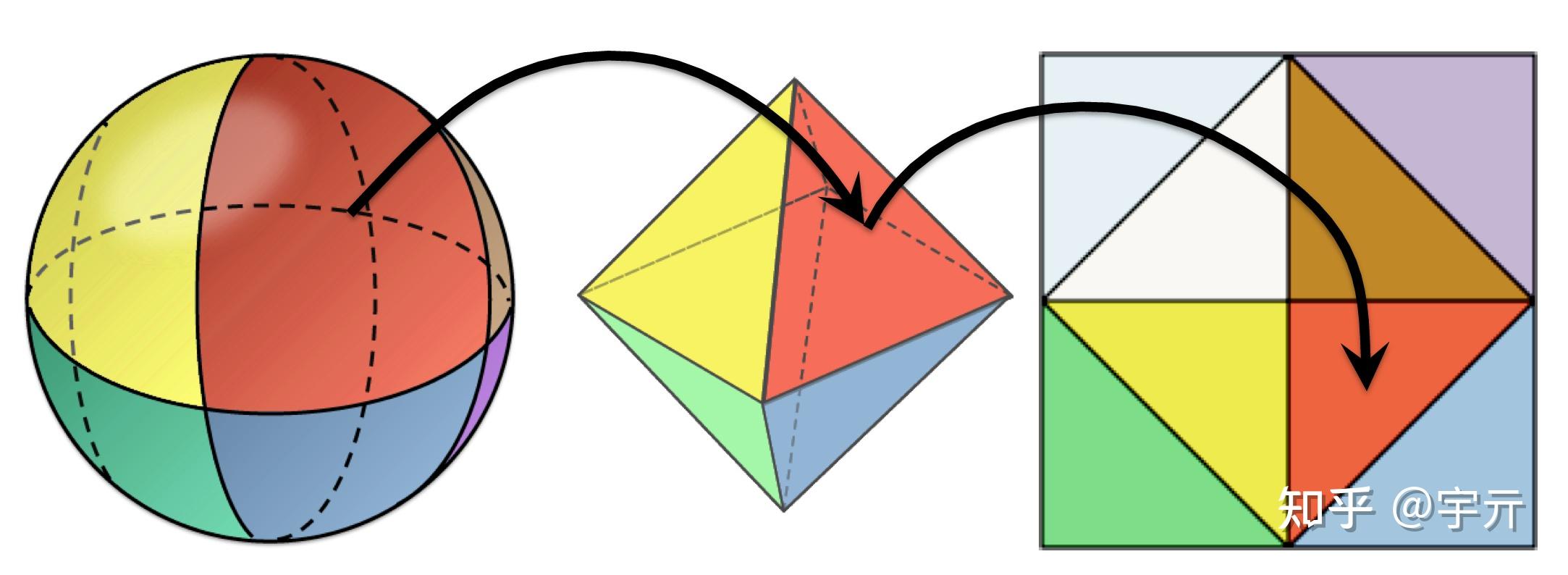
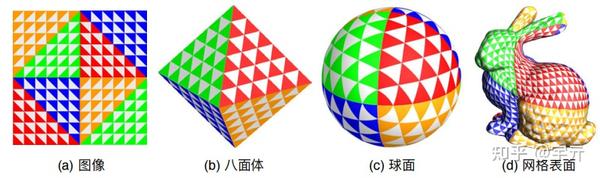
DDGI算法将球面数据通过八面体映射编码为二维的纹理,其中irradiance被编码为6x6的三维向量纹理,r(w)和r^2(w)被一起编码进14x14的二维向量纹理(x分量存储 r(w) ,y分量存储 r^2(w) )。
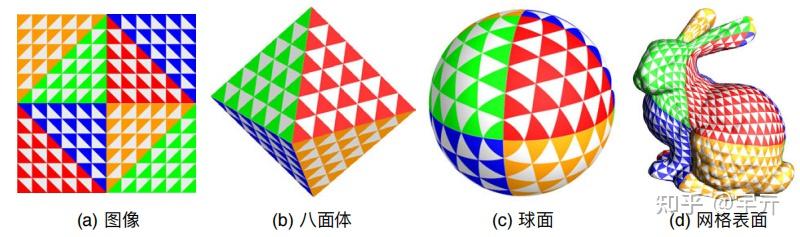
另外,由于采样probe使用的是双线性插值,为了保证边界的双线性插值正确,我们需要在上述纹理存储的基础上扩展一层外边界,方法如下:
- 对于外边界的边,将原边界倒过来复制一遍填充到外边界
- 对于外边界的四个角,使用原边界对角的像素颜色
如图:

填充外边界后,纹理占用的空间分别为8x8(Irradiance)和16x16(Depth)
DDGI Volume
DDGI Volume是一组DDGI Probe的集合。我们将一个Volume中所有probe的纹理数据给打包成一个大的图集来进行存储。下图给出了存储DDGI Irradiance的例子:


横轴为8x8=64个probe,纵轴为8个probe,每个probe占有8x8个像素,合计纹理大小为512x64
3. DDGI使用方法
我们只需要将DDGI Volume拖到场景内,该Volume内的着色点就会自动的捕获间接光照。DDGI Volume仅仅捕获动态光源的间接光照,静态光源的GI一般则是使用光照烘焙等手段生成。
在实际应用中,我们可能会需要多个Volume协同工作,这里分两种情况讨论,一种是基于实时光追的DDGIVolume,另一种是基于预计算的静态DDGIVolume。
基于实时光线追踪的DDGI Volume
基于实时光追的Volume可以跟随摄像机的移动而移动,所以我们可以在摄像机上绑定多个大小不一的Volume进行级联,体积越小的Volume的精度越高。在渲染的时候对于近处的物体就可以采用高精度Volume进行渲染,而对于远处的物体则采用低精度的Volume进行渲染。
基于预计算的DDGI Volume
在这套解决方案中,我们会预计算场景的几何信息,并在运行阶段实时更新光照信息。由于几何信息是预计算的,所以我们不能去移动Volume的位置,所以不能将Volume绑定在摄像机上。
对于预计算方案来说,我们首先需要摆放一个大号的Volume来囊括整个场景,然后对于场景中的每一个房间都放置一个Volume。
需要注意的是,我们在Volume最外面的两层probe之间会做一个线性淡出从而避免明显的边界,在这个淡出的区域室外的低精度Volume所占有的权重会越来越大,所以我们在放置Volume的时候最好让这个线性淡出的区域刚好处于室外。
这里虽然还是需要人工的放置Volume,但是相比于传统做法的人工摆放Probe来说,工作量无疑是减小了很多的。
这里我们并不需要手动的选择采用哪个Volume进行渲染,实际上对于任何一个着色点,都会采样所有包含了这个着色点的Volume并将结果进行混合,并在混合的时候令高精度的Volume拥有更高的权重。
二、使用DDGI Volume进行渲染
现在假设我们已经计算出了一个DDGI Volume,然后要用它来渲染全局光照。如何生成DDGI Volume将放在下一个部分介绍。
对于Volume内的任意一个着色点,我们总能找到其周围的8个probe,这8个probe恰好组成了一个“笼子”将着色点包裹在内。我们采样这8个probe上的irradiance,并按一定的权重进行混合,即可得到着色点的irradiance,然后利用兰伯特漫反射模型即可算出间接光照的漫反射分量。
详细分析如下,先写出渲染方程:
