
Hierarchical Z-Buffer Occlusion Culling到底该怎么做?

Hierarchical Z-Buffer Occlusion Culling做为GPU-Driven Rendering Pipelines中的重要一环,它肩负着遮挡剔除的重任,但是无论是大革命原文还是其他作者的分析,对于这块的解释都比较模糊。因此我想分享一下自己对Hierarchical Z-Buffer Occlusion Culling的理解,如果哪里有问题或者没有想到,真诚希望大家能够指出。言归正传,让我先从基于屏幕空间的遮挡剔除说起。
无论是CPU做遮挡剔除还是GPU做遮挡查询,核心的思想都是将包围体光栅化到屏幕空间,如果包围体覆盖的所有像素都被遮挡,那么就可以断言这个包围体被遮挡了。CPU做遮挡查询会占用大量CPU资源,这不符合GPU-Driven Rendering Pipelines的核心思想,而GPU做遮挡查询有两个问题,一是GPU遮挡查询会照成渲染流程的feedback,当然这个问题可以通过时间一致性解决,但是需要引入复杂的算法,二是GPU遮挡查询依然需要光栅化包围体,对GPU也会造成不小的压力。
Hierarchical Z-Buffer Occlusion Culling算法可以直接获得遮挡的结果,不需要等待GPU的feedback,而且也不需要光栅化包围体,它是使用GPU处理的,而且规避了GPU遮挡查询的两个问题,因此它成为了GPU-Driven Rendering Pipelines的主流遮挡剔除算法,但是它也有它的问题,这个我们稍后再说,先来看看Hierarchical Z-Buffer Occlusion Culling的算法。
准备Hierarchical Z-Buffer,首先我们需要获得一张深度图,这样深度图包含了遮挡体的深度信息,接下来我们需要进行降采样生成深度图的mipmap层级,这里和传统的mipmap区别是降采样生成的mipmap存储的是深度的最大值而不是平均值。
遮挡查询,基本思想是我们需要将被遮挡体的包围盒投影到屏幕空间,然后找到一个mipmap层级使其包围盒只覆盖2x2个像素。为什么要这么做呢?因为这样我们只需要比较4个像素的深度值就可以判断遮挡关系,如果包围盒覆盖更多的像素,我们就需要将其光栅化,找到所有覆盖的像素进行比较,也是因为这个设计让我们避免了光栅化的操作。这块我们可以这样理解,假如场景中有一面墙,这面墙挡住了一个立方体,那么当我们将相机拉远,墙和立方体占用的像素会越来越少,最后立方体只占了4个像素,但是立方体和墙的遮挡关系并没有发生变化。这里有个问题,既然是这样为什么我们不继续降采样让其像素变为1然后只需要比较一个像素的深度呢?这样做不是不行,但是这样做会更麻烦,如下图:
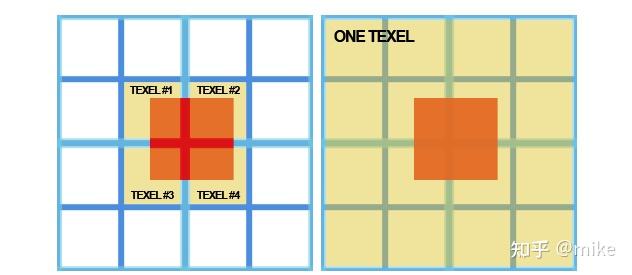

