Seq2Seq 预训练语言模型:BART和T5

自回归(autoregressive)语言模型,如GPT,采用从左向右单向解码的方式,适用于自然语言生成(NLG)任务。非自回归(non-autoregressive)语言模型,如BERT,每个时刻的输出都可以充分利用双向信息,适用于自然语言理解(NLU)任务,但是在NLG上表现不佳。如何利用两者的优点,打造一个既能适用于NLU任务,又能适用于NLG任务的语言模型?
背景:语言模型的结构
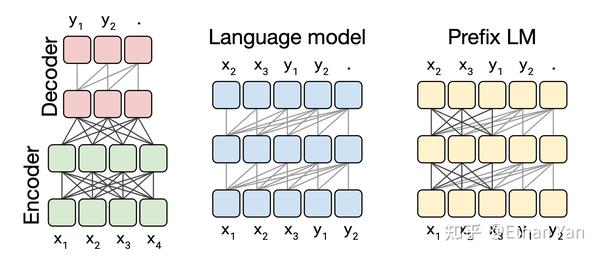
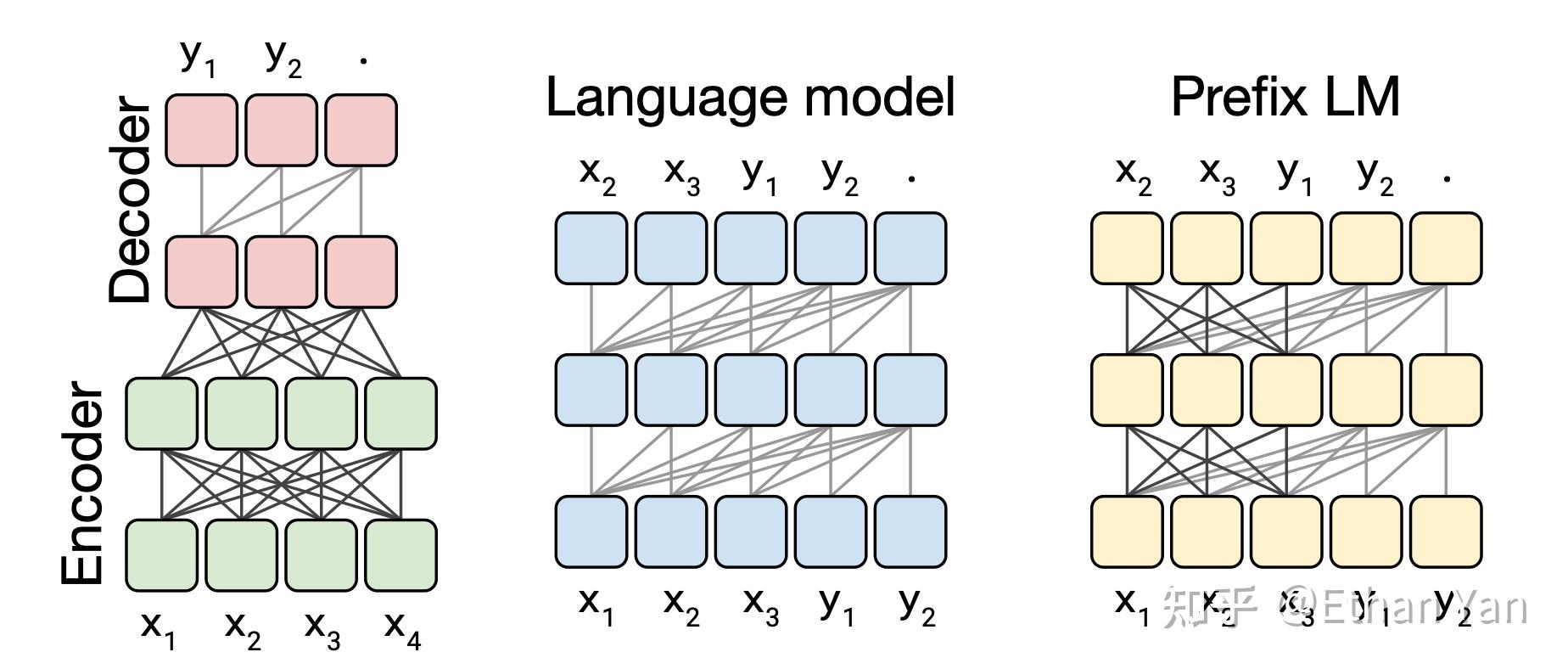
Transformers最早用于机器翻译任务,是一个Encoder-Decoder模型(如左图),其各模块被广泛应用于最近的语言模型。
- BERT使用它的Encoder(如左图下方)。
- GPT使用Decoder(如中间图,或左图上方)。
- UniLM将通过修改attention mask,将Encoder和Decoder结合,这种方式称作Prefix LM(如右图),结构上还是只使用了Encoder。BART和T5的结构则又回到了最原始的Transformers结构。
图中方块代表序列中的元素,线代表attention。深色的线代表全可见attention,浅色的线代表因果掩码(causal masking),即当前时刻只能看见之前的元素,不能看见未来的元素。
Attention的掩码矩阵如图所示:
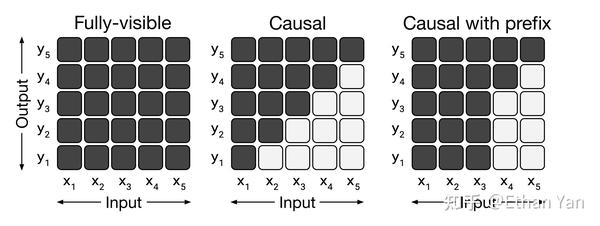