L_o(w_o)=\int_{\Omega} L(w_i)\{f_{diff}(w_i,w_o)+f_{spec}(w_i,w_o)\}cos\theta dw_i
这里的 L(w_i) 指的是间接光照的radiance, f_{diff} 和 f_{spec} 分别是BRDF的漫反射分量和高光分量,我们需要计算漫反射间接光照,即将上式的漫反射部分提出来:
\begin{aligned} L_{diff}(w_o)&=f_{diff}(w_i,w_o)\int_\Omega L(w_i)cos\theta dw_i \\ &= \frac{ρ}{\pi}E(n_i) \end{aligned}
其中 n_i 是表面法线, E(n_i) 可以由周围八个probe中存储的 E(n_i) 的加权平均来近似。在计算probe权重的时候,DDGI采用了三个权重系数的乘积:三线性插值系数,方向系数,切比雪夫测试系数。简单来说,大概就是以下三种情况:
- 如果probe离着色点较远,降低probe的权重(三线性插值系数)
- 如果着色点到probe的方向与表面法线的夹角过大,降低probe的权重(方向系数)
- 如果着色点与probe之间有较大的概率存在遮挡物,降低probe的权重(切比雪夫系数)
我们将这三个系数做一个指数运算然后乘起来,即为该probe的权重,这个权重是没有归一化的,最后还要做一个归一化操作:
E(n_i)≈\frac{\sum w_{p_i}E_{p_i}(n_i)}{\sum w_{p_i}}
这里对三个系数做指数运算的目的是控制三个系数所占的比重,在NVIDIA RTXGI的实现中,直接使用了三线性插值系数和方向系数,同时使用了切比雪夫系数的三次方。
一个需要注意的点是,由于最后的归一化操作需要除以权重,所以我们在计算权重的时候应当避免权重为0,以防止可能发生的除0错误,我们需要对权重设定一个最小阈值。
由于我们引入了切比雪夫系数与方向系数,大幅度降低了那些可能存在较大误差的probe所占有的权重,有效的减少了漏光和漏阴影的发生。
接下来将详细介绍一下三个系数的计算方法。
1. 三线性插值
关于三线性插值,其实网上已经有很多资料了,这里就不再赘述,如果不会的话可以参考GAMES101的Lec9:https://www.bilibili.com/video/BV1X7411F744?p=9
这里直接贴出代码:
// distanceVolumeSpace是着色点到8个probe中起始probe的偏移,是个float3
// volume.probeGridSpacing是三个维度上probe的间距,也是个float3
float3 alpha = clamp((distanceVolumeSpace / volume.probeGridSpacing), float3(0.f, 0.f, 0.f), float3(1.f, 1.f, 1.f));
// adjacentProbeOffset是一个int3,三个维度都只能取0或1,用来指示8个probe的编号。
float3 trilinear = max(0.001f, lerp(1.f - alpha, alpha, adjacentProbeOffset));
float trilinearWeight = (trilinear.x * trilinear.y * trilinear.z);2. 方向系数
在计算表面光照时,我们经常会使用光源方向和表面法线夹角的余弦,当余弦小于0时,代表着光源在表面的背面,则不考虑该光源的贡献。但是在probe插值的时候,情况略有不同,由于我们是用probe处接收到的irradiance来近似表面的irradiance而不是将probe当光源去照亮表面,所以即使是在表面背面的probe也需要考虑,比如下图的这种情况,我们就需要考虑A,B这两个probe的贡献。
