
《长生疫苗》刘强东30万评论Python浅析

【微馨提示:转发评论Scrapy源码和评论数据等在文末获取】
全文简介
对于近日让人气愤的长春疫苗事件,京东集团刘强东在微头条发表看法,一时间获取广大粉丝热评,评论人数也是呈现指数级的增长,那么大家对这件事的态度都是什么呢?我们用Python来看看大家都在说些什么。
涉及的Python爬虫知识:
- APP抓包
- Scrapy框架的使用
- 词频统计
- 词云可视化
任务分析
我们想要获得的数据是今日头条里面的微头条,搜索刘强东用户即可找到该微头条信息。然后我们采用手机抓包的方式来发现并获取数据。接下来再用Python中的爬虫框架Scrapy来抓取数据,并且将数据保存在数据库或者本地文件即可。最后是NLP(自然语言处理)的简单应用,主要包含词云的展示。
今日头条手机APP抓包
对于APP数据的抓取首先要用到APP抓包工具,这种工具有那么几个,我用的是Fiddler4来实现的抓包。需要将你的WIFI和你的网络在相同IP下。具体的配置方法,大家可以自行进行百度。我在这里提供几个参考的文章,供大家阅读。
一图胜千言,抓包结果图如下图所示:


将得到的网址url复制到浏览器(火狐浏览器)里面会变成下图这个样子:
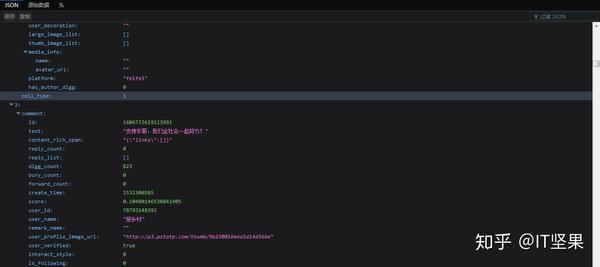

返回的是JSON文件类型的数据,很方便提取数据。另外我们精简一下网址,去掉一些无关紧要的查询字符,得到的精简网址如下:
一行太长,进行换行以后的结果:


Scrapy抓取APP数据
要想实现快速并且简单的抓取数据,爬虫框架要熟练掌握!而Scrapy框架又是一款功能强大的框架,该模块是爬虫必须掌握的模块!基本的用法大家可以参考Scrapy官网提供的教程,这个应该也是目前最好的教程了。
根据上一小节抓取到的网址结构,我们可以发现:
偏移量会随着每次的改变来翻页,所以我们只需在Scrapy里面的start_urls 这么写就好(大概就是爬取了30万条):


由于返回的是json数据,但是Scrapy本身并不天生支持json解析,所以还要导入json模块,用json模块里面的json.loads()函数将response.body 转化成json文件,这样就可以方便的用中括号来提取我们想要的数据了。


提取数据以后,我们要保存数据,保存数据的时候,我们需要编写items文件里面的内容。我就提取了两个字段,一个是用户名,一个是该用户发表的评论。至于其他字段,大家可以自行选取。


返回的数据我们用一个生成器发送给了管道文件,在管道文件里面进行处理,在管道文件里面,里面有一个process_item方法,这个方法是我们事先数据入库(或者写入本地的方法),另外对于数据写入数据库,或者是数据写入本地的文本文件还是json文件等,还建议大家写上初始化方法,或者open_spider与close_spider,后两个方法实际上是对父类的重写。分别在打开和关闭爬虫的时候调用这两个方法。
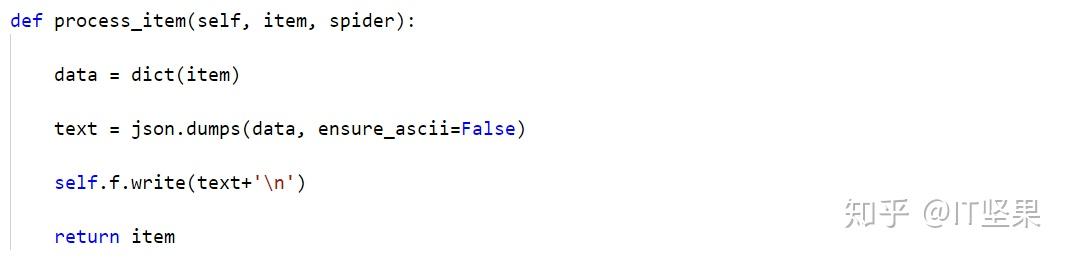

当写完管道项目以后注意,一定要打开配置文件里面的管道设置才能执行管道文件。
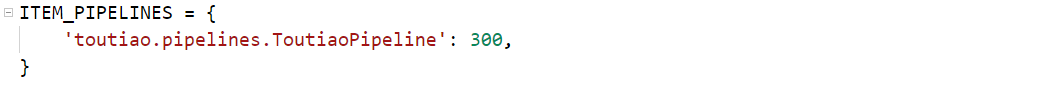

写好以后就可以运行爬虫了!!!运行程序如下:
 https://www.zhihu.com/video/1005466769275809792
https://www.zhihu.com/video/1005466769275809792数据爬完以后只能获取12万数据,到最后数据就是重复了(不再返回数据)!


词云可视化
接下来对得到的数据进行词云可视化的展示:
宝宝云图:


云图宝宝:


宝宝脚丫:


愤怒:


心图:


鸭子云图:


未来-希望:


看到这了,点个关注吧!!


源码及评论数据获取:
关注微信公众号:IT坚果

回复"今日头条源码"即可获得源码与数据资料!!