- 左图:完全可见矩阵,模型输出可以看见任意时刻的输入。Transformers 的 Encoder,BERT 用的就是这种掩码。
- 中图:因果掩码矩阵,模型输出只能看见当前时刻之前的输入(黑色部分),这样可以防止未来的输入干预当前输出的结果。Transformers 的 Decoder,GPT 等单向语言模型使用的就是这种掩码。
- 右图:带有前缀的因果掩码矩阵,前缀部分和完全可见矩阵一样,输出能够看见前缀任意时刻的输入,超过前缀范围使用因果掩码。UniLM采用这种掩码。
BART和T5
两个工作都是在2019年的10月发表在Arxiv上的。BART由Facebook提出,T5由Google提出。两者都不约而同地采用了Transformers原始结构,在预训练时都使用类似的Span级别去噪目标函数(受SpanBERT启发),但是两者还是有一些差别的:
动机
- BART想要统一BERT和GPT,从一开始就确定了使用Transformers的原始结构。BART探究了各种目标函数的有效性,即对输入加各种类型的噪声,在输出时将其还原。BART在NLU任务上保持了和RoBerta差不多的前提下,在多个NLG任务中取得了SOTA成绩。论文算上参考文献总共长度10页。
- T5其实是一篇关于语言模型的Survey,其思路是从头开始,找出语言模型的最优结构,在尝试了多种结构之后发现Seq2Seq结构是最好的,然后从模型的目标函数,数据集,训练时间,模型大小,多任务学习,等角度做了大量的实验,确定方向之后扩大模型规模,最终在多个NLU和NLG任务中达到了SOTA水平。此外,这个工作还产出了一个干净的大规模英文预料:C4。论文算上参考文献长达67页。
预训练任务
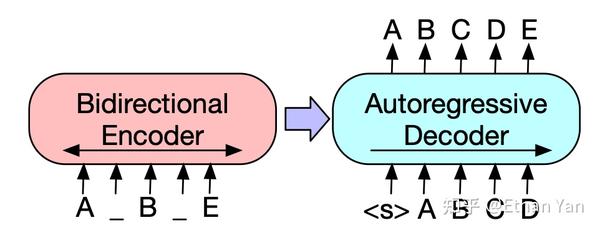
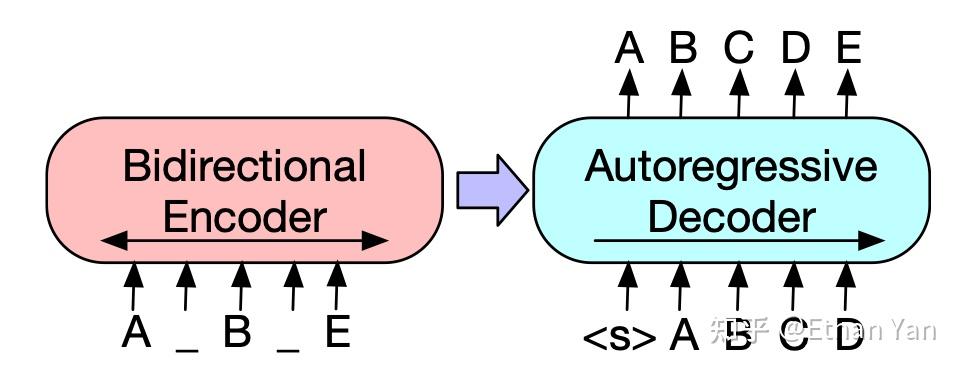
BART的预训练任务是将带噪声的输入还原。如下图所示,输入为ABCDE,在AB中插入一个span长度为0的mask,再将CD替换为mask,最终得到加噪输入的A_B_E。模型的目标是将其还原为ABCDE。
BART最终使用Text Infilling + Sentence permutation,其中Text Infilling起到了最主要的作用,其实就是Span级别的mask,只不过这里允许span长度为0,span的长度服从泊松分布,lambda = 3,总共mask30%的字符。Sentence permutation提升不大,之所以使用是作者假设模型规模提升后这个任务会有用。
T5使用两种任务,分为无监督和有监督。其中无监督任务也是Span级别的mask,不过输出不需要还原整句,只需要输出mask掉的tokens就可以,总共mask15%字符。有监督任务提升不大,这里不展开说明。


除了这种任务,T5还尝试了其他的任务类型,如下表所示。


这些任务可以,分为三类:前缀语言模型任务(Prefix language modeling),BERT风格任务(BERT-style之所以叫bert风格,是因为bert没有decoder,这里的decoder输出原句,和BART类似),打乱还原任务(Deshuffling)。这三个类型中,BERT风格效果最好。


然后尝试化简任务,前两行是输出原句的(类似BART),后两行是不需要输出原句的。这里的对比其实不太公平,后两个都是span的,前两个确是token级别的。这也是BART可能超越T5的一个因素。作者解释之所以继续沿着Replace corrupted spans探索是因为:1. 不需要输出原句,训练速度快。2. Drop corrupted tokens 这个任务和GLUE的下游任务CoLA类似导致分数虚高(60.04,而baseline才53.84),在SGLUE中其实分数很低。


微调
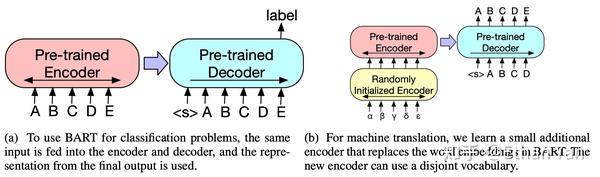
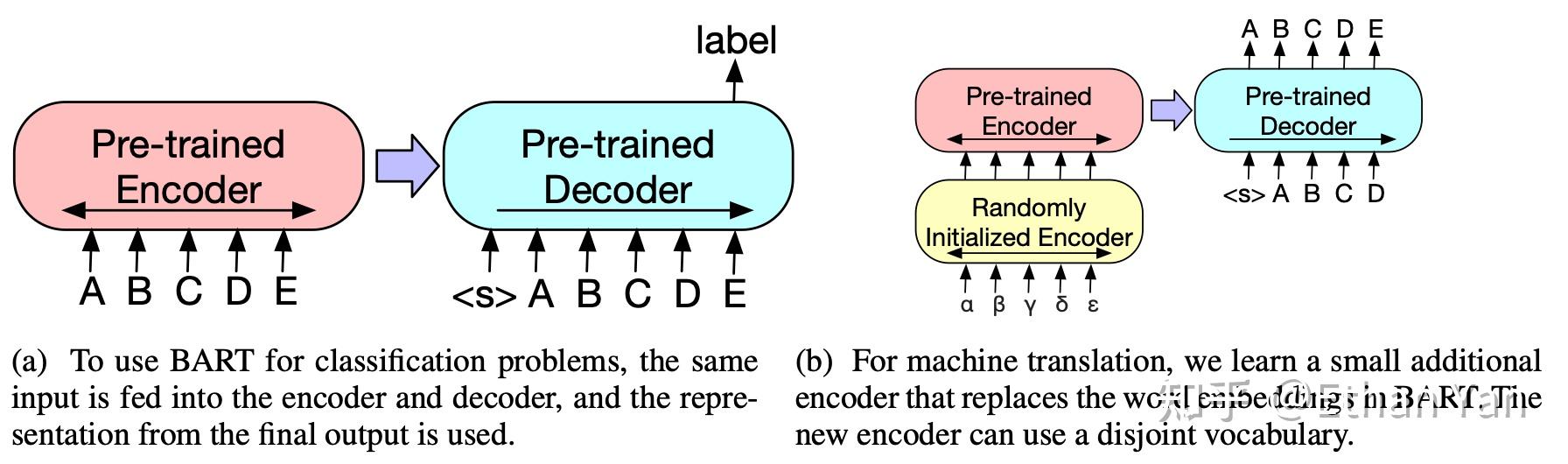
BART的微调方式如下图:
- 左边是分类任务的微调方式,输入将会同时送入Encoder和Decoder,最终使用最后一个输出为文本表示。
- 右边是翻译任务的微调方式,由于翻译任务的词表可能和模型词表不同,所以这里使用一个新的小型Encoder替换BART中的Embedding。
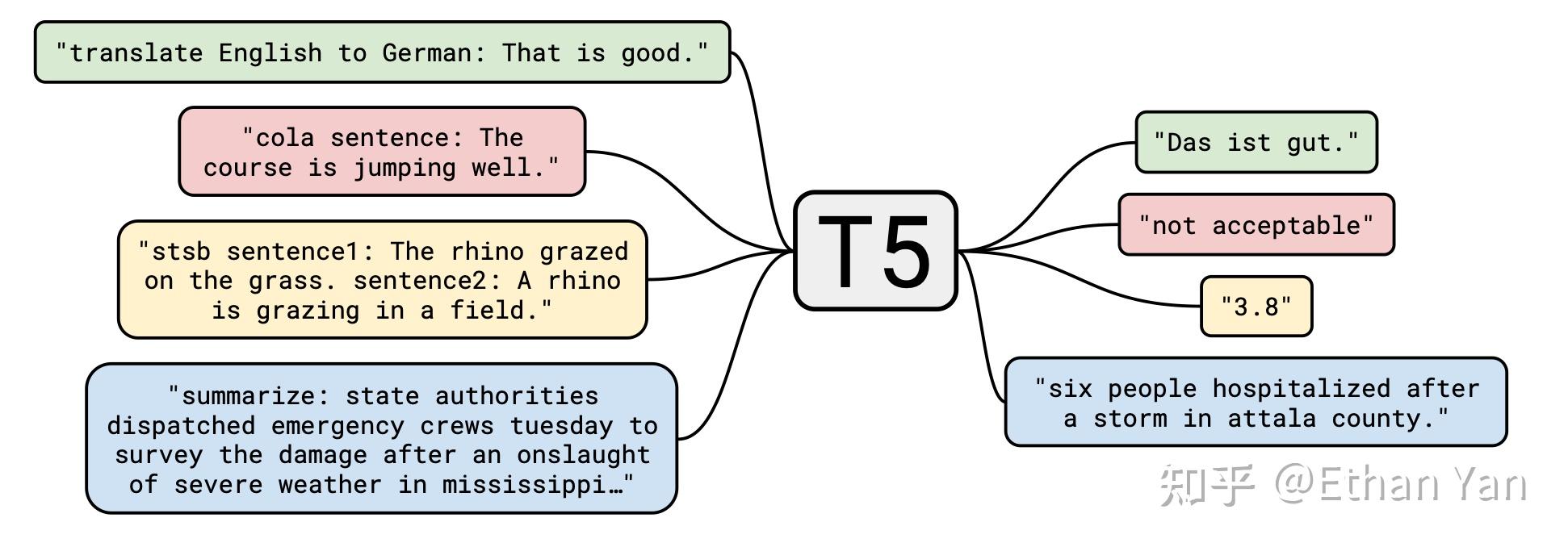
T5的微调方式如下图:
无论是分类任务,还是生成任务,全都视为生成式任务。