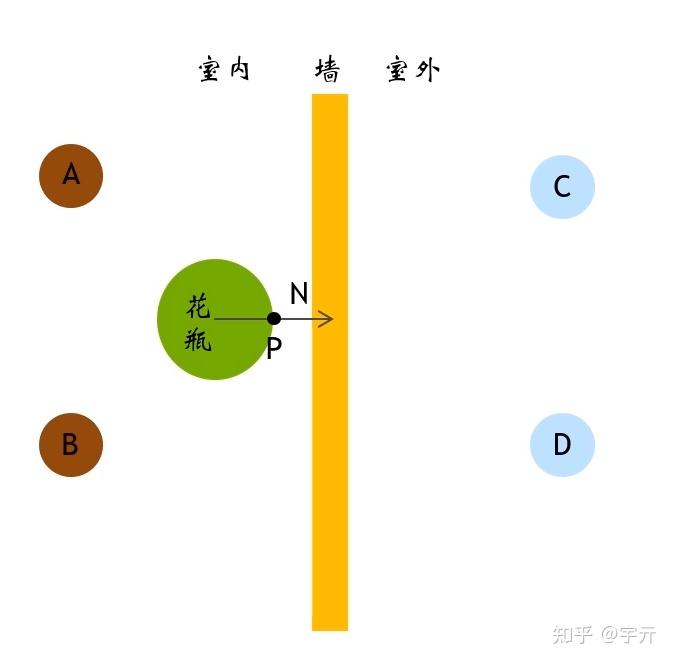

我们使用以下表达式来作为方向系数:
\{\frac{cos\theta+1}{2}\}^2+0.2
3. 切比雪夫测试
这里的做法比较类似于VSM,可以先看看GAMES202的Lec4中关于VSM的介绍:https://www.bilibili.com/video/BV1YK4y1T7yY?p=4
在概率论中有一个切比雪夫不等式:
P(r>d)\leq\frac{\sigma^2}{\sigma^2+(d-\mu)^2} \qquad (d>\mu)
其中 r 是probe往着色点方向看到的最近物体的距离, \sigma 和 \mu 分别是其标准差和期望, d 是probe到着色点的距离,则 P(r>d) 代表着probe与着色点之间没有遮挡物的概率。切比雪夫不等式给出了这个概率的一个上界,我们假设其总是能取到这个上界,那么不等于就变成了约等于,我们就可以直接用这个式子来估计着色点未被遮挡的概率。
当 d>\mu 时,使用切比雪夫估计式作为切比雪夫权重;当 d<\mu 时,则直接将切比雪夫权重置为1(认为该情况下probe与着色点之间不存在遮挡物)。
我们在probe中已经存储了加权平均的 r(w) 和 r^2(w) ,由概率论的知识可知:
\begin{aligned} \mu &= r(w)\\ \sigma^2&=r^2(w)-[r(w)]^2 \end{aligned}
最后得到的权重别忘了还要做一个三次方的指数操作。
三、生成DDGI Volume
该部分将介绍如何使用实时光追来生成与更新DDGI Volume。
回顾一下我们需要在Probe中存储的数据:
\begin{aligned} E(w)&=\int_\Omega L(w_i)cos\theta dw_i\\ r(w)&=\int_\Omega weight*d(w_i)dw_i\\ r^2(w)&=\int_\Omega weight*d^2(w_i) dw_i \end{aligned}
生成一个probe就是计算上述三个积分,而要在图形学中计算积分很自然的就会想到蒙特卡洛方法,我们可以从每个probe出发,采样若干条光线,然后将采样的结果进行蒙特卡洛积分即可获得一个probe。这一步我们可以通过RTX硬件加速的实时光线追踪完成。
但是直接使用RTX光追来计算 E(w) 还是会存在一些问题,RTX硬件加速的光追一般只会往每个方向投射一条一次弹射的path,噪声较大而且只能获得一次间接光。DDGI中使用了另一种算法,该算法结合了实时光追与延迟光照,能够获得无限次弹射的间接光,算法的大概流程如下:
- 从每个probe处发射若干条光线与场景求交,记录交点信息,不采样弹射光线。
- 将第一步记录的交点信息整合进一个类似于G-Buffer的贴图中,使用延迟渲染计算直接光照;使用上一帧的DDGI Volume来计算交点的间接光照。这里计算出来的就是光线的Radiance
- 利用2中的结果更新DDGI Probe(使用蒙特卡洛积分)
该算法与传统的路径追踪一样,都是采样若干个 L(w_i) 然后使用蒙特卡洛积分来混合,不同的是,路径追踪在计算 L(w_i) 时递归的使用蒙特卡洛积分,而该算法在计算 L(w_i) 时则是使用延迟光照计算直接光,使用上一帧的DDGI Volume计算漫反射间接光。
1. 发射光线
