![[L4]使用LSTM实现语言模型-softmax与交叉熵](data:image/svg+xml;utf8,<svg xmlns='http://www.w3.org/2000/svg'></svg>)
[L4]使用LSTM实现语言模型-softmax与交叉熵

这个专栏只会介绍一些代码技术实战,此文借鉴《tensorflow实战Google学习框架》不会涉及理论,如果想要了解理论可以去下面这个专栏:
使用LSTM实现语言模型系列地址:
在介绍完了如何处理数据以及如何构造样本之后,就可以构建我们的神经网络语言模型了,下面是使用LSTM构建的语言模型的大体结构:

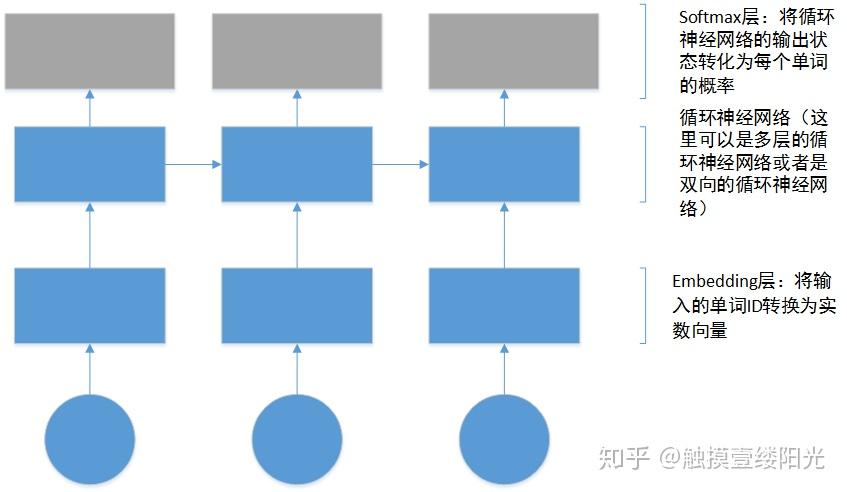
那可以看出上面着重写出来的两层:
- embedding层;
- softmax层;
那接下来介绍softmax层。
1.Softmax层
使用循环神经网络训练语言模型,对于每个cell,其实都相当于是一个有监督的多分类任务,每个词汇表中的单词代表一个类别。如下图所示:
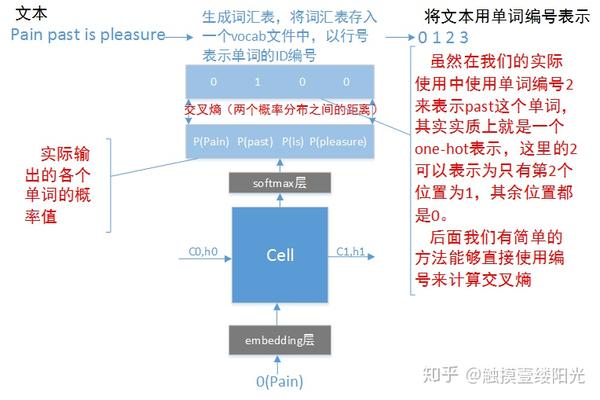

