
人工智能:一种现代的方法(第四版【2020年】原版) —— Chapter 1 Introduction

————2024年2月1日————
QQ群号(二群比较空):
(一群)105122906
(二群) 547655064
加群口令(【人工智能资料群】首字母小写):rgznzlq
有关AIMA这本书的具体问题,可以找国内国外一堆儿的大语言模型,比如通义千问,chatGPT之类的,ta们还是有不少了解的。如果有些概念上的疑问可以尝试问问ta们,当然还是要小心ta们还是有可能会一本正经的胡说八道。
————2023年10月6日————
两年过去了,当初写这个笔记的一大动力是当时没有中文版,因此赚个信息差流量。后来22年底中文版出来了,那么这样一般来说自己看更详细,另外本人能力有限,或许后面设计具体算法的细节难以很好的总结,因此总而言之,往后大概率可能不会更新下去了(卡在两年前的第三章),未来有缘可能会挖坟,特此声明~
——————————————
2021年9月16日
Artificial Intelligence: A modern approach (4th)是2020年最新出版的,目前没有中文译本,最近尝试着做一下学习笔记(第一次),先从第一章开始吧,基本上是对于文段的总结和概括。同时尽可能的翻译出原意(发现网易翻译的表达能力好强啊,上下文推断的很准确,对于专业领域的翻译也非常准确,词不达意的地方越来越少了)。另外,谁能想到这样一篇“学习笔记”竟然花了15个小时左右(大概有3天)。看来下一章总结得试图搞的精简一点~
Artificial Intelligence: A Modern Approach, 4th US ed. 这个是官网,里面有大量的练习题和关于相关话题的github代码
MOOC里面人工智能原理_北京大学_中国大学MOOC(慕课)虽然似乎有念PPT的问题,但是看课件和单元安排和这本书的契合度非常高,所以如果看了原书要做练习题的话也是推荐可以去做一下里面的每单元测验以巩固书中看到的知识点。
全文长达22887字左右(知乎的PC端统计,不包括括号和括号内的说明),完整阅读需要大约33分钟,如果需要的话可以收藏着慢慢看,或者想要得到极度压缩的信息的话直接看总结也可以。
另外本书需要有基本的数据结构,算法的基础,并且能够大约了解复杂度的概念。
缺漏错误之处,还望指教~
Chapter 1: Introduction
1.1 什么是AI?
什么是AI?在历来的研究中,有些研究者追求AI的fidelity of human performance(对人类表现而言的逼真度),有些则希望有一个抽象的,正式的定义——理性(rationality),简而言之,"Do the right thing(做正确的事)"。从另一个角度而言,有些人希望AI能表现出内在的智能推理能力,而有些则希望AI能有一些智能的外在表现。
这些观点在AI领域的研究中不断互相争论和互相帮助,牵涉到诸多学科领域。作者从5个方面(模仿人类行为,模仿人类思考,理性的思考,理性的行为,Beneficial machine)进行了分析。
1.1.1 Acting humanly: Turing Test Approach
图灵测试(图灵提出)指的是让机器和人同时回答问题,询问者试图去判断哪个回答来自于人,哪个回答来自于机器,如果人类无法识别两者的区别,那么图灵测试就通过了。那么目前有什么相关研究领域可以为这个问题做出较重要的贡献呢?作者引出了以下四个领域:
natural language processing to communicate successfully in a human language; knowledge representation to store what it knows or hears;
automated reasoning to answer questions and to draw new conclusions; machine learning to adapt to new circumstances and to detect and extrapolate patterns.
自然语言处理以试图和人类成功沟通;
知识表征以存储它知道或听到的东西;
自动推理以回答问题并得出新的结论;
机器学习以适应新的环境,并检测和推断模式
图灵认为物理仿真对于图灵测试没有必要,而其他学者提出的全图灵测试,则要求更多的与真实世界交互方式的实现,作者又引出了两个领域:
computer vision and speech recognition to perceive the world; robotics to manipulate objects and move about.
计算机视觉和语音识别来感知世界;
机器人技术操纵和移动物体 。
当然,目前AI的研究主流不是去如何通过图灵测试,而是去发掘智能的底层原理。作者举了一个有趣且经典的例子
The quest for “artificial flight” succeeded when engineers and inventors stopped imitating birds and started using wind tunnels and learning about aerodynamics. Aeronautical engineering texts do not define the goal of their field as making“machines that fly so exactly like pigeons that they can fool even other pigeons.”
当工程师和发明家停止模仿鸟类,开始使用风洞并学习空气动力学时,“人工飞行”的探索取得了成功。 航空工程教科书并未将其领域的目标定义为制造“飞行方式与鸽子一模一样、甚至可以骗过其他鸽子的机器”。
1.1.2 Thinking humanly: The cognitive modeling approach
要像人类一样思考,那么我们需要了解如何研究人类的思维,比如从以下三个方面:
introspection—trying to catch our own thoughts as they go by; psychological experiments—observing a person in action; brain imaging—observing the brain in action.
内省——当我们的思想经过时,试着抓住它们;
心理学实验——观察一个人的行为;
脑成像——观察大脑的活动。
一旦我们有了足够精确的描述人类思考的模型,那么我们就有可能把它变成计算机程序。其中认知科学这个交叉学科就正在把AI中的计算模型和心理学学科的实验方法结合在一起,试图去构建精确的,可测验的人类心智模型。
1.1.3 Thinking rationally: The "laws of thought" approach
从古希腊亚里士多德的三段论(syllogism)(这个论证使得给定正确的前提条件一定会得出正确的结论,比如苏格拉底是人,所有人会死,所以苏格拉底会死),到19世纪逻辑学发展了精确的符号系统来描述世界上的物体以及它们之间的关系,再到截止1965年人们可以构建程序解答所有以逻辑符号描述的可解的问题,人工智能中的逻辑主义传统希望在这些程序的基础上创建智能系统。
但是逻辑的前提是世界是确定的,而现实世界则充斥着不确定性,而概率论填补了这一空白,允许对不确定信息进行严格的推理。
但以上并不会产生智能的“行为”, 因此, 我们需要有关理性行为的理论,仅仅理性思考(Thinking rationally)本身是不够的。
1.1.4 Acting rationally: The rational agent approach
Agent就是行动的事物(agent来自拉丁语agere,意为做)。虽然所有的计算机程序都会“做”一些事,但是计算机agent应该有如下功能:自主运作,感知环境,长时间坚持,适应改变,创造和追求目标 。Rational agent(理性主体?)需要为了达到最好的outcome,或者说在不确定性环境中,为了最好的期望(大概是统计学里的平均值?),去运作。根据上一小节的“law of thought”,我们可以从那样的系统中得到正确的推理,这的确也是Rational agent的一部分——去得到最好的outcome,但是有些情况却并不包含推理,类似于面对火炉时,我们更需要缩手反射,而不是经过大量推理分析相对来说更慢的反应。我们需要学习不仅仅只是为了博学,也是因为它提高了我们做出有效行为的能力,尤其是在新环境下 。
作者认为,理性主体(Rational agent)与其他3种方式相比,更具有优势。首先,它比“law of thought”方法涵盖范围更广——正确的推理只是实现理性的几种可能机制之一。其次,它更顺应科学发展。理性的规范可以在数学上得到很好地定义,拥有一种普遍性。我们总是可以这个规范中推导agents designs,而如果目标是模仿人类的行为或思维过程,这在很大程度上是不可能的。所以人工智能的理性主体方法在该领域的历史中往往占据了上风 。简而言之,人工智能专注于研究和构建能做正确事情的agent。什么被认为是正确的事情是由我们提供给agent的目标来定义的。 这种范式是如此普遍,以至于我们可能称之为标准模型 。它不仅在人工智能中盛行,同时控制理论中,控制器使成本函数最小化; 运筹学中,采取使奖励最大化的策略;统计学中,使损失函数最小的决策规则; 经济学中,决策者最大化效用或某种社会福利的测量等等都有这种模型的影子。
但是作者提出一点,即这种总是采取理性的(某种意义上最优化的)的行动在复杂环境中是不适合的,因为它的运算量太大了,但是这种标准模型绝不失为一个好的理论分析的出发点。
1.1.5 Beneficial machines
这个标准模型虽然从最开始就是一个AI研究的有用的指引,但是长期而言它并不是一个正确的模型,原因是标准模型假设我们总是会给机器提供完全指定的目标。
像最短路径搜索和棋类AI,我们总是会提供内置的目标,这时候这个标准模型就适用了。但是在现实世界中我们无法提供一个完全指定的目标,作者举了一个自动驾驶的例子:
For example, in designing a self-driving car, one might think that the objective is to reach the destination safely. But driving along any road incurs a risk of injury due to other errant drivers, equipment failure, and so on; thus, a strict goal of safety requires staying in the garage. There is a tradeoff between making progress towards the destination and incurring a risk of injury. How should this tradeoff be made? Furthermore, to what extent can we allow the car to take actions that would annoy other drivers? How much should the car moderate its acceleration, steering, and braking to avoid shaking up the passenger? These kinds of questions are difficult to answer a priori.
例如,在设计自动驾驶汽车时,人们可能会认为目标是安全到达目的地。 但是,在任何道路上驾驶都有受伤的风险,因为其他乱开车的司机、设备故障等; 因此,严格来说,呆在车库里最安全。 在向目的地前进和承担受伤风险之间有一个权衡。 如何进行这种权衡? 此外,我们能在多大程度上允许汽车采取会惹恼其他司机的行动? 为了避免晃动乘客,汽车应该控制多少加速度、转向和刹车? 这类问题很难直接回答。
另外,作者提出了一个价值对齐问题(value alignment problem):输入机器的价值或目标必须与人的价值或目标一致。如果提供给机器对于人类而言错误的目标,那么随着该机器智能程度越来越高,造成的负面影响也会随之增加。
回到棋类游戏,作者又举了个例子——考虑如果机器有足够的智能,可以超越棋盘的限制进行推理和行动。 在这种情况下,它可能会试图催眠,敲诈对手;或贿赂观众,让他们喧嚷以扰乱对手的思维,它还可能试图自己劫持额外的计算能力。这些行为并非“愚蠢”或“疯狂”; 它们是将胜利定义为机器唯一目标的逻辑结果。 因此,总而言之单单考虑标准模型是不够的,我们需要确保AI不会造反。
| Road |
(๑•̀ㅂ•́) ✧不错不错,你看完第一小节了,想要在这个驿站休息一下吗,卖空气做的瓜子花生饮料。。。
| Road |
1.2 The Foundations of Artificial Intelligence
在这一小节中作者列举了一些对于人工智能领域有贡献的相关学科,并描述了相关的贡献。每一个领域作者会引出相关的问题
1.2.1 Philosophy
问题:形式规则可以用来得出有效的结论吗? 心灵是如何从物理大脑中产生的? 知识从何而来? 知识(knowledge)如何导致行动(action)?
1.2.1, 1.2.3, 1.2.4,1.2.5 一半1.2.7,1.2.8 基本上就是翻译原书的内容,感觉很难压缩,都挺好的,就全翻译了,光这么一小节1.2.1的翻译即使在网易翻译的辅助下照样花了一个小时~有些长句还是有点难理解~
