物体检测之Faster R-CNN

Fast-RCNN [1]虽然实现了端到端的训练,而且也通过共享卷积的形式大幅提升了R-CNN的计算速度,但是其仍难以做到实时。其中一个最大的性能瓶颈便是候选区域的计算。在之前的物体检测系统中,Selective Search是最常用的候选区域提取方法,它贪心的根据图像的低层特征合并超像素(SuperPixel)。另外一个更快速的版本是EdgeBoxes [4],虽然EdgeBoxes的提取速度达到了0.2秒一张图片,当仍然难以做到实时,而且EdgeBoxes为了速度牺牲了提取效果。Selective Search速度慢的一个重要原因是不同于检测网络使用GPU进行运算,SS使用的是CPU。从工程的角度讲,使用GPU实现SS是一个非常有效的方法,但是其忽视了共享卷积提供的非常有效的图像特征 。
由于卷积网络具有强大的拟合能力,很自然的我们可以想到可以使用卷积网络提取候选区域,由此,便产生了Faster R-CNN最重要的核心思想:RPN (Region Proposal Networks)。通过SPP-net [5]的实验得知,卷积网络可以很好的提取图像语义信息,例如图像的形状,边缘等等。所以,这些特征理论上也应该能够用提取候选区域(这也符合深度学习解决一切图像问题的思想)。在论文中,作者给RPN的定义如下:RPN是一种可以端到端训练的全卷积网络 [6],主要是用来产生候选区域。
RPN是通过一个叫做锚点(anchor)的机制实现的。锚点是通过在conv5上进行 3\times3 ,步长为1的滑窗,在输入图像上取得的,在取锚点时,同一个中心点取了3个尺度,3个比例共9个锚点。Faster R-CNN的候选区域便是用RPN网络标注了标签的锚点。RPN的思想类似于Attention机制,Attention中where to look要看的地方便是锚点。
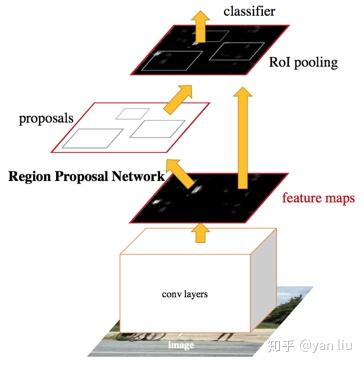
RPN产生候选区域,Fast R-CNN使用RPN产生的候选区域进行物体检测,且二者共享卷积网络,这便是Faster R-CNN的框架(图1)。由此可见,RPN和Fast R-CNN是相辅相成的。在论文中,作者使用了Alternative Training的方法训练该网络。
算法详解
Faster R-CNN分成两个部分:
- 使用RPN产生候选区域
- 使用这些候选区域的Fast R-CNN
Fast R-CNN已经在上一篇文章分析过,下面我们结合论文和源码仔细分析Faster R-CNN。
1. Region Proposal Networks
首先我们要确定RPN网络输入与输出,RPN网络输入是任意尺寸的图像,输出是候选区域和它们的评分(可以理解为置信度),当然,由于RPN是一个多任务的监督学习,所以我们也需要图片的Ground Truth。谈到RPN的多任务,RPN的任务有两个,任务一是用来判断当前锚点是前景的概率和是背景的概率,所以是两个二分类问题;任务二用来预测锚点中前景区域的坐标 (x,y,w,h) ,所以是一个回归任务,该回归任务预测四个值。RPN对每一组不同尺度的锚点区域,都会单独的训练一组多损失任务,且这些任务参数不共享。这么做的原因我们会在锚点的生成部分进行讲解。所以,假设有 k 个锚点,RPN网络是一个有 6\times k 个输出的模型。反应到下面源码中
layer {
name: "rpn_cls_score"
type: "Convolution"
bottom: "rpn/output"
top: "rpn_cls_score"
param { lr_mult: 1.0 }
param { lr_mult: 2.0 }
convolution_param {
num_output: 18 # 2(bg/fg) * 9(anchors)
kernel_size: 1 pad: 0 stride: 1
weight_filler { type: "gaussian" std: 0.01 }
