DolphinDB与Pandas对于大文本文件处理的性能对比




DolphinDB是一款高性能的分布式时序数据库。它集成了功能强大的编程语言和高容量高速度的流数据分析系统,为海量数据(特别是时间序列数据)的快速存储、检索、分析及计算提供一站式解决方案。
Pandas是Python的一个包,最初被作为金融数据分析工具而开发,为时间序列分析提供了很好的支持。
DolphinDB是一个分布式系统,但也可以作为工作站使用。DolphinDB和Pandas都能够处理大文本文件,哪个的表现更出色呢?在处理大文本文件时,我们最关心的两个因素是性能和内存占用情况。因此,我们将从这两方面对DolphinDB和Pandas进行对比。
本次测试使用的硬件和操作系统如下:
Dell PowerEdge R830 服务器
内存:1024GB
CPU:E5-4640 v4 48 核 2.1GHZ
操作系统:Fedora27
RAID 0:8X1.2TB 10000 RMP HDD
DolphinDB提供了修改内存使用限制的配置项,所以我们把内存限制设置为128G,24核,这更符合大部分实际用户的服务器配置。而在Pandas中,我们无法对内存使用进行限制。
- 数据生成
我们在 DolphinDB database 中生成一个40G文本文件,包含了16列,一共有390,000,000行数据。生成数据的脚本如下:
n=390000000
workDir = "/data"
if(!exists(workDir)) mkdir(workDir)
sample=table(rand(string('A'..'Z') + "XXXX",n) as sym, 2000.01.01+rand(365,n) as date, 10.0+rand(2.0,n) as price1, 100.0+rand(20.0,n) as price2, 1000.0+rand(200.0,n) as price3, 10000.0+rand(2000.0,n) as price4, 10000.0+rand(3000.0,n) as price5, 10000.0+rand(4000.0,n) as price6, rand(10,n) as qty1, rand(100,n) as qty2, rand(1000,n) as qty3, rand(10000,n) as qty4, rand(10000,n) as qty5, rand(10000,n) as qty6)
sample.saveText(workDir + "/trades_40G.txt")2. 性能和内存占用比较
计算时间:
在DolphinDB中使用timer函数,在Pandas中使用%time。
内存占用:
我们可以使用Linux命令htop来监视DolphinDB和Pandas的内存占用情况。我们不仅记录了任务执行前后的内存占用,还记录了内存占用的峰值。
3. 测试结果和结论
我们主要测试了文本加载和其他基本操作,如添加计算列、分组、更新和使用窗口函数增加列。测试脚本见附录。测试结果如下表所示。为了减少特殊值的影响,我们把每个测试脚本都执行了10次,表中的时间是10次的执行总用时。
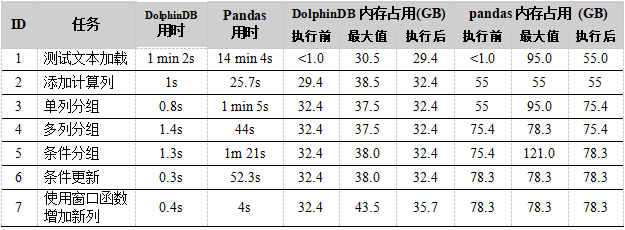

从测试结果中,我们可以得出以下结论,DolphinDB在性能上比Pandas快1~2个数量级(10~100倍),并且内存占用通常小于pandas的1/2,DolphinDB内存占用的最大值仅为pandas的1/3到1/2。从结果可以看出,在pandas中对于一些特定任务如增加一列数据,内存占用在执行前后不会发生变化,这是因为pandas会预先分配一定的内存供后续使用。
附录1. 测试脚本


欢迎访问官网下载DolphinDB试用版