亚里士多德,Ramon Llull为早期的推理体系(前者)和实现(后者)做了一些贡献。到1500年,列奥纳多·达·芬奇(1452-1519)设计了一台机械计算器,但没有建造; 最近的重建表明该设计具有功能性。 第一台已知的计算机是在1623年由德国科学家Wilhelm Schickard(1592-1635)建造的。 布莱斯·帕斯卡(1623-1662)在1642年建造了帕斯卡林,并写道,它“产生的效果比所有动物的行为更接近于thought”。 戈特弗里德·威廉·莱布尼茨(1646-1716)制造了一种机械装置,旨在根据概念而不是数字进行操作,但其范围相当有限。 托马斯·霍布斯(Thomas Hobbes, 1588-1679)在他1651年的著作《利维坦》(Leviathan)中提出了思考机器的概念,用他的话来说就是“人工动物”。 他还表示,推理就像数值计算:“推理…… 无非是‘估算’,像加减法一样。”
可以说,大脑至少在一定程度上是根据逻辑或数字规则运行的,并建立了模拟其中一些规则的物理系统。 另一种说法是,心灵本身就是一个物理系统。 René笛卡尔(1596-1650)第一次明确地讨论了精神和物质之间的区别。 他注意到一个纯物理的思想的概念似乎没有给自由意志留下多少空间。 如果思想被完全按照物理定律支配,它就像一块“决定”下落的石头一样,没有更多的自由意志。笛卡尔是二元论的支持者。 他认为人有一部分在自然之外,拥有不受物理法则约束的思想(或灵魂或精神)。 另一方面,动物却不具备这种双重品质; 它们可以被当作机器来对待。
二元论的另一种说法是唯物主义。唯物主义认为,大脑按照物理定律的运行构成了心灵,自由意志简而言之就是可以被感知的选择方式出现在正在选择的实体。术语物理主义和自然主义也被用来描述这种与超自然相反的观点。
既然有了操纵知识的物理思维,那么下一个问题就是建立知识的来源。从弗朗西斯·培根(Francis Bacon, 1561-1626)的书开始的经验主义运动,可以从约翰·洛克(John Locke, 1632-1704)的格言看出其特征:“没有什么东西可以在不存在于感知的情况下存在于理解中。”
大卫·休谟(David Hume, 1711-1776)的《人性论》提出了现在所知的归纳法原则:一般规则是通过揭示元素之间的反复联系而获得的。
基于路德维希·维特根斯坦(1889-1951)和伯特兰·罗素(1872-1970)的工作,著名的维也纳学派的哲学家和数学家在20世纪20年代和30年代在维也纳共同发展了逻辑实证主义学说。 该学说认为,所有知识都可以由逻辑理论表征,逻辑理论最终与感官输入相对应的观察句子(observation sentences)相联系; 因此逻辑实证主义结合了理性主义和经验主义。
鲁道夫·卡尔纳普(1891-1970)和卡尔·亨佩尔(1905-1997)的确定性理论(confirmation theory)试图通过量化逻辑句子与被证实的观察结果之间的联系来分析知识的获取或驳斥。卡尔纳普的著作《世界的逻辑结构》(The Logical Structure of The World, 1928)可能是第一个将心智理论作为计算过程的著作。
心灵的哲学图景的最后一个要素是知识和行动之间的联系。这个问题对人工智能至关重要,因为智能不仅需要推理,还需要行动。此外,只有理解行为如何被证明是正当的,我们才能理解如何构建一个行为是正当(或理性)的agent。
亚里士多德在《动物行为学》(De Motu Animalium)中指出,行为的正当性是由目标和对行为结果的认识之间的逻辑联系决定的:
但是思考是怎么发生的呢?有时伴随着行动,有时没有,有时伴随着运动,有时没有?这似乎和对不变物体进行推理和推断时发生的事情是一样的。但在那种情况下,目的是一种思辨命题……而在这里,由两个前提所产生的结论是一种行为。1,我需要遮盖物;2.斗篷是遮盖物。3,所以我需要一件斗篷。1,我需要什么,我就做什么;2.我需要一件斗篷。3.所以我要做一件斗篷。结论是,“我要做一件斗篷”,这是一个动作。
在《尼各马可伦理学》(Nicomachean Ethics)【(第三卷) 3, 1112b】中,亚里士多德进一步阐述了这个话题,提出了一个算法:
我们考虑的不是目的,而是手段。因为医生不会考虑他是否应该治愈疾病,演说家也不会考虑他是否应该使人信服……他们假定目标,并考虑如何以及用什么方法达到目标,以及这个目标是否似乎很容易达到,而且达到最好的效果;while if it is achieved by one means only they consider how it will be achieved by this and by what means this will be achieved, till they come to the first cause, … and what is last in the order of analysis seems to be first in the order of becoming(这段太难翻译了,如果有大佬能提供就太好了)。如果我们遇到了一个不可能的情况,我们就放弃寻找,例如,如果我们需要钱,但却得不到;但如果一件事看起来是可能的,我们就会去做。
2300年后,Newell和Simon在他们的通用问题解决程序(General Problem Solver)中实现了亚里士多德的算法。我们现在称之为贪心递归计划系统(greedy regression planning system)。基于逻辑规划实现明确目标的方法主导了前几十年的人工智能理论研究。
单纯从实现目标的行动来思考通常是有用的,但有时是不适用的。例如,如果有几种不同的方法来实现一个目标,就需要在其中选择一些方法。更重要的是,可能即使不可能确定地实现一个目标,我们仍必须采取一些行动。那么该如何决定呢?Antoine arnaud(1662)分析了赌博中理性决策的概念,提出了一个最大化结果的期望货币价值的定量公式。后来,丹尼尔·伯努利(Daniel Bernoulli, 1738)引入了更普遍的效用(utility)概念,以捕捉一个结果的内在、主观价值。
在道德和公共政策问题上,决策者必须考虑多个个体的利益。杰里米·边沁(1823)和约翰·斯图亚特·密尔(1863)提出了功利主义(utilitarianism)的观点:基于效用最大化的理性决策应该适用于人类活动的所有领域,包括代表许多个人做出的公共政策决策。功利主义是一种特殊的结果主义(consequentialism),它认为什么是对什么是错是由行为的预期结果决定的。
相反,伊曼努尔•康德(Immanuel Kant)提出的是一种基于规则或义务论的伦理学理论(Deontological ethics),在该理论中,“做正确的事情”不是由结果决定的,而是由普遍的社会法则决定的,这些法则支配着可允许的行为,比如“不撒谎”或“不杀人”。因此,如果预期的好大于坏,功利主义者可以撒一个善意的谎言,但康德主义者肯定不会这样做,因为撒谎本质上是错误的。约翰·斯图亚特·密尔承认规则的价值,但把它们理解为有效的决策程序,由对结果的第一性原则推理汇编而成。许多现代AI系统都采用了这种方法。
1.2.2 Mathmetics
问题:得出有效结论的形式规则是什么? 什么是可以计算的? 我们如何对不确定的信息进行推理?
在这一节中作者给出了相关领域的以下一些子领域的来由:形式逻辑,概率学,统计学,算法,哥德尔不完备定理(任何一个形式系统,只要包括了简单的初等数论描述,而且是自洽的,它必定包含某些系统内所允许的方法既不能证明真也不能证伪的命题。),可计算性(研究在不同的计算模型下哪些算法问题能够被解决),易处理性(tractability)(粗略地说,如果解决问题的实例所需的时间随着实例的大小呈指数增长,那么这个问题就称为棘手(tractable)的问题 ),NP完全问题(为分析问题的易处理性提供了基础:在任何问题类中,其中属于NP完全问题的类别可能是难处理的。 (尽管尚未证明np完全问题必然是棘手(tractable)的,但大多数理论家相信这一点。) )。
1.2.3 Economics
问题:我们应该如何根据自己的优先喜好做出决策? 当别人可能不赞同的时候,我们该怎么做决策呢? 当回报可能在遥远的未来时,我们该如何做决策呢?