一些其他的细节
位置编码:
Transformers使用Position Encoding,使用sinusoidal函数
BERT和BART都换成了可学习的绝对位置嵌入
T5改成了相对位置嵌入(relative position embeddings)
激活函数:
Transformer最开始使用ReLU,BERT和GPT都使用GELU,BART也同样采用GELU,不过T5还是使用了最初的ReLU。
实验
T5的实验并没有直接和BERT这种只有encoder的模型比较,因为实验要完成一些生成任务,这种任务BERT无法完成的。
BART和T5发布的时间接近,论文中没有互相比较,不过我们可以从相同的任务中比较BART和T5。
训练数据
模型学习到的Token数量可以这样计算:Batchsize * seqlength * steps
BART: 8000 * 512 * 500 000
T5: 2048 * 512 * 1000 000
BART的训练数据是T5的两倍
模型大小
BART-large:12encoder, 12decoder, 1024hidden
T5-base:12encoder, 12decoder, 768 hidden, 220M parameters(2x bert-base)
T5-large: 24encoder, 24decoder, 1024hidden, 770M parameters
T5-large的模型大小是BART-large的两倍。
综合训练时间和模型大小,T5-large和BART-large可以互相比较,但是由于细节的实现上还有很多不同,这里仅作参考。
T5 vs BART
对于理解任务,将两篇论文中实验结果整理为下表:


对于生成任务,两个模型都在CNN/DailyMail上进行了实验


综合比较来看,BART稍微好一些,尤其是在理解任务上。不过由于T5发布的模型比较大,参数量最多达到了11B,所以在GLUE和SuperGLUE上长期霸榜。
参考资料
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
https://arxiv.org/abs/1910.13461
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