bias_filler { type: "constant" value: 0 }
}
}
layer {
name: "rpn_bbox_pred"
type: "Convolution"
bottom: "rpn/output"
top: "rpn_bbox_pred"
param { lr_mult: 1.0 }
param { lr_mult: 2.0 }
convolution_param {
num_output: 36 # 4 * 9(anchors)
kernel_size: 1 pad: 0 stride: 1
weight_filler { type: "gaussian" std: 0.01 }
bias_filler { type: "constant" value: 0 }
}
}1.1 数据准备
理论上输入的图像是任意尺寸,但是在Faster R-CNN中,我们将图像的最短边resize到了600,且最长边不超过1000,在resize的过程中,保持输入图像的长宽比不变。最短边固定为600是为了防止经过若干次降采样后特征图的尺寸过小,最大边不超过1000是为了防止图像太大影响检测速度。
1.2 多任务损失
1.2.1 分类任务 L_{cls}
在分类任务中,如果锚点和Ground Truth的IoU大于 0.7 ,该锚点为正样本;如果IoU小于 0.3 ,则该样本为负样本。可见,正负样本并不是互斥的,因为还存在一些介于正负样本直接的锚点(IoU在 0.3 到 0.7 之间),所以并不能简单的化成一个二分类任务。设 p_i 是预测的类别,如果锚点为正, p_i^*=0 ,如果锚点为负 p_i^*=1 ,其它介于正负锚点之间的样本不参与模型训练。 L_{cls}(p_i, p_i^*) 是log损失。
1.2.2 回归任务 L_{reg}
RPN的另外一个任务是预测四个值的回归任务,即预测 (x,y,w,h) ,假设锚点表示为 (x_a, y_a, w_a, h_a) ,ground truth是 (x^*, y^*, w^*,h^*) , 将这些坐标信息参数化为
t_x = (x-x_a)/w_a, \quad t_y = (y-y_a)/h_a
t_w = log(w/w_a), \quad t_h = (h/h_a)
t_x^* = (x^*-x_a)/w_a, \quad t_y^* = (y^*-y_a)/h_a
t_w^* = log(w^/w_a), \quad t_h^* = (h^*/h_a)
损失函数 L_{reg}(t_i, t_i^*) 使用的是Fast R-CNN中定义的smooth L1 loss。上面的参数化可以理解为预测ground truth和锚点位置的相对尺寸和位置。
1.2.3 损失函数
多任务损失的损失函数表示为 (i表示minibatch中第i个样本)
L({p_i},{t_i})=\frac{1}{N_{cls}}\sum_{i}L_{cls}(p_i,p_i^*)+\lambda\frac{1}{N_{reg}}\sum_{i}p_i^*L_{reg}(t_i,t_i^*) \tag{1}
为了平衡两个任务, \lambda 的值设为了10。同Fast R-CNN一样,为了达到更好的训练结果, \lambda 需要根据损失函数的下降情况以及模型在验证集上面的表现针对性的调整。
1.3 锚点生成
如何生成锚点是Faster R-CNN最重要也是最难理解的部分,网上很多博客的理解并不正确或者讲解的不够透彻,下面我们来开始详细分析这一部分。
首先,RPN的滑窗(步长是1)是在特征层即conv5层进行的,然后通过 3\times 3\times 256 (ZF-Net是256,VGG-16是512)的卷积核将该窗口内容映射为特征向量(下图中的256-d即为特征向量)。
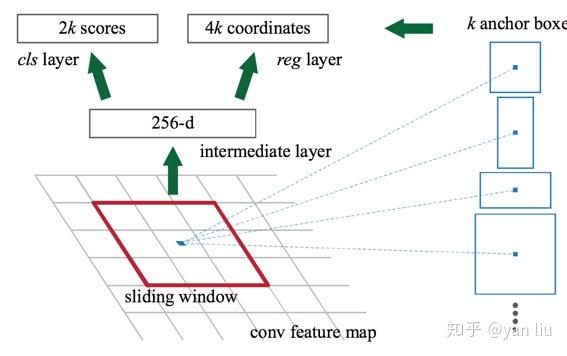