经济学起源于1776年,亚当·斯密(1723-1790)发表了《国富论》。他提出经济由诸多个体的为自己利益的行为而构成。 然而,史密斯并没有把金融的贪婪性作为一种道德立场:他早期(1759年)的著作《道德情操论》(The Theory of moral Sentiments)一开始就指出,对他人福祉的关心是每个个体利益的重要组成部分。
大多数人认为经济学是关于钱的,事实上,第一个对不确定性下的决策进行数学分析的是阿诺德(1662)的最大期望值公式,它处理的的确是押注的货币价值。 但随着经济学的发展,它不再是研究货币的学科; 相反,它是对欲望和偏好的研究。
决策理论结合了概率论和效用论,为在不确定情况下做出的个人决策(经济或其他方面的)提供了一个正式和完整的框架。 这适用于“大型”经济体,在这种经济体中,每个个体无需关注其他个体的行为。 对于“小型”经济,情况更像是一场游戏博弈:一名玩家的行动可以显著影响另一名玩家的效用(不管是积极的还是消极的)。 Von Neumann和Morgenstern对博弈论的发展包含了一个令人惊讶的结果,即在某些游戏中,理性的行动者应该采用(或至少看起来是)随机的策略。 与决策理论不同,博弈论没有为选择行动提供明确的处方。
但似乎经济学家没有解决上面列出的第三个问题:当行动的回报不是立即的,而是由几个顺序采取的行动产生时,如何做出理性的决定。 这一课题在运筹学中得到研究,这一领域出现于二战期间英国优化雷达装置的努力中,后来演化出了无数民用应用。 理查德·贝尔曼(1957)的工作形式化了一类被称为马尔可夫决策过程的顺序决策问题。
经济学和运筹学研对人工智能的rational agent(理性主体)概念做出了很大贡献,但多年来,人工智能研究沿着完全不同的道路发展。 原因之一是做出理性决定的复杂性。 1978年,赫伯特·西蒙(Herbert Simon, 1916-2001)获得了诺贝尔经济学奖,因为他的早期工作表明,基于“满意决策"的模型,而不是艰难地计算一个最优决策,可以更好地描述实际的人类行为(Simon, 1947)。 自20世纪90年代以来,人们对人工智能的决策理论技术重新产生了兴趣。
1.2.4 Neuroscience
问题:大脑是如何处理信息的?
神经科学是研究神经系统,尤其是大脑的学科。目前关于大脑还有诸多未解之谜,但是也有不少成果。在18世纪以前,人们并没有意识到大脑是意识的来源,之后随着大量证据比如大脑如果某些部分损伤会导致精神表现失常,人们才逐渐意识到这一点。之后Broca对失语症患者的研究表明大脑左半球的某些区域负责言语的生成。另外,在1873年Camillo Golgi (1843–1926) 发明了高尔基染色法,因此人们对神经元的结构有了更清晰的认识。目前,我们认知功能是这些结构的电化学作用的结果,这一观点已被广泛接受。 也就是说,一组简单的细胞可以导致思想、行动和意识。 用约翰·塞尔(John Searle, 1992)的精练的话来说,大脑导致思想。
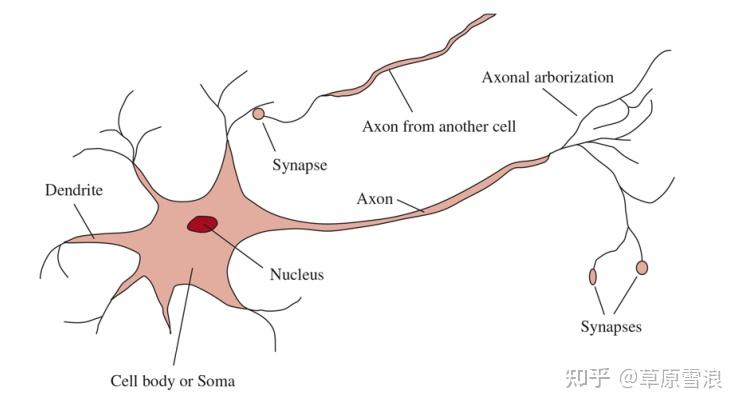

图1.1显示,每个神经元(Neuron)由一个包含细胞核(Nucleus)的细胞体(或称Soma)组成。 从细胞体中分支出来的是一些称为树突的(Dendrite)纤维和一种称为轴突(Axon)的长纤维。 轴突延伸很长一段距离,比这张图上的刻度要长得多。 典型的轴突是1厘米长(细胞体直径的100倍),但可以随着生长延伸到1米。 一个神经元在突触(Synapse)处与10到10万个其他神经元相连。 信号通过复杂的电化学反应在神经元之间传递。 这些信号在短期内控制大脑活动,也使神经元的连接发生长期变化。
这些机制被认为是大脑学习的基础。 大多数信息处理都在大脑皮层进行,也就是大脑的外层。 基本的组织单位是直径约0.5毫米的组织柱,其中包含约20,000个神经元,并延伸至皮层的全部深度(人类约4毫米)。
在目前的研究中我们有一些关于大脑区域和他们控制的身体部位之间的映射,以及他们接收感官输入的部位的数据。 这样的映射可以在几周内彻底改变,有些动物似乎有多个映射。 此外,我们还不完全了解,当一个区域受损时,其他区域如何接管功能。 几乎没有关于个人记忆是如何储存的理论,也没有关于高级认知功能是如何运作的理论。
对完整大脑活动的测量测量始于1929年,当时汉斯·伯杰发明了脑电图仪(EEG)。 功能性磁共振成像(fMRI)的发展(Ogawa et al., 1990; Cabeza和Nyberg, 2001)正在为神经科学家提供前所未有的大脑活动的详细图像,使测量能够以有趣的方式与正在进行的认知过程相对应。 如今,通过单细胞神经元的电信号活动记录和光遗传学方法(Crick,1999; 光遗传学Zemelman等人,2002; Han和Boyden, 2007),我们可以将单个神经元改为光敏并进行测量。
脑机接口(Lebedev and Nicolelis, 2006)的发展不仅有望恢复残疾人的功能,而且还揭示了神经系统的许多方面。 这项工作的一个显著发现是,大脑能够自我调整,成功地与外部设备连接,有效地将其视为另一个感觉器官或肢体。
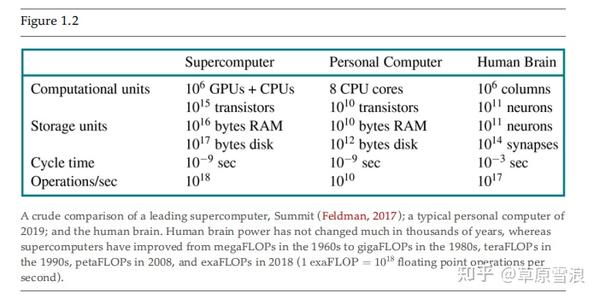
大脑和数字计算机有一些不同的特性。 图1.2显示,计算机的周期时间比人脑快一百万倍。 尽管最大的超级计算机在某些指标上与大脑不相上下,但大脑的存储空间和互联程度远远超过了高端个人电脑。 未来学家们对这些数字做了大量的研究,指出计算机达到超人类性能水平的奇点正在接近 (Vinge, 1993; Kurzweil, 2005; Doctorow and Stross, 2012),之后他们会继续迅速提升自己。 但原始数据的比较并不能提供特别有用的信息。 即使有了容量几乎无限的计算机,我们对智能的理解仍需要进一步的概念突破(见第28章)。 粗略地说,如果没有正确的理论,更快的机器只会更快地给出错误的答案。

1.2.5 Psychology
问题:人类和动物是如何思考和行动的?