我们从每个probe出发,均匀向球面上发射光线(原论文中采用了一个叫”斐波那契螺旋“的采样算法)。并记录每个交点的世界空间位置,表面法线,漫反射率(Albedo)。并将结果存入分别存入三张纹理,纹理的横坐标为每个probe采样的光线数,纵坐标为Volume中的probe数。如下图所示,横轴为每个probe采样144根光线,纵轴为一共8x8x8=512个probe,每个纹素存储了交点的albedo,黑色部分是光线与场景未相交。(下图是一个albedo贴图的例子)

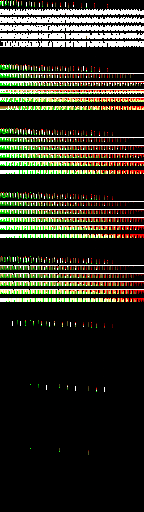
2. 计算Radiance
我们有三张纹理,分别是Position,Normal,Albedo,我们可以将这三张纹理看作一个G-Buffer,并送入延迟渲染管线进行一次延迟光照,并使用目前还未更新的DDGI Volume来计算间接光照,将结果加起来存进一个radiance贴图中。(下图是一个radiance贴图的例子)
3. ProbeBlend
这一步中,将使用radiance贴图来更新probe中的irradiance,使用Position贴图来更新probe中的depth。由于需要用radiance和position中的多个纹素混合成probe中的一个纹素,所以这一步叫做ProbeBlend。
使用Radiance贴图更新Irradiance:
E(w)=\frac{\sum L_icos\theta_i}{\sum cos\theta_i}
从Position贴图中获取光线交点的世界空间坐标位置,并计算其与probe的距离,然后使用这个距离来更新depth:
\begin{aligned} r(w)&=\frac{\sum d_icos^s\theta_i}{\sum cos^s\theta_i}\\ r^2(w)&=\frac{\sum d_i^2cos^s\theta_i}{\sum cos^s\theta_i} \end{aligned}
\theta 是纹素方向和采样点方向的夹角。 s 是一个经验性的sharpness系数, s 越大则偏离纹素方向的采样点占的比重就越小,一般取50。
执行完ProbeBlend后,别忘了填充边界以保证双线性插值的正确。
4. 时间超采样
我们可以降低每帧的光线采样率,并复用历史帧的采样结果,从而获取更优的性能。在该情况下,每个probe只需要采样64根光线就可以拥有不错的结果。
时间超采样的方式很简单,我们在计算出当前帧的ProbeBlend的结果后,将其与上一帧的结果按某一比例进行插值即可,尽管我们这里仅仅是简单的将当前帧与上一帧进行混合,但上一帧的结果本身也包括了更早的数据。
newValue = (1-\alpha)*curValue +\alpha*oldValue
\alpha 是一个可调的滞后参数,该参数取值越大则结果越依赖于历史样本,NVIDIA的实现中的默认值为0.97。
在启用了时间超采样以后,我们的间接光照对光线和场景几何的变化的响应可能会变得迟钝,导致光线的“拖尾”。为了解决这个问题,我们需要历史帧对结果的贡献更快的衰减,但我们又不能取直接大幅度降低 \alpha ,因为这样会降低时间超采样的效果。实际上,我们希望最终的结果能更多的依赖于当前帧和先前几帧的采样结果,但是更早的历史帧需要快速的衰减。基于此,我们可以对混合算法进行修正:
newValue = [(1-\alpha)*curValue^\frac{1}{gamma} +\alpha*oldValue^\frac{1}{gamma} ]^{gamma}
一般gamma取5.0f 。
四、DDGI的各种细节以及优化
1. Surface Bias
我们在使用阴影贴图计算阴影时,常常会出现自遮挡的问题,解决这个问题的方法是加一个bias。其原理在于,自遮挡来源于在可见性的边界使用了一个精度有限的ShadowMap进行可见性测试,加上bias即可使测试点离开可见性的边界。