根据SPP-net所介绍的感受野的知识,特征图上的一点对应的感受野是输入图像的一个区域,该区域可以根据卷积网络结构反向递推得出。递推公式为:
rfsize = (out-1) \times stride + ksize\tag{2}
根据这个递推公式我们可以计算出VGG-16的感受野的大小是228(论文中有这个数字),在VGG的卷积层中
rfsize = (out-1) \times 1 + 3 = out + 2 \tag{3}
在pooling 层中
rfsize = (out-1) \times 2 + 2 = out \times 2 \tag{4}
递推过程总结如下图
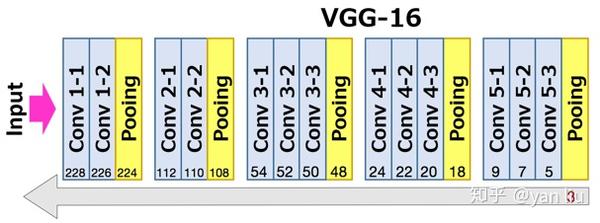

由于RPN的特征向量是从conv5经过卷积核为3的卷积获得,所以应该从3开始向前推。
根据卷积的位移不变性,将conv5映射到输入图像感受野的中心点只需要乘以降采样尺度即可,由于VGG使用的都是same卷积,降采样尺度等于所有pooling的步长的积,即:
\_feat\_stride = \prod_{i} pool_{stride} = 2\times2\times2\times2 = 16\tag{5}
相对位移便是特征图上的位移除以降采样尺度
shift_x = np.arange(0, width) * self._feat_stride # _feat_stride = 16
shift_y = np.arange(0, height) * self._feat_stride所以,在特征图的步长为1的滑窗也可以理解为在输入图像上步长为_feat_stride的滑窗。例如一个最短边resize到600的 4:3 的输入图像,经过4次降采样后,特征图的大小为 W\times H = (600/16) \times (800/16) = 3850 \approx 2k 。步长为1的滑窗后,得到了 W\times H\times k 个锚点,这便是论文中锚点个数的由来,由于部分锚点边界超过了图像,这部分锚点会被忽略,所以并不是所有锚点都参与抽样。
根据感受野的中心,每个中心取9个锚点,这9个锚点有3个尺度 128^2 , 256^2 和 512^2 ,每个尺度有3个比例 1:1 , 1:2 , 2:1 。代码中锚点的坐标为:
[[ -84. -40. 99. 55.]
[-176. -88. 191. 103.]
[-360. -184. 375. 199.]
[ -56. -56. 71. 71.]
[-120. -120. 135. 135.]
[-248. -248. 263. 263.]
[ -36. -80. 51. 95.]
[ -80. -168. 95. 183.]
[-168. -344. 183. 359.]]可视化该锚点,得到下图,黄色部分代表中心点的感受野。
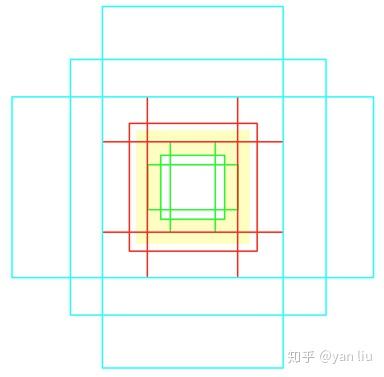
作者在论文中说这种锚点并没有经过精心设计,我认为,这批锚点表现好不是没有原因的,三中锚点分别包括被感受野包围,和感受野类似以及将感受野覆盖三种情况,可见这样设计锚点覆盖的情况还是非常全面的。
由于每个中心对应一个256维的特征向量,而1个中心对应了9个不同的锚点,进而产生不同的标签。这似乎是一个1 vs n的映射,而这种方程是无解的。实际上,作者根据9种不同尺寸和比例的锚点,独立的训练9个不同的回归模型,这些模型的参数是不共享的。这就是RPN的模型为什么有 6\times k 个输出的原因,如图5。


一个重要的问题是同一个中心点产生9个不同尺度的锚点,每个锚点对应一个多任务的分支,那么怎么做到不同尺寸的锚点训练不同的分支的呢?在损失函数的计算中,所有锚点的特征向量均参与计算概率和位移, 只是根据采样的样本来调整一部分分支的权值。
def train_model(self, sess, max_iters):
"""Network training loop."""