科学性心理学的起源通常可以追溯到德国物理学家赫尔曼·冯·亥姆霍兹(1821-1894)和他的学生威廉·冯特(1832-1920)的工作。 亥姆霍兹将科学方法应用于人类视觉的研究,他的《生理光学手册》被描述为“关于人类视觉的物理和生理学的最重要的论文”(Nalwa, 1993,第15页)。 1879年,冯特在莱比锡大学开设了第一个实验心理学实验室。 冯特坚持进行仔细的对照实验,在实验中,他的工作人员在进行感知或联想任务的同时,反思他们的思维过程。 这种方法在使心理学成为一门科学的道路上走了很长一段路,但数据的主观性使实验人员不太可能推翻他们自己的理论 。
另一方面,研究动物行为的生物学家缺乏内省的数据,而发展了一种客观的方法论,正如H. S. Jennings(1906)在其颇具影响力的著作《低等生物行为》中所描述的那样。 约翰·沃森(John Watson, 1878-1958)领导的行为主义运动将这一观点应用于人类,拒绝任何涉及心理过程的理论,理由是内省无法提供可靠的证据。 行为主义(Behaviorism)者坚持只研究给予动物的知觉(或刺激)和由此产生的行动(或反应)的客观测量。 行为主义在老鼠和鸽子方面发现了很多,但在理解人类方面却不太成功。
认知心理学则认为大脑是一种信息处理设备,这至少可以追溯到威廉·詹姆斯(William James, 1842-1910)的著作。 亥姆霍兹还坚持认为,知觉是一种无意识的逻辑推理。 在美国,认知的观点在很大程度上被行为主义所掩盖,但在弗雷德里克·巴特利特(1886-1969)领导的剑桥应用心理学部门,认知建模得以蓬勃发展。 巴特利特的学生兼继任者肯尼斯·克雷克(1943)的《解释的本质》有力地重新确立了信念和目标等“精神”术语的合法性,认为这些就像是用压力和温度来讨论气体一样,尽管气体是由两者都没有的分子组成的。
克雷克(Craik)指出了基于知识的agent的三个关键步骤:(1)刺激必须转化为内部表征,(2)表征被认知过程操纵以获得新的内部表征,(3)这些表征反过来被重新转化为行动。 他清楚地解释了为什么这是一个很好的agent设计:
如果生物体有一个外部现实的“小规模模型”,以及它自己的大脑中可能的活动 ,那么它可以尝试多种可能,并总结其中最适合于它们的,应对未来可能出现的问题,利用过去的知识处理的现在和未来,并以更全面、更安全、更有效的方式对面临的紧急情况作出反应。 (Craik, 1943)
克雷克之后,模拟心理学现象和信息处理的建模随着计算机的发展带来了认知科学这门学科的出现。在1956年9月MIT的研讨会上,乔治·米勒(George Miller)提出了《神奇数字7》,诺姆·乔姆斯基(Noam Chomsky)提出了《语言的三种模型》,艾伦·纽威尔(Allen Newell)和赫伯特·西蒙(Herbert Simon)提出了《逻辑理论机器》。 这三篇有影响力的论文分别展示了计算机模型是如何用于研究记忆、语言和逻辑思维的心理学的。 现在,心理学家普遍(尽管远非普遍)认为“认知理论应该像计算机程序”(Anderson, 1980); 也就是说,它应该从信息处理的角度描述认知功能的运行。
另外,增强智能(Intelligent augmentation【简称IA】)也在逐渐发展,人机交互技术的先驱之一道格·恩格尔巴特(Doug Engelbart)支持智能增强的想法——IA而不是AI。 他认为计算机应该增强人类的能力,而不是让人类的工作自动化。 1968年,恩格尔巴特的“所有演示之母”首次展示了计算机鼠标、窗口系统、超文本和视频会议——所有这些都是为了展示人类知识工作者通过某种智能增强可以集体完成什么。
今天,我们更可能把IA和AI看作是一枚硬币的两面,前者强调人类的控制,后者强调机器的智能行为。 这两者都是机器对人类有用所必需的。
1.2.6 Computer engineering
问题:我们怎样才能造出一台高效的计算机呢?
现代数字计算机最早产生于二战时期的3个国家(1941年德国的Z-3;1943年英国的Heath Robinson;美国的ENIAC),之后硬件技术逐渐发展,但从2005年开始增长速度开始放缓,原因是由于技术限制生产厂商逐渐以增加CPU核数代替增加CPU的时钟频率(clock speed),在这方面未来可能更多的是以并行处理为研究方向。
目前AI技术的发展同样需要诸多算力(GPU, TPU, WSE等等),而最近逐渐迅速发展的量子计算也可能会给算力提升带来不少可能性。
1.2.7 Control theory and cybernetics
问题:工件如何在它们自己的控制下操作?
早期的自我控制机器包括拥有控制水流速度恒速的水钟(亚历山大的Ktesibios (公元前 250 年)),蒸汽发动机调速器(詹姆斯•瓦特(1736 - 1819)),恒温器(Cornelis Drebbel (1572–1633))等,詹姆斯·克拉克·麦克斯韦(那个提出麦克斯韦方程的著名的物理学家)(1868)开创了控制系统的数学理论 。
在战后控制理论的发展中,诺伯特·维纳 (1894 - 1964) 的贡献尤为突出,对于当时被视为正统的行为主义思想,他和他的同事提出了质疑,他们认为具有目的性的行为源于一种试图最小化“错误”(即当前状态和目标状态之间的差异)的调节机制。 20世纪40年代末,维纳与沃伦·麦卡洛克(Warren McCulloch)、沃尔特·皮茨(Walter Pitts)和约翰·冯·诺伊曼(John von Neumann)组织了一系列有影响力的会议,探索新的数学和计算认知模型。 维纳的《控制论》(1948)成为畅销书。
另外,英国的一些学者也提出了类似的观点,比如阿什比的《Design for a brain》(1948,1952)详细阐述了他的想法,即智能可以通过使用包含适当反馈回路的体内平衡装置来实现稳定的自适应行为。
现代控制理论,特别是被称为随机最优控制的分支,其目标是设计随着时间的推移使成本函数最大化的系统。 这大致符合AI的标准模型:设计行为最佳的系统。 那么,为什么人工智能和控制理论是两个不同的领域,尽管它们的创始人关系密切? 答案在于参与者所熟悉的数学技巧与每种世界观所包含的相应问题集之间的紧密耦合。 作为控制理论的工具,微积分和矩阵代数适用于由固定连续变量集描述的系统,而AI的建立在某种程度上是为了摆脱这些可感知的局限性。 逻辑推理和计算工具使人工智能研究人员能够考虑语言、视觉和符号规划等完全超出控制理论家职权范围的问题。
1.2.8 Linguistics
问题:语言和思想是如何联系的?
1957年,b.f.斯金纳发表了《Verbal Behavior》。 这是一篇由该领域首屈一指的专家撰写的关于语言学习行为主义方法的全面而详细的论述。 但奇怪的是,这本书的书评和书本身一样有名,几乎抹杀了人们对行为主义的兴趣。 这篇评论的作者是语言学家诺姆·乔姆斯基(Noam Chomsky),他刚刚出版了一本关于自己的理论《句法结构》(Syntactic Structures)的书。 乔姆斯基指出,行为主义理论并没有解决语言创造力的概念——它没有解释儿童如何理解和编造他们以前从未听过的句子。 乔姆斯基基于句法模型的理论可以追溯到印度语言学家帕尼尼(约公元前350年),它可以解释这一点,而且与之前的理论不同,它足够形式化,原则上可编程的。
现代语言学和人工智能几乎是在同一时间“诞生”的,并共同成长,交叉于一个被称为计算语言学或自然语言处理的混合领域。 事实证明,理解语言的问题比1957年看起来要复杂得多。 理解语言需要理解主题和上下文,而不仅仅是理解句子的结构。 这似乎是显而易见的,但直到20世纪60年代,人们才普遍认识到这一点。 知识表征(knowledeg representation)的早期工作(研究如何将知识转化为计算机可以推理的形式)大多与语言有关,并受到语言学研究的启发,而语言学研究又与数十年来对语言的哲学分析工作有关。
| Road |
o(^▽^)o你看完第二小节了,有什么收获吗?这小节挺长的,觉得累就先休息一下吧(๑•̀ㅂ•́) ✧)
| Road |
1.3 The History of Artificial Intelligence
要快速总结人工智能历史上的里程碑,可以列出图灵奖的获奖者:Marvin Minsky(1969)和John McCarthy(1971)因为定义了表示和推理领域的基础而获奖; Ed Feigenbaum和Raj Reddy(1994)因为开发将人类知识编码以解决现实世界问题的专家系统而获奖; 朱迪亚·珀尔(juddea Pearl, 2011)因为发展了处理不确定性的概率推理技术而获奖; 最后是约书亚·本乔(Yoshua Bengio)、杰弗里·欣顿(Geoffrey Hinton)和扬·勒昆(Yann LeCun)(2019),他们将“深度学习”(多层神经网络)作为现代计算的关键组成部分。 本节的其余部分将更详细地介绍AI历史的各个阶段。
1 人工智能的诞生(1943-1956):第一个被公认为人工智能的工作是由Warren McCulloch和Walter Pitts(1943年)完成的。他们提出了一个人工神经元模型。在1950年,哈佛大学的两名本科生Marvin Minsky(1927-2016)和Dean Edmonds建造了第一台神经网络计算机。它被称为SNARC,使用了3000根真空管和B-24轰炸机上多余的自动驾驶装置来模拟一个由40个神经元组成的网络。除此之外,还有一些其他可以被描述为AI的早期工作,但是最具有影响力的还是图灵的工作,早在1947年,他就在伦敦数学学会(London Mathematical Society)就这个话题发表了演讲,并在1950年的文章《计算机器与智能》(Computing Machinery and Intelligence)中阐述了一个有说服力的议程。 在其中,他介绍了图灵测试、机器学习、遗传算法和强化学习。 他处理了许多针对人工智能可能性的反对意见。 他还表示,通过开发学习算法,然后教会机器,而不是手工编写智能程序,会更容易创造出人类级别的人工智能。 在随后的讲座中,他警告说,实现这一目标可能不是对人类最好的事情。1956年夏天,约翰·麦卡锡(John McCarthy)在达特茅斯学院召集了其他一些相关领域的学者进行了为期两月的研讨会,并提出了达特茅斯宣言,其中有一段如下:
人们将尝试寻找如何让机器使用语言,形成抽象和概念,解决目前只有人类才能解决的各种问题,并改进自身。 我们认为,如果一组精心挑选的科学家花一个夏天的时间共同研究这些问题,就可以在其中一个或多个问题上取得重大进展。
然而现实是他们在那段时间并没有取得突破性进展,其中最有效的进展可能是Newell和Simon发明的一个叫做Logic Theorist (LT)的定理证明系统。
2 早期的热情,远大的期望(1952-1969): 总的来说,20世纪50年代的知识界更倾向于相信“机器永远不能做X”(参见第27章图灵收集的一长串X的列表)。 人工智能研究人员自然地做出了一个又一个X的证明。 他们特别关注被认为能显示人类智力的任务,包括游戏、谜题、数学和智商测试。 约翰·麦卡锡称这个时期为“看,妈妈,没有手!” 时代。 Newell和Simon在LT以后发展了通用问题解决器(GPS)。 与LT不同,这个程序从一开始就被设计成模仿人类解决问题的协议。 在它能处理的有限的谜题中,程序考虑子目标和可能行动的顺序与人类处理相同问题的顺序相似。这也可以算是第一次体现“thinking humanly”的方法。后续因之而规划的认知模型是著名的物理符号系统假说(1976年提出),即为了得到智能的行为(action), 物理符号是有必要且充分的。他们的意思是,任何展示智能的系统(人或机器)都必须通过操纵由符号组成的数据结构来进行操作。 但这一假设在之后的时期受到了多方面的挑战。在这一阶段,阿瑟·塞缪尔(Arthur Samuel )在他的棋类AI设计中使用了我们现在称为强化学习的方法,虽然卓有成效但受限于时代的硬件技术。1958年,约翰·麦卡锡(John McCarthy )在AI领域做出了两项重要的贡献,一个是发明了Lisp高级编程语言(这个语言在接下来30年里是AI编程的主流),另一个是撰写了一篇名为Programs with Common Sense的论文,它假设了一个叫做Advice Taker的程序,该程序体现了知识表征和推理的核心原则:对世界及其运作有一个正式的、明确的表征,并能够通过演绎过程操纵这种表征。另一边,在麻省理工学院,Marvin Minsky指导了一系列学生,让他们选择一些似乎需要智能才能解决的有限问题。 这些有限的领域被称为“microworld",比如智商测试中出现的几何类比问题(Tom Evans's ANALOGY program (1968) )等。
3 一剂现实(1966-1973):在早年间人工智能乐观主义是比较兴盛的,其中Herbert Simon在1957年说:
我的目的不是要让你们感到惊讶或者震惊,但我能总结的最简单的方法是说,现在世界上有机器会思考,会学习,会创造。 此外,它们处理这些事情的能力将迅速提高,直到——在可见的未来——它们能够处理的问题的范围将与人类思维的应用范围共同扩大。