同样,在DDGI的切比雪夫测试阶段,也需要对着色点的位置加一个bias:
V_{bias}=n*0.2+w_o*0.8
上式子是NVIDIA的实现,论文里面在上式的基础上额外乘了两个可调的参数。
2. Probe Relocation
尽管我们有切比雪夫测试来剔除可能会导致漏光漏阴影的probe,但是当一个probe离墙靠的非常近时,切比雪夫测试就不那么好用了。所以我们需要尽量避免一个probe离墙面非常近,办法就是对probe的位置进行偏移,从而让其原理表面。
对于物体表面内部的Probe,我们要尽可能让它移动到表面外;对于物体表面外部靠近物体的probe,我们要尽可能的让它远离表面。同时需要注意,为了保持8个probe的相对位置,我们需要对probe的偏移做一个限制。该限制不能超过probe间距的一半。
我们在执行光线追踪的同时计算probe的偏移,计算偏移的方法有很多,论文中也只是随便给了一个(而且还不是最优),基本思路就是按照上述讨论的来分类讨论就行。
将计算得到的probe偏移量存进一个offset纹理,然后在采样DDGIVolume计算间接光照的时候同时采样offset纹理即可。
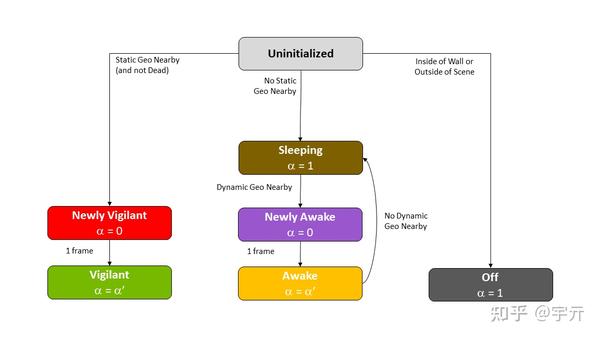
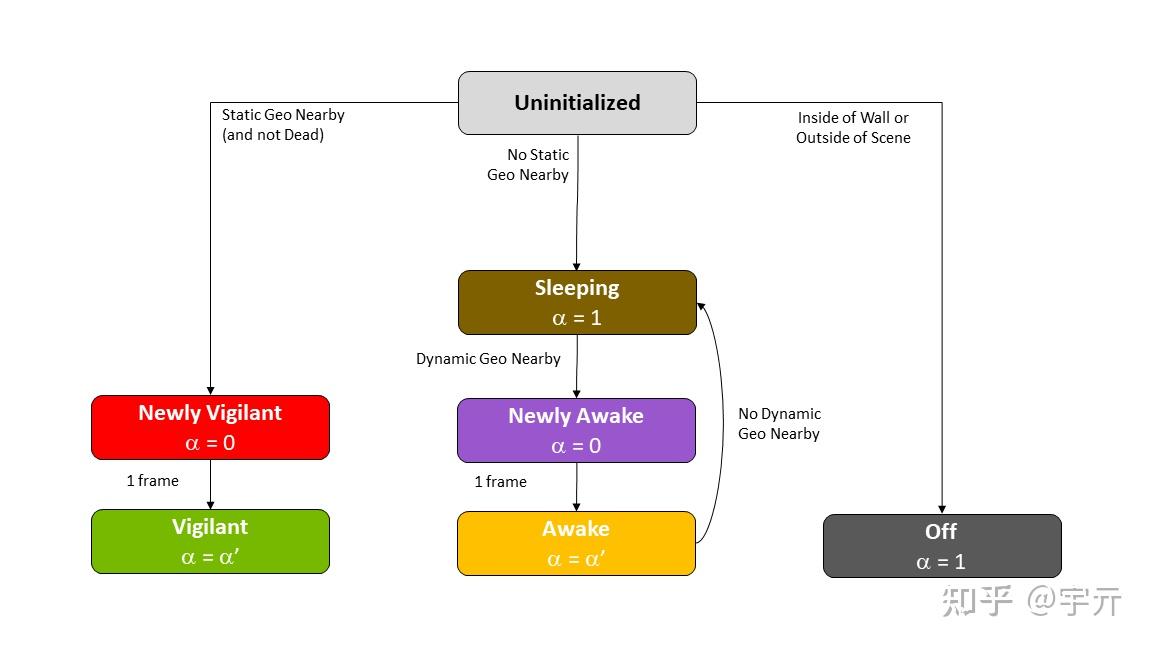
3. Probe状态机
并不是所有的probe都需要每帧更新,一些在物体内部的probe怎么更新都是黑的,一些在处在空旷区域的probe不会被采样,所以我们可以维护一个probe状态机,只更新那些需要被更新的probe从而优化性能。
Probe的状态由Probe和场景几何的相对位置决定,共7个状态:
Uninitialized:新Probe,会在初始化阶段被初始化为Off,Sleep,New Vigilant中的一种。Off:在物体内部的Probe,永远关闭Sleep:处在空旷地区的ProbeAwake:附近由动态几何的Probe,每帧发射光线Vigilant:附近有静态几何的Probe,每帧发射光线New Awake/Vigilant:状态变成Awake/Vigilant的第一帧会带NEW,设置这两个状态的目的主要是带New的Probe没有历史信息,不能做时间上的滤波。这两个状态仅仅是一个过渡状态,后面就不显示指出了。
其中,附近有静态几何体的Probe会在初始化阶段被初始化为Off或Vigilant,然后状态就不会变了。
每帧更新状态只是根据Probe旁边是否有动态几何体来在Sleep和Awake之间更新。在场景初始化的时候为所有的动态几何体计算一个轴对齐包围盒,并存入显存的数组中,然后每一帧令Probe与所有的动态几何体包围盒求交,若有相交就设置为Awake,若无则设置为Sleep。
Probe的状态可以和偏移量打包在一起然后存储到一张贴图中,xyz存储偏移量,w存储状态。
4. Volume的移动
在移动DDGI Volume的时候,我们不需要去移动所有的DDGI Probe,那样会破坏历史帧信息。我们使用了一种“滚动”的方案来移动Volume:移动Volume中心时,我们保持大部分probe不动,将后方(相对于移动方向)最后一层的probe删除,并用这些显存存储前方新出现的一层probe。
要做到这一点,我们只需要将Volume中每个probe的逻辑索引与其物理索引分离:
- 逻辑索引:与probe所在的三维空间位置相对应,空间坐标(x,y,z)均最小的那个probe逻辑索引为(0,0,0),空间坐标(x,y,z)均最大的那个probe逻辑索引为(8,8,8)(假设一共有8x8x8个probe)。
