
一行代码解决scp在Internet传输慢的问题


遇到一个迟来的case,用scp在长链路上传输文件竟然慢到无法忍受!100~200毫秒往返时延的链路,wget下载文件吞吐可达40MBps,scp却只有9MBps。
我开始以为这是加密带宽损耗所致,然而用HTTPS测试却正常。
为了避免pacing平滑掉边沿事件,设置CC为CUIBIC,抓包抓到如下trace波形:
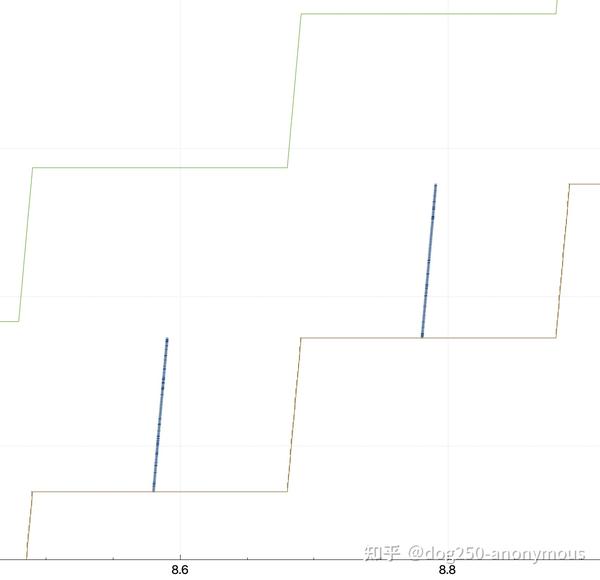

这要么是一个rwnd limited的场景,要么是app limited的场景,肯定不是cwnd limited的场景,我并没有模拟任何丢包和限速。
strace确认是否有setsockopt来设置收发buffer:
$ sudo strace -f -F -e trace=setsockopt -p 1181607
...
[pid 1181977] setsockopt(5, SOL_SOCKET, SO_RCVBUFFORCE, [8388608], 4) = 0
[pid 1181977] setsockopt(5, SOL_SOCKET, SO_SNDBUFFORCE, [8388608], 4) = 0
...用下面的代码bypass一下setsockopt排除影响:
#define _GNU_SOURCE
#include <dlfcn.h>
#include <stdio.h>
#include <sys/socket.h>
typedef int (*orig_setsockopt_f_type)(int sockfd, int level, int optname,
const void *optval, socklen_t optlen);
int setsockopt(int sockfd, int level, int optname,
const void *optval, socklen_t optlen)
{
int size;
orig_setsockopt_f_type orig_setsockopt;
orig_setsockopt = (orig_setsockopt_f_type)dlsym(RTLD_NEXT,"setsockopt");
if (optname == SO_SNDBUFFORCE || optname == SO_RCVBUFFORCE ||
optname == SO_SNDBUF || optname == SO_RCVBUF) {
//size = *(int *)optval;
//size *= 10;
//*(int *)optval = size;
return 0;
}
return orig_setsockopt(sockfd, level, optname, optval, optlen);
}
// gcc -shared -fPIC -o bypass.so bypass.c -ldl
// LD_PRELOAD=/root/bypass.so /usr/sbin/sshd -D
// LD_PRELOAD=/root/bypass.so scp root@192.168.56.101:/var/www/html/big /dev/null结果依旧。
我写这篇文章的目的不是为了描述如何优化这个case的过程,而是摆一个观点,涉及到网络传输的优化,若不懂协议,仅局限在主机协议栈和编程范畴,很容易陷入细节的深渊。
我并不精通SSH协议,要花点时间去看规范,这花了几乎一个晚上的时间,最终我get到了问题的核心:
- SSH允许在一个TCP连接上复用多个channel,需要对每一个channel做流控以保证公平,所以每个channel必须自己做而不是使用TCP的流控,OpenSSH的实现有问题。
由于历史原因,不光SSH,很多协议在做端到端流控的时候,均未考虑网络本身的BDP,包括TCP协议。假设带宽无限大且无丢包,接收端处理速率一定,下一批数据到达之前,相对于比较近发送端,接收端需要等待远发送端更久的时间,若想让这段时间内接收端有数据可处理,远发送端必须发送更多的数据。
这里解释一下pacing发送和burst发送和接收窗口的关系:
- pacing发送:需要保证pacing rate和接收端的处理速度一致。
- burst发送:需要保证两次burst间的平均速率和接收端的处理速度一致。
需要确认OpenSSH是如何维护channel接收窗口的,是否有考虑到BDP的影响。
简单猜测就是没有,因为在TCP层都很难精确采集到这些信息,就更别提在应用程序中了。
下载OpenSSH代码:
git clone git://anongit.mindrot.org/openssh.git找到封装WINDOW_ADJUST报文的函数channel_check_window,果然没有考虑BDP,相当于完全按照接收端channel单位时间处理能力来通告窗口。
打开debug,可以看到无论设置多少的时延,接收端的通告窗口都是随着处理能力而固定变化的:
debug2: channel 0: window 1982464 sent adjust 114688这像极了《UNIX网络编程》里面的my_read函数。
改了它便是,为通告窗口增加一个小余量,用来平滑网络传输中的等待时间:
// 修改数据接收端的该函数。
static int
channel_check_window(struct ssh *ssh, Channel *c)
{
int r;
if (c->type == SSH_CHANNEL_OPEN &&
!(c->flags & (CHAN_CLOSE_SENT|CHAN_CLOSE_RCVD)) &&
((c->local_window_max - c->local_window >
c->local_maxpacket*3) ||
c->local_window < c->local_window_max/2) &&
c->local_consumed > 0) {
if (!c->have_remote_id)
fatal_f("channel %d: no remote id", c->self);
if ((r = sshpkt_start(ssh,
SSH2_MSG_CHANNEL_WINDOW_ADJUST)) != 0 ||
(r = sshpkt_put_u32(ssh, c->remote_id)) != 0 ||
//(r = sshpkt_put_u32(ssh, c->local_consumed)) != 0 ||
// 增加2000试试效果!
(r = sshpkt_put_u32(ssh, c->local_consumed + 2000)) != 0 ||
(r = sshpkt_send(ssh)) != 0) {
fatal_fr(r, "channel %i", c->self);
}
debug2("channel %d: window %d sent adjust %d", c->self,
c->local_window, c->local_consumed);
c->local_window += c->local_consumed;
c->local_consumed = 0;
}
return 1;
}就改了这一行代码,效果杠杠的,看下效果,左边是接收端速率,右边是发送端CPU利用率。先看没改之前的怂样子:


改过那一行之后:


CPU被加解密跑满了,发包迅猛。
我试着将余量增加,企图更快到达极限,传输过程中得到了错误:
client_loop: send disconnect: Broken pipe
lost connection这是意料之中的,因为余量会逐渐积累,直到overflow。正确的做法应该在每次通告时减去已经使用的部分后再增加余量。
只改一行代码只能保证积累余量溢出之前传输完毕的正确性,若要修改这个问题也不难,多改几行代码便是:
static int
channel_check_window(struct ssh *ssh, Channel *c)
{
int r;
+ int extra = 0;
if (c->type == SSH_CHANNEL_OPEN &&
!(c->flags & (CHAN_CLOSE_SENT|CHAN_CLOSE_RCVD)) &&
((c->local_window_max - c->local_window >
c->local_maxpacket*3) ||
c->local_window < c->local_window_max/2) &&
c->local_consumed > 0) {
+ // 不能超过SO_RCVBUF设置的8388608那么大
+ if (c->local_window_max < 8000000) {
+ extra = 200000;
+ c->local_window_max += extra;
+ }
if (!c->have_remote_id)
fatal_f("channel %d: no remote id", c->self);
if ((r = sshpkt_start(ssh,
SSH2_MSG_CHANNEL_WINDOW_ADJUST)) != 0 ||
(r = sshpkt_put_u32(ssh, c->remote_id)) != 0 ||
- (r = sshpkt_put_u32(ssh, c->local_consumed)) != 0 ||
+ (r = sshpkt_put_u32(ssh, c->local_consumed + extra)) != 0 ||
(r = sshpkt_send(ssh)) != 0) {
fatal_fr(r, "channel %i", c->self);
}
debug2("channel %d: window %d sent adjust %d", c->self,
c->local_window, c->local_consumed);
c->local_window += c->local_consumed;
+ // local_window 加上余量。
+ c->local_window += extra;
c->local_consumed = 0;
}
return 1;
}OK,问题解决。
虽然最终改了不止一行,但也不多,大概不到10行吧。但这终究只是一个POC,问题是余量如何随着不同的环境而自适应,其实倒也不难,只要可以计算当前的内核TCP缓冲余量即可,以此作为余量就行,而TCP缓冲区可以通过getsockopt获取。
说到底还是要看协议而不是代码,靠手艺而不是靠工具。
如果不懂SSH协议多channel复用TCP,就不知道channel流控,这是scp程序app limited的根源。不懂这个就很难找到要改哪一行,代码工具玩得再溜,再精通语言混社区,不懂协议则寸步难行。
为了让事情规范化,工程化,我感觉无能为力,也不知上述修改的隐患。我承认我无力折腾场面宏大的事情。
通过查阅各种资源,幸运的是,2004年就有人意识到这个问题并且做了伟大的事情,这就是HPN-SSH:
同时我找到了一个HPN-SSH的作者对该问题的解释:
下面是一个关于SSH性能问题的总览:
期待Chris Rapier的HPN-SSH可以早日合入OpenSSH主线,完美期待!
好了,这就是本周我要讲的故事。
浙江温州皮鞋湿,下雨进水不会胖。