这种乐观状况逐渐失效,主要是以下两方面:第一,许多早期的人工智能系统主要基于“知情的自省”人类如何执行一项任务,而不是仔细的分析任务,什么是一个解决方案,一个算法需要做些什么来可靠地产生这样的解决方案。失败的第二个原因是缺乏对人工智能试图解决的许多问题的复杂性的认识。早期的研究操控的物体的复杂性并不高,但之后就逐步攀升不可收拾了。
4 专家系统 (1969–1986) : (这一节翻译了一半左右文本)在人工智能研究的第一个十年中出现的问题解决方案是一种通用搜索机制,试图将基本的推理步骤串在一起,找到完整的解决方案。 这种方法被称为弱方法,因为尽管它们是通用的,但它们不能扩展到大型或困难的问题实例。 替代弱方法的方法是使用更强大的、特定于领域的知识,它允许更大的推理步骤,并且可以更容易地处理在狭窄的专业领域中通常发生的情况。
DENDRAL项目(Buchanan et al., 1969)是这种方法的早期例子。 它是在斯坦福大学开发的,Ed Feigenbaum (Herbert Simon的前学生),Bruce Buchanan(哲学家转计算机科学家)和Joshua Lederberg(诺贝尔遗传学奖得主)合作解决了从质谱仪提供的信息推断分子结构的问题。 程序的输入包括分子的基本公式(例如,C6H13NO2)和质谱,质谱给出了当分子被电子束轰击时产生的各种碎片的质量。 例如,质谱可能在m = 15处有一个峰,对应于一个甲基(CH3)片段的质量。
该程序的原始版本生成了与公式一致的所有可能的结构,然后预测每种结构会观测到什么样的质谱,并将其与实际光谱进行比较。 正如人们可能预期的那样,中等大小的分子就已经很棘手了。 DENDRAL的研究人员咨询了分析化学家,发现他们是通过寻找光谱中已知的峰型来工作的,这些峰型表明了分子中常见的亚结构。 例如,用以下规则识别酮(C=O)亚基(权重为28):
如果M是整个分子的质量并且在x1和x2处有两个峰,使(a) x1 + x2 = M + 28; (b) x1−28为一个high weak; (c) x2−28为一个high peak; (d) x1和x2中至少有一个是高的,那么就有一个酮亚群存在
认识到分子包含特定的子结构,就会极大地减少可选分子的数量。 根据其作者的说法,DENDRAL之所以强大,是因为它不是以第一性原理的形式,而是以高效的“食谱”的形式体现了质谱学的相关知识(Feigenbaum等人,1971年)。 DENDRAL的重要性在于它是第一个成功的知识密集型系统:它的专业知识来源于大量的特殊目的规则。 1971年,Feigenbaum和斯坦福大学的其他人开始了启发式编程项目(Heuristic Programming Project,HPP),以研究专家系统的新方法论在多大程度上可以应用于其他领域。
接下来的主要工作是用于诊断血液感染的MYCIN系统。 通过大约450条规则,MYCIN能够像一些专家一样表现出色,比初级医生要好得多。 它还包含了与DENDRAL的两个主要区别。 首先,与DENDRAL规则不同,不存在可以推导出MYCIN系统规则的一般理论模型。 它们必须通过对专家的大量咨询才能获得。 第二,规则必须反映与医学知识相关的不确定性。 MYCIN包含了一种称为certainty factors的不确定性微积分(见第13章),这似乎(在当时)与医生如何评估证据对诊断的影响非常吻合。
之后专家系统的发展在政府的大力支持下雨后春笋般被广泛的商业投资,人工智能产业从1980年的几百万美元发展到1988年的数十亿美元,其中包括数百家关于专家系统、视觉系统、机器人,和专门和这些有关的和软件和硬件的公司。
不久之后,出现了一个被称为“人工智能冬季”的时期,在这个时期,许多公司因为未能兑现过于夸张的承诺而半途而废。 事实证明,为复杂领域建立和维护专家系统是困难的,部分原因是系统使用的推理方法在面对不确定性时失效,部分原因是系统无法从经验中学习。
5 神经网络的回归 (1986–):在20世纪80年代中期,至少有四个不同的小组重新发明了20世纪60年代早期首次开发的反向传播学习算法。 该算法被应用到计算机科学和心理学的许多学习问题中,并在《并行分布式处理》(Rumelhart and McClelland, 1986)一书的广泛传播中引起了极大的轰动。
这些叫做的连接主义(connectionist)的模型被一些人视为Newell和Simon提出的符号主义模型和McCarthy等人提出的逻辑主义方法的直接竞争对手。连接主义模型可能以一种更流畅、更不精确的方式形成内部概念,这种方式更适合现实世界的混乱。它们也有从例子中学习的能力,可以比较它们的预测输出值和问题的真实值,并修改它们的参数,以减少差异,使他们更有可能在未来的例子中表现良好。
6 概率推理和机器学习(1987 - ):(基本都翻译了)专家系统的脆弱性导致了一种新的、更科学的方法,它结合了概率而不是布尔逻辑,结合了机器学习而不是手工编码,结合了实验结果而不是哲学主张,以现有理论为基础而不是提出全新的理论,以严格的定理或坚实的实验方法(Cohen, 1995)而不是以直觉为基础,以及展示与现实世界的应用的关联而不是玩具例子的相关性。
语音识别领域说明了这种模式。 在20世纪70年代,人们尝试了各种不同的架构和方法。 其中许多都是非常专门化和脆弱的,并且只在一些精心挑选的示例上工作。 在20世纪80年代,使用隐马尔可夫模型(HMMs)的方法开始在该领域占据主导地位。 HMM有两个方面是相关的。 首先,它们是基于严格的数学理论。 这使得语言研究人员可以在其他领域几十年的数学成果的基础上进行研究。 其次,对大量真实语音数据进行训练生成。 这确保了性能是稳健的,在严格的盲测中,HMM的分数稳步提高。 请注意,并没有科学宣称人类使用HMM识别语言; 相反,HMM提供了一个理解和解决问题的数学框架。 然而,我们将在第1.3.8节中看到,深度学习已经颠覆了这种舒适的叙述。
1988年是人工智能与统计学、运筹学、决策理论、控制理论等领域接轨的重要一年。 朱迪亚·珀尔(juddea Pearl, 1988)的《智能系统中的概率推理》(Probabilistic Reasoning in Intelligent Systems)让人们对概率和决策理论有了新的认识。 Pearl发展了贝叶斯网络(Bayesian networks),以一种严谨而有效的形式表示不确定的知识,以及用于概率推理的实用算法。
1988年的第二个主要贡献是Rich Sutton的工作,他将强化学习(Arthur Samuel在20世纪50年代的棋类程序中使用了强化学习)与运算学领域发展起来的马尔可夫决策过程理论(MDPs)联系起来。 随后,将人工智能规划研究与MDP联系起来的工作大量涌现,强化学习领域在机器人和过程控制方面得到了应用,并获得了深厚的理论基础。
