一文搞懂Language Modeling三大评估标准

在机器学习特别是NLP岗面试时有一个非常常见的问题,是要求被面试者解释交叉熵和 BPC 之间区别。虽然很多人都用过这两个指标,但人与人之间的答案还是存在不小的差异,因为在实际使用时,大家并不思考为什么要用这些,或者它为什么被叫做这个名字。读完本文,你将知道Language Modeling三大评估标准: perplexity, cross entropy和Bits-per-character/bits-per-word(BPC/BPW)的概念和联系,以及它们为什么叫这些名字。本文不长,建议细读。
文章有些部分是从我的personal notes里面copy过来的,夹带了点私货,若有不严谨的地方敬请见谅。
若你想每天学一点新理论,可以关注一下本账号,以方便读到之后的文章。
Cheers~

最近各类基于深度学习的语言模型如 ULMFIT、BERT 和 GPT-2层出不穷,这些模型在做其他自然语言处理任务时取得了显著的成功。因此,语言模型也成了当前NLP领域的新宠。传统上,语言模型的性能是通过perplexity, cross entropy和Bits-per-character/bits-per-word (BPC/BPW)来衡量的,往往是这些值越低,模型的效果越好。随着语言模型被越来越多地用作其他 NLP 任务的预训练模型,它们通常也根据它们在下游任务上的表现进行评估,但是这三个评估标准依旧是评估语言模型使用最多的三大利器。
废话不多说,我们先上大家最喜欢看的结论,也就是三个评估标准的定义和联系:
Cross-entropy: H(P, Q) = -\sum_{x}P(x)logQ(x)
BPC/BPW: BPC/BPW(P, Q) = \frac{1}{T}\sum_{t=1}^{T}H(P, Q)
Perplexity:PPL(P, Q) = 2^{H(P, Q)}
关系很明确,在序列的language model评估任务中,BPC/BPW和Perplexity都是基于cross-entropy定义的。BPC/BPW是cross-entropy对句子长度的平均,Perplexity是以2为底的指数化cross-entropy。
那这三者到底在评估些啥?以及它们名字是啥意思?
Cross-entropy
在language modeling中,Cross-entropy就是衡量模型预测序列Q和真实序列P之间差异的指标。引用香农老哥在信息论中的一句话:“Entropy can be interpreted as the average number of bits required to store the information in a variable.”这句话意思就是说当我们的熵,也就是Entropy越小时,我们需要存储信息的bits数越少,因为信息的结构更有序了。那这里很容易就和我们的Cross-entropy联系起来了,既然都叫entropy,那么Cross-entropy对应要存储的信息是什么呢?
为了搞明白这个,我们进入大家最喜欢的公式推导环节,推一下Cross-entropy的公式:
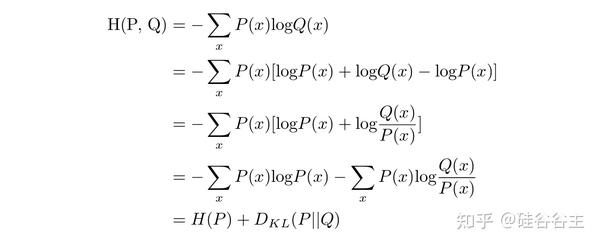

可以看到,从需要存储bit数的信息论角度,Cross-entropy可以被理解为以下两项之和:
- H(P) : 存储P序列的平均bit数。
- D_{KL}(P||Q) :基于预测的Q序列来编码P序列所需要的额外bit数。
显然,由于H(P)不能够被优化,因此我们优化模型的目的就是为了缩小Q和P的KL divergence,也就是基于Q,我们需要多少额外的bits来encode P,从而也体现了Cross-entropy的含义:是一种衡量P和Q之间差异的指标。在language modeling中,Cross-entropy就是衡量预测序列Q和真实序列P之间差异的指标。
Bits-per-character/bits-per-word (BPC/BPW)
在language modeling中,BPC/BPW也是衡量预测序列Q和真实序列P之间差异的指标,只不过做了一下平均。根据上面叙述的BPC/BPW和Cross-entropy之间有如下联系:BPC/BPW(P, Q) = \frac{1}{T}\sum_{t=1}^{T}H(P, Q),
也就是说BPC/BPW是cross-entropy对句子长度的平均,我们可以很容易地得出它的信息论含义:
基于预测的Q序列来编码P序列所需要的额外bit数在句子长度上的平均,也就是平均每一个字母/单词需要额外的bit数。这也是它名字的由来,也是我们为什么要从存储bit数量的角度来解释Cross-entropy。在language modeling中,BPC/BPW也是衡量预测序列Q和真实序列P之间差异的指标,只不过做了一下平均。
Perplexity
Perplexity仅仅是entropy的一个指数化形式:PPL(P, Q) = 2^{H(P, Q)}。若是要给予它一个含义,直观上,Perplexity可以理解为对预测序列不确定性的衡量。 语言模型的Perplexity可以看成是预测后面tokens时的不确定程度。 考虑一个具有三位entropy的语言模型,其中每一位都编码两个等概率的可能结果。 这意味着在预测下一个token时,该语言模型必须在 2^3 = 8 个可能的选项中进行选择。 因此,我们可以认为该语言模型的Perplexity为 8。
通过上文描述,各位应该已经对这三个指标有所了解。然而在实际应用中,使用这三个指标依然会存在一些问题:
- 首先,拥有多个指标实际上会使比较语言模型变得更加困难,尤其是当语言模型在特定下游任务上的表现相对没那么可靠时。
- 其次,容易让人困惑的一点是语言模型通常旨在最小化perplexity,但是由于我们无法获得0 perplexity,我们如何确定perplexity的下限?如果我们不知道最优值,我们怎么知道我们的语言模型有多好?
- 此外,与准确度等指标不同,无论两个模型是如何训练的,在同一测试集上 90% 的准确度肯定优于 60% 的准确度。但我们并不能直接比较perplexity,除非我们知道文本是如何预处理的、词汇量大小、上下文长度等。例如,虽然字符级别的语言模型的perplexity可能比单词级别的另一个模型的perplexity小得多,但这并不意味着字符级语言模型比词级语言模型好。
因此,如何正确地比较不同任务,不同模型的performance是需要我们着重去考虑的。
希望读完这篇文章之后,它能帮助你理解Language Modeling三大评估标准背后的思想和逻辑。虽然它们只是evaluation的一些方法,但我们的知识是由少到多积累的,每一个这样关键的知识点都能帮你扫清未来面试或做实验时的障碍,让你的研究之路一帆风顺!
你的功力又增强了!:-D
如果你觉得本文对你有所启发,欢迎左下角点赞,你们的分享与支持是我不断输出的动力(full-time Ph.D.,搬砖不易!)。我会不定期update一些新的思考与前沿技术,我update的内容一定也是对我自己的research有所启发的。若你想跟我一起进步,可以关注一下本账号,以方便读到之后的文章。
Peace
推荐阅读:
硅谷谷主:一文掌握Byte Pair Encoding(BPE) — NLP最重要的编码方式之一
硅谷谷主:一文理解强化学习中policy-gradient 和Q-learning的区别
你真的理解transformer了吗(一)- review and rethink
为什么训练的时候warm up这么重要?一文理解warm up原理
作者:硅谷谷主
参考内容:
