
线性回归算法—正则化

上一篇文章总结了线性回归的一般性理论知识。
其中提到解析解往往会是非满秩的,那么就会可以解出多个\tilde{\beta}^{*},它们都能使均方误差最小化,此时选择哪一个解作为函数输出结果,将由学习算法的归纳偏好决定,常见的作法是引入正则化(regularization) 项。这一篇文章我们就来仔细认识下正则化项。
一、过拟合
如果我们有非常多的特征,我们通过学习得到的算法可以非常好得去拟合训练集(残差平方和可能几乎为0),但是这个算法可能不能很好地推广到新的样本上,不具备良好的泛化能力,这就是过拟合。
下面是一个回归问题的例子:
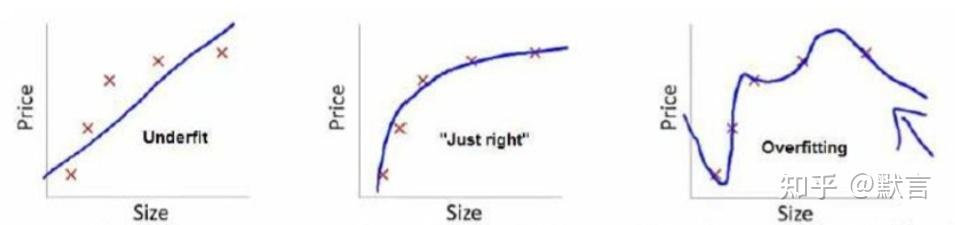

第一个模型是线性模型,欠拟合,不能很好地拟合训练集
第三个模型过于强调拟合训练集,而丢失了算法的本质:预测新数据。
分类中也存在这样的问题:
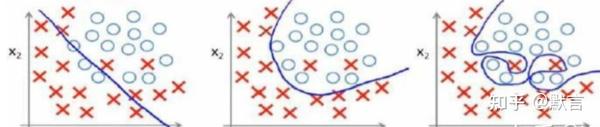

我们可以看出,若给出一个新的值使之预测,它将表现的很差,这叫作过拟合。虽然能非常好地适应我们的训练集,但是新输入变量进行预测时,效果会表现的不好。
我们可以用多项式来理解,x的次数越高,拟合的越好,但相应的预测能力就可能变差。所谓过犹不及。
二、解决过拟合的方法:
- 减少特征值的数量
- 人为的保留一些重要的特征值
- 用特征选择算法进行特征的选择(PCA、层次分析法)
2. 正则化
- 通过对目标函数添加一个参数范数惩罚,限制模型的学习能力。(保留所有的特征,但是减少参数\theta的大小)
- 最终要找到一个平衡点,使得模型能够更好地拟合训练集并且同时具有良好的泛化能力。
这里我们要学习的方法就是正则化的方法。
三、正则化中的残差平方和
假如我们有非常多的特征,我们并不知道其中哪些特征我们要惩罚,我们将对所有的特征进行惩罚,并且以残差平方和最优化这一标准来选择惩罚的程度。加入正则化项 \lambda\sum_{j=1}^{n}{\theta_{j}^{2}} (这里以L2为例,L2在下面会详细讲)后的残差平方和如下:
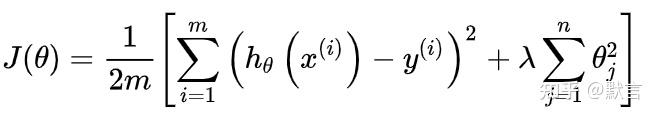

其中 \lambda 被称为正则化参数,它用来调节模型的拟合程度与模型的复杂程度,\lambda越大,对应正则化惩罚越大,模型也会越简单。经过正则化处理的模型与原模型可能的对比如下图:


可以看到加入了正则项后的拟合曲线整体会更加平缓一些。
那为什么增加了正则惩罚项后,可以减少参数的大小,以达到防止过拟合呢?我们再来看一下残差平方和:
当我们最小化 目标函数J(\theta)时,它会降低原始目标(左半部分)关于训练数据的误差并同时减小在\lambda制约下\theta的规模。当选择不同的参数范数,模型会偏好不同的解,上面公式中的为L2范数,另外常用的还有L1范数,以下将讨论各种范数惩罚项对模型的影响。
四、L1和L2正则项
当正则化项为\lambda\sum_{j=1}^{n}{\theta_{j}^{2}}时,称为L2正则化,也称为岭回归(Ridge回归)。
当正则化项为\lambda\sum_{j=1}^{n}|{\theta_{j}}|时,称为L1正则化,也称为Lasso回归。
相比L2正则化,L正则化会产生更稀疏的解,此处稀疏性指的是最优值中的一些参数为0,和L2正则化相比,L1正则化的稀疏性具有本质的不同。
由L1正则化导出的稀疏性质已被广泛地用于特征选择机制,特征选择从可用的特征子集选择出有意义的特征,化简问题。如Lasso回归中,L1惩罚使得部分参数为0,表明相应的特征可以被安全得忽略。