人工智能对数据、统计建模、优化和机器学习的新认识带来的一个后果是,计算机视觉、机器人技术、语音识别、多智能体系统和自然语言处理等子领域的逐渐统一,这些子领域在某种程度上已经脱离了核心人工智能。 重新整合的过程在应用方面产生了巨大的好处——例如,在这一时期,实用机器人的部署大大扩展了——以及对人工智能核心问题的更好的理论理解。
7 大数据(2001 - ): 随着互联网的发展,大量的数据(图片,文字,社交网站数据)带来了对大数据集的学习算法的提升,现在很多时候机器在某些智能的任务上要比人类要强大。而且众所周知,商业上目前也非常重视。
8 深度学习(2011 - ):这个到相关章节会介绍的。
| Road |
(๑•̀ㅂ•́) ✧)你看完第三小节了,这小节聊的也很多,累就先休息一下吧
| Road |
1.4 The State of the Art (AI领域最新发展(大概截止2019年左右的数据))
人工智能系统何时(如果有的话)能在各种各样的任务中实现人类水平的表现? 福特(2018)采访了人工智能专家,发现他们认为的年份范围很广,从2029年到2200年,平均为2099年。 在一项类似的调查中(Grace等人,2017年),50%的受访者认为这可能在2066年发生,尽管10%认为最早可能在2025年发生,少数人说“永远不会”。 专家们对于我们是需要根本性的新突破,还是只是对现有方法进行改进也存在分歧。 但不要把他们的预测太当真; 正如Philip Tetlock(2017)方面所证明的那样,在预测世界事件上专家并不比业余爱好者测的准。
未来的人工智能系统将如何运作? 我们无法预知。 正如本节所详细介绍的,首先是最早机器智能甚至可能出现的大胆想法,然后是它可以通过将专家知识编码到逻辑中来实现,然后关于世界的概率模型将是主要工具, 而最近的研究表明,机器学习可以归纳出一些模型,而这些模型可能根本就不是基于任何众所周知的理论。 未来将会揭示接下来的模式。
1.5 Risks and Benefits of AI
一项技术所附带的后果有好有坏,此处所说的好坏是这项技术本身可能带来的方向,某些方向对我们是不利的,而某些则是有利的。
从好处开始:简单地说,我们整个文明都是人类智慧的产物。 如果我们有机会获得更大的机器智能,我们的雄心壮志的上限就会大大提高。 人工智能和机器人将人类从单调的重复性工作中解放出来,并大幅提高商品和服务的产量,这一潜力可能预示着一个和平与富足的时代。 加速科学研究的能力可以治愈疾病,解决气候变化和资源短缺问题。 正如谷歌DeepMind首席执行官戴米斯•哈萨比斯(Demis Hassabis)所建议的:“首先解决人工智能,然后用人工智能解决所有其他问题。”
然而,在我们有机会“解决人工智能”之前很久,我们就会因滥用人工智能(无意或其他原因)而招致风险。 其中一些已经很明显,而另一些似乎是基于当前的趋势:
- 致命的自动武器
- 监测和说服(Surveillance and persuasion):在机器学习的帮助下,监控个人的信息流和发现个人的兴趣所在变得非常容易,有些政客可能通过微操公民的数据流推荐而改变选民的政治倾向,自从2016年,这已经在选举中开始发生(美国)
- 具有偏见的决策:故意使用或者误用机器学习算法会导致基于种族,性别和其他不利于社会发展的歧视,而这些带有“偏见”的数据也能反映社会中的普遍偏见。(像2021年爆出的美团的外卖员被算法压榨也是类似)
- 影响就业率
- 对安全性要求苛刻的应用程序 :比如说自动驾驶,城市智能控制系统这些关系到人命的需要得到一些安全标准的进一步控制
- 网络安全:网络诈骗非常多,目前不知道打压的力度怎么样(2021年6月开始B站TOM表哥的反诈视频,2021年9月中国反诈中心APP在快手的宣传)
另外的问题是,通用人工智能或者超人工智能可能吗?作者分析到问题的来源在于我们对于AI控制的不确定性,如果我们设计一个AI系统但AI却越权自己进行了控制,那么这可以认为是设计失败的结果。具体的可能性还需要在后续章节中了解AI目前具体的内容,我们才能有进一步了解。
总结
一些重要的点:
- 不同的人对待人工智能有不同的目标。 要问的两个重要问题是:你关心的是思考还是行为? 你是想建模人类,还是试图达到最佳结果?
- 根据我们所说的标准模型,人工智能主要与理性行为有关。 一个理想的智能体会在一种情况下采取最好的行动。 我们研究在这个意义上构建智能化agent(参见1.1.4)的问题。
- 对于第二点的想法,有两点需要改进:首先,任何agent,无论是人类还是其他agent,选择理性行为的能力都受到计算的intractability的限制; 第二,机器追求明确目标的概念需要被机器追求造福人类的目标的概念所取代,但我们不确定这些目标是什么。
- 哲学家们(追溯到公元前400年)认为,在某种程度上,大脑就像一台机器,它运行于某种由内部语言编码的知识,思维可以用这些知识选择采取什么行动,从而使人工智能成为可能。
- 数学家们提供了操作逻辑确定性的陈述以及不确定的、概率性的陈述的工具。 它们也为理解计算和算法推理奠定了基础。
- 经济学家将决策的问题形式化,使决策者的预期效用最大化。
- 神经科学家发现了一些关于大脑如何工作的事实,以及大脑与计算机的相似和不同之处。
- 心理学家采纳了人类和动物可以被视为信息处理机器的观点。 语言学家表明,语言使用符合这一模式。
- 计算机工程师提供了越来越强大的硬件,使人工智能应用成为可能,软件工程师使它们更易于使用
- 控制理论研究的是在环境反馈的基础上设计出行为最佳的设备。 最初,控制理论的数学工具与人工智能中使用的工具非常不同,但这两个领域正变得越来越接近。
- 人工智能的历史经历过成功,错误的乐观,以及由此导致的热情和资金削减的循环。 此外,还存在着引入新的、有创意的方法和系统地完善最佳方法的周期。
- 与最初几十年相比,人工智能在理论和方法上都已相当成熟。 随着人工智能处理的问题变得越来越复杂,该领域从布尔逻辑转向概率推理,从手工知识(hand-crafted knowledge)转向从数据中进行机器学习。 这导致了实际系统能力的改进以及与其他学科的更多融合。
- 随着人工智能系统在现实世界中得到应用,有必要考虑广泛的风险和伦理后果。
- 从长远来看,我们面临着控制超级智能人工智能系统的难题,这些系统可能会以不可预测的方式进化。 要解决这个问题,似乎就必须改变我们对人工智能的看法。
第一章就这样结束了,
感兴趣的可以去看看 官网的第一章练习题
