
算法工程师常用python脚本,这原理你真的理解透了吗?

(0)系列小作文之企业级机器学习pipline总结 https://mp.weixin.qq.com/s/T2LQky6CG5hSR6dasTpicA
(1)企业级机器学习 Pipline - log 数据处理 https://mp.weixin.qq.com/s/5W3L40D0ncU0Iup47sqb1Q
(2)[企业级机器学习 Pipline - 样本sample处理] https://mp.weixin.qq.com/s/OxlLN9_6QFSeE9VbpDTAtA
(3)企业级机器学习 Pipline - 特征feature处理 - part 1 https://mp.weixin.qq.com/s/qhHhYdJw5GCwD8vOzjWkeA
(5)企业级机器学习 Pipline - 召回模型 https://mp.weixin.qq.com/s/13q2gombb48zEGfkwcikPw
(5)企业级机器学习 Pipline - 排序模型 https://mp.weixin.qq.com/s/GWwS1LdRLQqIHM5wuS0egA
(6)算法工程师常用python脚本,这原理你真的理解透了吗? https://mp.weixin.qq.com/s/0yhg71Uyhi1PiFiHKvVLTw
(7)算法工程师打死都要记住的20条常用shell命令 https://mp.weixin.qq.com/s/0yhg71Uyhi1PiFiHKvVLTw
算法工程师常用的python脚本 之 Auc计算 以及 与之对应的 Roc 曲线绘制方法 、GAuc 计算 以及 Sample 随机 负采样
作为一枚算法民工,随便用 python语言 写个脚本处理日常数据应该是属于常识性的能力。而对于一门语言,最好的感觉就是: 知道做一件事情用什么方法,虽然不一定记得语言实现细节,但其中的关键点都是了然于胸的,用百度搜搜语法就能完成一个独立的功能 。
在机器学习算法中,很多情况我们都是把 Auc 当成最常用的一个评价指标,而 Auc 反映整体样本间的排序能力 ,是一个 全局性 的指标。
但是我们经常会遇到 Auc 这个指标失真的情况。因为用户广告之间的排序是个性化的,而 不同用户的排序结果不太好比较,导致了 全局性的指标Auc 在某些个性化比较强的场景下失真。
而在计算广告领域,我们实际要衡量的是 不同用户对不同广告 之间的排序能力, 实际更关注的是 同一个用户对不同广告 间 的排序能力。所以又引申出了 GAuc 的概念,即 group Auc ,即对多个用户所关注到的 多个广告 根据 用户 进行分组 得到 该用户 关注的个性化广告 来计算得出的 Auc。
这里推荐几个使用 Python实现 的小脚本,加上详细的注释,应该粘贴就可以使用的,包括:
(1) Auc计算 以及 与之对应的 Roc 曲线绘制方法
(2) GAuc 计算方法
(3) Sample 随机 负采样
1, Auc计算 以及 与之对应的 Roc 曲线绘制方法
大家都知道,AUC(Area Under Curve)被定义为 ROC曲线 下与坐标轴 围成的面积。而 ROC 曲线的横轴是 FPRate,纵轴是 TPRate 。真阳性 和 假阳性 的概念 在这里就 不再赘述 了。