- 物理索引:通过逻辑索引计算而来,用来查找该probe存储在纹理的实际位置。
利用逻辑索引和Volume在三个方向上“向前滚动”的次数,可以计算出物理索引:
1/**
* logicalIndex 逻辑索引
* probeScroolOffset Volume在XYZ三个方向上的滚动次数,该值在CPU代码中计算
* probeGridCounts XYZ方向三各有多少个probe
*/
int3 GetPhysicalIndex(int3 logicalIndex, int3 probeScroolOffset, int3 probeGridCounts){
return (logicalGridCoord + probeScrollOffsets) % probeGridCounts;
}5. 多个DDGI Volume
在实际应用中,为了适应大场景,我们需要多个分辨率不同的DDGI Volume,当一个着色点被多个不同的Volume覆盖时,需要考虑如何混合这多个Volume的计算结果。混合的方法有很多,需要满足以下几点需求:
- 高精度的Volume的计算结果应该具有更大的权重
- Volume的边界不应该看到光照的突变
这里给出其中一种实现:
- 在CPU端按probe密度(用来指示精度)对Volume进行排序
- 在采样DDGIVolume间接光的时候,结果的rgb通道写入颜色,a通道写入边界线性淡出权重。
- 按以下逻辑混合各个Volume的结果:
float4 lightSum = float4(0, 0, 0, 1);
for(int i = 0; i < NumVolumes; ++i)
{
float4 lightWeight = GetDDGIIrradiance(volume[i], shadingPoint);
float a = saturate(1.0f - lightSum.a);
lightWeight.a = (a < 0.1f) ? a : a * lightWeight.a;
lightWeight.rgb *= lightWeight.a;
lightSum += lightWeight;
}
if(lightSum.a > 0.001f){
lightSum.rgb /= lightSum.a;
}
OutColor = float4(lightSum.rgb, 1.0f);五、基于预计算的DDGI
我们将实时光追DDGI的发射光线这个操作提前到预计算阶段,用离线射线检测来将场景的几何与材质信息写进probe中,然后每一帧利用这些信息以及当前场景的光源状态去更新probe中的Irradiance。该做法可以支持静态场景几何和动态光源,同时也可以允许场景中存在少量动态物体,这些动态物体可以被间接光照亮但不参与间接光的生成,由于DDGI生成的本身也就是漫反射的GI,少量动态物体不参与间接光计算所带来的artifact其实是不怎么明显的。
预计算阶段,我们从每个probe出发,球面均匀采样多条光线,并将交点处的Position,Normal,Albedo存储到纹理中。同时我们也需要在预计算阶段计算probe offset,同样也将结果存入到offset纹理中。运行阶段就和前面一样了:将预计算得到的数据包装成G-Buffer送入延迟光线跑一遍,用拿到的结果去更新Probe,然后采样Probe得到间接光照。
一般来说,凡是与光照无关只和几何有关的数据都可以移入预计算阶段,但出于减少存储空间的考虑,我们会将r(w)和r^2(w)的计算放在运行初始化阶段,这样我们就不需要额外存储一张”深度纹理“,可以节省不少磁盘空间。
另外,预计算DDGI也有一些需要额外注意的地方:
- 第四部分中提到的Probe状态机和Volume移动算法不再需要,前者是用来减少光追的,后者是因为预计算的DDGI Volume本身就不允许移动。