data_layer = get_data_layer(self.roidb, self.imdb.num_classes)
# RPN
# classification loss
rpn_cls_score = tf.reshape(self.net.get_output('rpn_cls_score_reshape'),[-1,2])
rpn_label = tf.reshape(self.net.get_output('rpn-data')[0],[-1])
# 提取采样的样本
rpn_cls_score = tf.reshape(tf.gather(rpn_cls_score,tf.where(tf.not_equal(rpn_label,-1))),[-1,2])
rpn_label = tf.reshape(tf.gather(rpn_label,tf.where(tf.not_equal(rpn_label,-1))),[-1])
rpn_cross_entropy = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=rpn_cls_score, labels=rpn_label))能这样做的原因是因为 1\times 1 卷积替代了全连接,这种只有卷积的网络结构叫做全卷积(PS: 先挖一坑)。
1.4 RPN的训练
RPN使用的是"Image-centric"的采样方法,即每次采样少量的图片,然后从图片中随机采样正负锚点样本。具体的,RPN每次随机采样一张图片,然后再每张图片中采样256个锚点,并尽量保证正负样本的比例是1:1。由于负样本的数量基本是上是超过128的,所以当正样本数量不够时,使用负样本补充。
一些超参数设置如下,使用Image-Net的结果初始化网络,前6k代,学习率是0.001,后20k代,学习率0.0001。遗忘因子momentum是0.9,权值衰减系数是0.0006。
2. RPN和Fast R-CNN的训练
由于RPN使用Fast R-CNN的网络模型可以更好的提取候选区域,而Fast R-CNN可以使用RPN的产生的候选区域进行物体检测,两者相辅相成,作者尝试了多种模型训练策略,并最终采用了Alternating Training.
Alternating Training 可以分成4个步骤
- 使用无监督学习即Imagenet的训练结果初始化网络训练RPN;
- 使用RPN产生的候选区域训练Fast R-CNN,Fast R-CNN和RPN使用的是两个独立的网络,也是由Image-Net任务进行初始化;
- 使用Fast R-CNN的网络初始化RPN,但是共享的卷积层固定,只调整RPN独有的网络;
- 固定共享的卷积部分,训练Fast R-CNN。
第2条中我们讲到了使用RPN产生候选区域,下面介绍这一过程。在第一部分我们指出RPN的输出是锚点的正负评分以及预测坐标,在计算候选区域时
- 所有的在图像内部的锚点均输入训练好的网络模型,得到样本评分和预测坐标;
- 使用NMS根据评分过滤锚点,NMS的IoU阈值固定为0.7,之后产生的便是候选区域。
在作者开源的代码中,作者使用的是近似联合训练(Approximate joint training),即将RPN和Fast R-CNN的损失函数简单的加在一起,作为一个多任务的损失函数进行学习。作者也指出,这种方法忽略了Fast R-CNN将RPN的输出作为其输入的这一事实。实际上,Faster R-CNN的RPN和Fast R-CNN并不是一个并行的多任务的关系,而是一个串行级联的关系,图6说明了并行多任务和串行级联的区别,在何凯明的另外一篇论文中专门介绍了该如何处理这种多任务的问题 (PS:又挖一坑)。


3. Faster R-CNN的检测
和之前讲到的一样,使用RPN产生完候选区域后,剩下的便和Fast R-CNN一样了。
参考文献
[1] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” in CVPR, 2014
[2] R. Girshick, “Fast R-CNN,” in IEEE International Conference on Computer Vision (ICCV), 2015.
[3] J. R. Uijlings, K. E. van de Sande, T. Gevers, and A. W. Smeulders, “Selective search for object recognition,” International Journal of Computer Vision (IJCV), 2013.
[4] C. L. Zitnick and P. Dollar, “Edge boxes: Locating object ´ proposals from edges,” in European Conference on Computer Vision (ECCV), 2014.
[5] K. He, X. Zhang, S. Ren, and J. Sun, “Spatial pyramid pooling in deep convolutional networks for visual recognition,” in European Conference on Computer Vision (ECCV), 2014.
[6] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015.
[7] J. Dai, K. He, and J. Sun, “Instance-aware semantic segmentation via multi-task network cascades,” arXiv:1512.04412, 2015.