当训练的时候,我们要做的就是使得输出向量和期望向量(样本label)越接近越好,那交叉熵就是评判两个概率分布之间的距离的常用方法之一。然而神经网络的输出确不一定是一个概率分布,所以这就有了softmax,softmax能够将神经网络前向传播的结果变成一个概率分布,其实可以把softmax当成一个额外的处理层,他把神经网络的输出变成了一个概率分布,也就是每一个输出都是(0~1)之间的小数,并且所有输出的结果之和为1。通过这样的处理,我们就可以轻松的使用交叉熵损失函数来计算真实分布与期望分布的距离,并通过梯度下降算法通过降低交叉熵损失以拟合样本训练模型。
下面看一看softmax是怎么计算的:
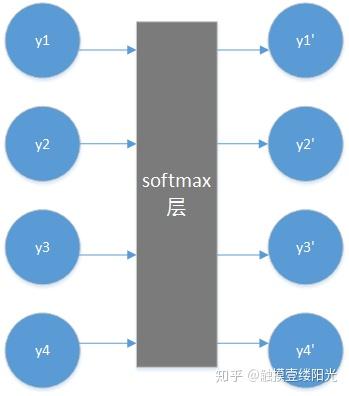
现在我的神经网络有四个输出 y_{1}\ y_{2}\ y_{3}\ y_{4} ,那么经过softmax处理后的输出为:
softmax(y_{i}) = y_{i}^{'} = \frac{e^{y_{i}}}{\sum_{j = 1}^{4}{e^{y_{j}}}} ,通过softmax我们可以计算出 y_{1}^{'}\ y_{2}^{'}\ y_{3}^{'}\ y_{4}^{'} 的值
通过上面的描述我们可以知道,加入softmax层是为了将神经网络的输出转换为概率分布,进而使用交叉熵来计算神经网络输出的概率分布和期望的概率分布之间的距离。
对于使用softmax层处理,可以分成两个步骤:
- 使用线性映射将循环神经网络的输出映射为一个维度与词汇表大小相同的向量,这一步的输出叫做logits,其实也就是神经网络实际的输出值(没有加入softmax时候的 y_{1}\ y_{2}\ y_{3}\ y_{4} );
- 调用softmax将logits转化为加和为1的概率,我们可以直接使用tf.nn.softmax(logits)来得到转换后的概率向量;
2.Softmax与交叉熵
在训练语言模型以及对训练好的语言模型的评估好坏(perplexity实际上也是一个交叉熵)的时候,都会用到交叉熵损失函数。而由于softmax和交叉熵损失函数经常一起使用,所以tensorflow对这两个功能进行了统一的封装,并提供了两个函数(当然你也可以分成两步写,先获得经过softmax层得到的结果,然后放入交叉熵的计算公式中进行计算):
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(lables = y_,logits = y)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(lables = y_,logits = y)那这两个函数有什么区别呢,我们现在一个个的介绍:
- cross_entropy = tf.nn.softmax_cross_entropy_with_logits(lables = y_,logits = y)
import tensorflow as tf
word_prob_distribution = tf.constant([[0.0,0.0,1.0,0.0],[1.0,0.0,0.0,0.0]])
#假设模型对两个单词的预测时,产生logits分别是[2.0,-1.0,3.0,2.0],[1.0,0.0,-0.5,4.0]
#这个时候的predict_logits是没有经过softmax层处理的y1,y2,y3,y4
predict_logits = tf.constant([[2.0,-1.0,3.0,2.0],[1.0,0.0,-0.5,4.0]])
#使用softmax_cross_entropy_with_logits
loss = tf.nn.softmax_cross_entropy_with_logits(logits = predict_logits,labels = word_prob_distribution)
sess = tf.InteractiveSession()
print(loss.eval())
sess.close()
'''[ 0.56194139 3.07623076]'''- cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(lables = y_,logits = y)
import tensorflow as tf
#假设词汇表的大小为4,语料中包含两个单词[2,0],单词在词汇表中的ID编号
word_prob_distribution = tf.constant([2,0])
#假设模型对两个单词的预测时,产生logits分别是[2.0,-1.0,3.0,2.0],[1.0,0.0,-0.5,4.0]
#这个时候的predict_logits是没有经过softmax层处理的y1,y2,y3,y4
predict_logits = tf.constant([[2.0,-1.0,3.0,2.0],[1.0,0.0,-0.5,4.0]])
#使用sparse_softmax_cross_entropy_with_logits
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits = predict_logits,labels = word_prob_distribution)
sess = tf.InteractiveSession()
print(loss.eval())
sess.close()
'''[ 0.56194139 3.07623076]'''会发现两个函数的输出结果是相同的,那这两个函数的唯一区别就在于表示真实单词分布的不同,在第一个函数中,我们使用one-hot的表示方式,而在第二个函数中我们使用单词在向量中的最大值的位置,从输出的结果相同也可以看出来,这两种表示方式其实是一样的,在我们的样例中在处理文本的时候,只是将其转换为了词汇表中的对应ID号,并没有将其转换为one-hot(其实他们是等价的),因为其实我们可以使用sparse_softmax_cross_entropy_with_logits函数通过对应单词的词汇表的ID编号也可以轻松的得到交叉熵的loss值。
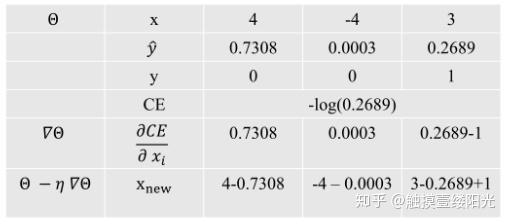
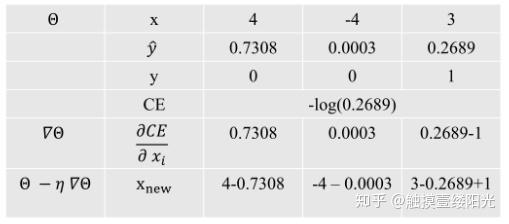
那softmax + 交叉熵有什么效果呢?下面一个使用softmax+交叉熵的三个输出的神经网络计算流程,只需看最后一行,可以看出梯度下降更新的结果:
- 先将所有的logits值先减去对应的softmax的值,也就是推所有;
- 然后将真实标记中的对应位置的值加上1,也就是拉一个;
顺便说一句,由于softmax层以及embedding层的参数占所有参数的比重很大,所以通常我们共享embedding层以及softmax层的参数,这样不仅可以大幅度的减少参数数量而且还能够提高最终模型的效果。