- 由于时间超采样不再被支持,每个probe可能需要更高的光线采样率,对于一般的游戏场景来说可能需要144~288的采样率,对于CornellBox来说可能需要500以上的采样率。(这里的采样率指的是每个probe采样的光线数)
- 我们需要在场景中放置大量的Volume,但每帧渲染的时候只能加载一小部分Volume,所以需要一套Volume剔除方案。另外,大量的Volume也意味着更高的存储开销。
- 由于Probe图集的存储结构是三维压到二维,渲染同一个着色点的时候采样的8个probe在纹理中的位置其实是不连续的。在移动设备上采样Volume可能会带来较大开销。
1. Volume剔除方案
渲染时允许传输的GPU的Volume数目是有限的,所以我们将一些不太重要的Volume给剔除,目前我所采用的剔除是主要是按照Volume在屏幕上所占的面积来看的,如果一个Volume在屏幕上所占的面积很小,那它生成的GI也看起来不明显,就可以被剔除。
步骤如下:
- 将那些与视锥体不相交的Volume预剔除,同时计算Volume投影到屏幕的面积。
- 综合考虑投影面积,Volume的精度,以及用户自定义的优先级来对Volume进行一次排序。
- 截取Volume数组的前几个元素。
- 仅考虑Volume精度和优先级对Volume重新排序。(这是为了让高精度Volume在多Volume混合中占更大权重)
其中第1步计算Volume在屏幕上的投影面积如下:
- 将Volume的所有顶点进行一次MVP变换,得到裁剪空间下的个点集。
- 对超出屏幕空间外的顶点进行裁剪
- 对以上点集求一个凸包
- S=\sum\limits_{i=3}^n(P_{i-1}-P_0)\times (P_i-P_0)
第2步中的排序方法具体如下:
Algo::Sort(volumes, [](const FProxyEntry& A, const FProxyEntry& B)
{
const static float areaCloseThreshold = GetDefault<URTXGIPluginSettings>()->AreaCloseThreshold;
// A充斥了整个屏幕
if(A.IsContainedCamera == true && B.IsContainedCamera == false) return true;
// A与B都只占了屏幕一部分
if(A.IsContainedCamera == false && B.IsContainedCamera == false)
{
//A的投影面积远大于B,A比B更优先
if(A.ProjectArea > B.ProjectArea * areaCloseThreshold) return true;
//AB的投影面积相近,综合考虑面积优先级精度来进行排序
if((A.ProjectArea < B.ProjectArea * areaCloseThreshold) && (B.ProjectArea < A.ProjectArea * areaCloseThreshold))
{
if (A.proxy->ComponentData.LightingPriority < B.proxy->ComponentData.LightingPriority) return true;
if ((A.proxy->ComponentData.LightingPriority == B.proxy->ComponentData.LightingPriority)
&& (A.Density * A.ProjectArea > B.Density * B.ProjectArea)) return true;