这个问题我们可以这样理解,极端情况下,包围盒的中心恰好在屏幕的正中心,那么它想被一个像素覆盖,只能是最高层级的LOD了(只有一个像素的LOD层)。这会降低遮挡剔除的命中率,让本应该被剔除的物体没有被剔除。
我们首先可以获得被遮挡体包围体的8个顶点信息,然后将其转化到屏幕空间,算出在屏幕空中uv方向的包围盒,根据Hierarchical Z-Buffer Level 0层的分辨率,我们可以算出包围盒在uv方向上覆盖了多少个像素,然后选择覆盖更多像素的方向计算出mipmap层级。用屏幕空间的包围盒的顶点做为uv坐标,在选中的mipmap层级采样获得深度值,如果这四个深度值都比被遮挡体的顶点的最小深度还要小,那么说明这个物体被遮挡了。还是想象一个墙挡住了立方体,相机拉远的时候,墙覆盖的像素会越来越少,但是深度值会越来越大,立方体覆盖的像素值也会越来越少,但是值始终是最小深度值。因此Hierarchical Z-Buffer Occlusion Culling是一个保守算法,它宁可少剔除也不愿意错误剔除。
理解了Hierarchical Z-Buffer Occlusion Culling接下来的内容是重点,我们在读大革命paper的时候会听到一个词洞,这个洞是什么?如果我没有理解错误的话,这个洞翻译的太差了。还是通过脑补,假设我们场景中只有一个面墙,在墙的后面有一个更大的建筑物,这个墙根本就挡不住这个建筑物。我们先生成Hierarchical Z-Buffer,因为场景中只有一个墙,先把墙的深度渲染进去。但是屏幕中还有很多像素没有被渲染,这些像素我们填充什么?如果填1可想而知很多物体会无法剔除,因为降采样会让高层的mipmap深度变为1。如果填写0那么就会出现错误剔除,比如上面脑补的情况,后面的建筑可能会选择很高的mipmap层级,而mipmap层级中的最大深度就是墙的深度,所以最后这个建筑物会被剔除。因此我理解论文中提到的洞,应该是没有深度信息的地方。如果Hierarchical Z-Buffer中有些像素没有被场景的深度值填写,就可能会出现错误的剔除,因为大革命选择默认值为0。
理解了这个后面的问题就简单了,Hierarchical Z-Buffer Occlusion Culling算法有两个问题需要处理,一是渲染Hierarchical Z-Buffer会造成性能损失,二是如果Hierarchical Z-Buffer中有些像素没有被深度填充,有可能会造成错误剔除,让我们看看大革命是怎么处理的。


先挑选最近的300个遮挡体做全屏分辨率渲染,这张图不仅可以用来做Hi-z还可以做Early-Z。为什么不直接用上一帧的深度图呢?第一,重映射的时候必然会存在有些像素不在相机中,导致深度图中出现了"洞",我们可以使用这张图来补"洞"(实际上它们两个是互相补洞)。第二,如果相机移动过大,遮挡剔除效果会很差,所以需要更新当前帧的深度信息。
论文后面也给出了另外一个算法就是不渲染遮挡体,直接使用上帧的深度图,但是这样做剔除命中率不高还有错误剔除,因此还需要等深度信息更新后再重新做一遍剔除,找到错误剔除的物体,重新渲染,两种方法实际上都是在性能和解决洞的问题找平衡。
除了主相机需要遮挡剔除,shadow map的渲染也需要遮挡剔除,使用的方法和主相机类似,但是对于某些场景shadow map的遮挡剔除效果并不好,如下图:
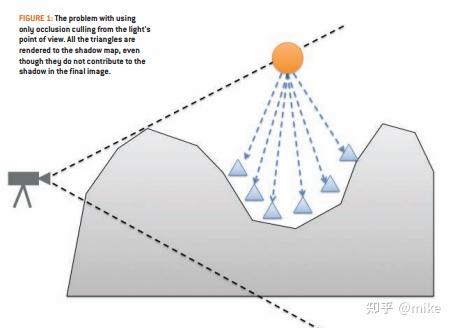
上图中的三角形没有被遮挡剔除,但是实际上它们也不需要渲染到shadow map中,因为接收阴影的部分被遮挡了。我们需要根据主相机的遮挡关系来为shadow map推导出一张深度图,用来做遮挡剔除,剔除上面的三角形。
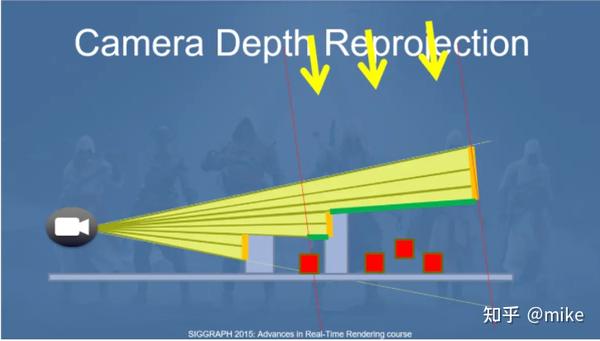

上图中的绿线就是我们所求的深度图。将主相机的深度图均分成等大的tile比如16*16个像素,然后选择最大的深度做为Z值,使用tile的四个顶点的x,y值,将其反推到相机空间,这样我们就在相机空间中获得了4个顶点,接下来在相机的近平面上沿着Z方向映射四个顶点这样我们就获得了一个长方体,将这个长方体变换到shadow map空间中进行渲染,深度图中保留最大深度,这样每一个tile就会变成一个长方体,每个长方体可以理解为shadow map的遮挡体,用这些遮挡提可以获得一张Hierarchical Z-Buffer用来做遮挡剔除。
Hierarchical Z-Buffer Occlusion Culling在实际项目中还是有很多坑需要填的,但是理解了背后的原理,了解了需要解决的问题,剩下的就是工作量的问题了。