一般的, Roc曲线图 如下所示:
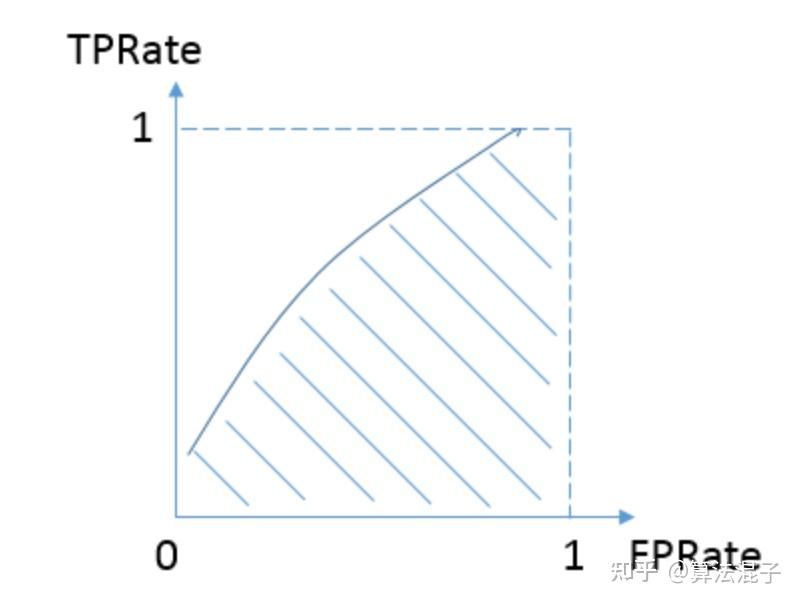

显然这个面积的数值 不会大于1 。
一种可行的 计算Auc 的方法是利用 微积分 的思想,将 Roc 曲线和 坐标轴 围成的 图像切割成一个个小的 直角梯形 。
每一个小的 直角梯形 以 X轴 上每个长度为 高 ( 左右坐标分别为 :FP_pre 和 FP ),则高取值为:(FP - FP_pre ),以 Y轴 上的取值分别为上底和下底(上下分别为 TP_pre 和 TP ),则上下底分别取值为:TP_pre,TP 。
我们在小学的时候已经知道,梯形的面积计算公式是:Area =(上底 + 下底)* 高 / 2 。即: Auc = Sum{ (TP_pre + TP)* (FP - FP_pre / 2 }我们只要将所有的小梯形面积加起来求和就是整个图像的面积了,也就是我们要求的 Auc值 。

注意:因为在计算 Auc 的过程中用到 tpr 和 fpr ,我们需要知道样本是pos 还是 neg, 所以在传入的过程中我们需要传入 样本label 以及 预估的score 。
talk is cheap, show the code !!!
@ 欢迎关注作者公众号 算法全栈之路
@ filename calAuc.py
#!/usr/bin/python
import sys
import math
def calAUC(labels,probs):
# 保证后面每个prob只计算一次面积一次
i_sorted = sorted(xrange(len(probs)),key=lambda i: probs[i],reverse=True)
auc_sum = 0.0 # 小梯形之和
TP = 0.0 # 画auc图的时候 当前点的 tpr 取值
TP_pre = 0.0 # 画auc图的时候 前一个点的 tpr 取值
FP = 0.0 # 画auc图的时候 当前点的 fpr 取值
FP_pre = 0.0 # 画auc图的时候 前一个点的 fpr 取值
P = 0; # 正样本数目,纵轴的取值个数
N = 0; # 负样本数目,横轴的取值个数
# 赋初值,给与一个大于1.0, 不可能取到的值
last_prob = probs[i_sorted[0]] + 1.0
for i in xrange(len(probs)):
# 循环各个小梯形,从原点往右往上
# 小梯形呈现阶梯型,右边上变取值只比左边大一个单元长度
if last_prob != probs[i_sorted[i]]:
#(上底 + 下底)* 高 / 2
auc_temp += (TP+TP_pre) * (FP-FP_pre) / 2.0
TP_pre = TP # 向上
FP_pre = FP # 向右
last_prob = probs[i_sorted[i]] # 保证该prob只计算一次
# 如果是正样本,向上走一步
if labels[i_sorted[i]] == 1:
TP = TP + 1
else:
# 负样本,向右走一步
FP = FP + 1
# 循环结束,计算最后一个小梯形
auc_temp += (TP+TP_pre) * (FP-FP_pre) / 2.0
# 注意,因为上面前进的都是单元长度,最终要除以多少个纵向长度,再除以多少个横向长度个数。把横轴和纵轴1的长度分别等分呢称多少份。纵轴为 1/TP,横轴为 1/FP.
# 因为TP 和FP不相等,所以横轴和纵轴的单元长度不一样,决定着Auc图像的各不相同。
auc = auc_temp / (TP * FP)
return auc
def read_Auc_file():
labels = []
probs = []
for line in sys.stdin:
sp_line = line.split("\t")
labels.append(int(sp_line[0]))
if float(sp_line[1]) < 1e-8:
probs.append(1e-8)
else:
probs.append(float(sp_line[1]))
return labels,probs
if __name__ == "__main__":
labels,probs = read_Auc_file()
auc = calAUC(labels,probs)
print "AUC:",auc
注意: 从大到小排序,和绘制Auc曲线时进行的prob 排序一致。
书接上文,和上面 计算Auc 的方法同源,我们这里在介绍一种与 之 相对应的 绘制Roc曲线 的 方法。
绘制Roc曲线方法 如下:
(1) 根据样本标签统计出正负样本的数量,假设 正样本数量 为 P, 负样本数量 为 N
(2) 把横轴的刻度间隔设置为 1/N,纵轴的刻度设置为 1/P
(3) 根据模型输出的预测概率对样本进行排序(从高到底)
(4) 依次遍历样本,同时从零点开始绘制 Roc 曲线。每遇到一个正样本,就沿着纵轴方向绘制一个刻度的曲线,每遇到一个负样本,就沿着横轴方向绘制一个刻度的曲线。
(5)遍历完所有样本,曲线最终停止在(1,1)这个位置,整个 Roc 曲线绘制完成。

上文中 Auc计算 以及 与之对应的 Roc 曲线绘制方法中,我们均需要输入样本 labal 和 模型预估的分数probs,源数据文件以 "\t" 分隔 。
2, GAuc 计算
上文 开篇 介绍了 Auc 和 GAuc所适用的场景,在很多场景下,GAuc都是一个非常有效的机器学习模型 离线评测 指标。
下面给出 GAuc 的计算脚本。
@ 欢迎关注作者公众号 算法全栈之路
@ filename calGAuc.py
#!/usr/bin/python
import sys
import math
def calGauc(group_list,score_list,label_list):
# 保存全部数据的 dict
all_data = {}
all_auc = 0.0
# 根据group分组属性,这里是imei把所有样本进行分组
# 每个用户的样本作为各自的一组
for i in range(len(group_list)):
if group_list[i] in all_data:
all_data[group_list[i]][0].append(score_list[i])
all_data[group_list[i]][1].append(label_list[i])
else:
all_data[group_list[i]] = ([score_list[i]],[label_list[i]])
#总共有多少样本
all_size = 0
# 对每个用户的样本分别计算Auc的值
for imei,value in all_data.items():
score = value[0]
label = value[1]
try:
auc = calAUC(label,score)
# 对每个用户分别计算的 Auc根据用户的样本多少击行加权求和。
all_size += len(score)
all_auc += len(score) * auc
except:
pass
#因为上面有得到的是加权求和的Auc,这里要除以总数,才能得到综合性的GAuc的值。
return all_auc/all_size
def read_Gauc_file():
labels = []
probs = []
groups = []
for line in sys.stdin:
sp_line = line.split()
if(len(sp_line)!=3):
continue;
labels.append(int(sp_line[0]))
if float(sp_line[1]) < 1e-8:
probs.append(1e-8)
else:
probs.append(float(sp_line[1]))
groups.append(sp_line[2])
# 注意,这里和计算Auc不同,多了一列分组属性,这里是imei.
return labels,probs,groups
if __name__ == "__main__":
labels,probs,groups = read_Gauc_file()
gauc = calGauc(groups,probs,labels)
print "GAUC:",gauc
上述代码中,引用了第1小节里面 计算Auc 的函数。这里的输入源数据多了一列 imei 值。
从代码中可以看出,GAuc 的计算逻辑 是根据imei分组,对各个用户(imei)的 Auc 根据 各个用户 的样本条数进行 Auc加权求和 在除以总样本数得到的 平均Auc 。原理上比 Auc 更科学一些,考虑了更多用户的个性化情况。
3, 使用python脚本实现 Sample 随机 负采样
根据 企业级机器学习 Pipline - 样本sample处理 文章里介绍的使用spark 完成 样本sample的随机负采样以外,我们也可以在保证样本数据的完整性之外,另外写一个脚本来实现负采样,这里采用python 来实现该功能。
代码如下:
@ 欢迎关注作者公众号 算法全栈之路
@ filename sample.py
import sys,random
ns_sr = 1.0
if len(sys.argv) == 2:
ns_sr = float(sys.argv[1])
for line in sys.stdin:
try:
ss = line.strip().split("\t")
label = ss[0]
value = ss[1]
# 检查样本标签是否符合预期,不符合的拦截
if "0" != label and "1" != label :
continue
# 只对负样本进行一定比例的采样操作,不符合的拦截
if "1" != label and random.random() > ns_sr:
continue
# 未进行采样的样本,直接 pass
print label + "\t" + value
except Exception,e:
continue
上面的脚本可以使用下列的命令来进行使用:
hadoop fs -text /user/app/samples/20210701/* | python sample.py 0.2 > sampled_data.txt
这里设置采样率为 0.2。 进行了负采样,在线上就需要进行线上predict分数的校准,具体的校准细节请关注作者公众号 算法全栈之路 查看文章 企业级机器学习 Pipline - 样本sample处理 了解细节哦
到这里,算法工程师常用的python脚本 - Auc计算 以及 与之对应的 Roc 曲线绘制方法 、GAuc 计算以及 Sample 随机 负采样部分就已经介绍完成了,哎,比写小作文还累啊 !!!
码字不易,觉得有收获就点赞、分享、再看三连吧 ~
欢迎关注我的公众号: 算法全栈之路
- END -