}
}
//AB都充斥了整个屏幕,仅依据投影面积和进度进行排序
if(A.IsContainedCamera == true && B.IsContainedCamera == true)
{
if (A.proxy->ComponentData.LightingPriority < B.proxy->ComponentData.LightingPriority) return true;
if ((A.proxy->ComponentData.LightingPriority == B.proxy->ComponentData.LightingPriority) && (A.Density > B.Density)) return true;
}
return false;
});
此外,还可以考虑对Volume加上遮挡剔除和距离剔除,不过这个我就没有实现了。
2. 移动端优化思路
预计算DDGI移植到移动端后的主要性能瓶颈在于采样,所以主要的优化思路就主要集中在如何降低采样上。
漫反射GI本身就是低频数据,对于低频数据来说较低的采样率也能复原出还不错的结果,再加上我们很少会单独看GI,都是和其它光照效果一起看。所以我们可以先将DDGI渲染到一张低分辨率的ColorBuffer,然后再贴到屏幕上。但是虽然间接光是低频的,但是法线可能是高频,用这个方案的话高频法线信息可能会丢失。
另外,也可以考虑分帧更新DDGIVolume,比如可以每一帧只更新一个8x8个probe,分8帧更新完一个probe,不过我这样试了一下后发现Volume对光照变化的响应迟钝,看起来会非常奇怪,只能在光照变化非常慢的场景中使用(比如天光半个小时走一个昼夜),这个问题暂时没有找到什么很好的解决方案。
在综合应用了以上两个优化方案后,最终测试结果如下:
测试环境:
荣耀50(晓龙780G)
70%的分辨率缩放
低精度大Volume采样率144,高精度小Volume采样率288
渲染线程总开销:
不开DDGI:17ms
不开优化的DDGI:42ms
50%离屏GI:36ms
分帧: 25ms
50%分辨率+分帧:20ms实机运行时,不同的视角下由于DDGIVolume投影到屏幕上所占面积的不同,实际耗时会有出入,而且实际上的耗时也跟场景中volume的数量有关,但保守估计10ms以内是能做到的。
移动端采样开销还是挺大的,一开始直接按屏幕分辨率渲染,DDGI用了1008的采样率 ,开销直接飙到了230ms!!!
3. 未来展望
针对预计算DDGI,以下想到了一些可能可以优化的点,不一定有用,也可能是负优化:
- Probe状态机可以试着加回来试试效果
- 可以尝试自适应的Volume放置方案
- 改进Volume剔除算法,目前的版本没有考虑遮挡剔除。另外也可以结合自适应放置Volume的算法来进行剔除(比如自适应放置Volume的时候使用了空间树形结构,那剔除的时候可能可以参考这个树形结构)
- 可以尝试用球谐函数编码光照
- 用SDF Ray March代替预计算光追(浙大做过一版,发在了TGDC2020)
参考资料
- Majercik2019Irradiance DDGI原始论文
- Majercik2021ScalingGI 该文章里面讲了DDGI的各种优化
- McGuire2017LightField DDGI的前身,里面提出了DDGIProbe所使用的数据结构
- 《基于预计算的光照技术》秦春林的线下巡讲PPT,主要参考了其中的八面体映射
- RTXGI NVIDIA的DDGI实现
- 《RGXGI在剑网三家园系统中的应用(GTC2020)》
- TGDC2020上浙大做的SDFDDGI