Box-Aware for SOT __点云数据下的目标追踪


论文名称:
Box-Aware Feature Enhancement for Single Object Tracking on Point Clouds
作者信息:


代码开源:
代码解析:
2021年的ICCV文章
该文章和P2B PointNet++ VoteNet联系颇深。可以翻阅我的论文笔记,有相应笔记。
1、介绍
这篇文章出发点非常明确,即前面的追踪方法基本只使用了第一帧中GTBox中的点云信息,而忽略了GTbox本身的形状。即:第一帧通常会框出来我们要追踪的目标,这个框框中会有很多的点,前面的方法只把这些点拿去用来追踪了,没有去使用这个框框本身的信息。
这样一来就会导致很多问题,比如遇到相似物体的时候,容易产生误判。作者在文中就举了一个长汽车和一个短汽车的例子,如果我们从前面去扫描的话,得到的点云数据会很接近,这样就没法准确的给出Propoals了。如图1所示:
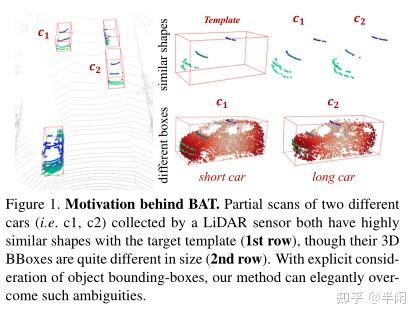
所以作者提出了一个表示方式名为BoxCloud,他可以用于描述点对盒的关系。其实就是用一个9维特征来表示每一个点,每个特征是该点到该框的8个顶点和1个中心的距离,这个后面会详细提到。然后再利用这个BoxCloud将Template area的特征映射到Search area中去。
作者总结本文主要有如下三个贡献:
1、本文首次提出了使用box information用来提升3D中的目标追踪效果。具体来说,作者设计了一种能感知size和part的BoxCloud用于提取box的信息。
2、提出了一种专用的信息融合模块,用于融合点云信息和box的形状信息。
3、在两个benchmarks上取得了良好的效果。
2、Related Work
略
3、Method
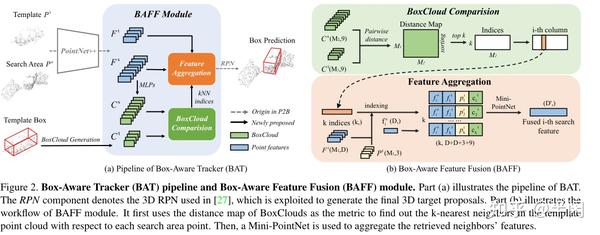
BAT算法的整体框架图如图2所示

3.1 Problem Statement
和其他3D追踪的没啥区别
3.2 Box-Aware Tracker (BAT)
本文所提出追踪器名为BAT,是基于P2B的(P2B可见我以前的阅读笔记)。
P2B:
P2B的流程大概如下:
1、分别将template area 和 search area放进同一backbone进行特征提取
2、逐点为template area和search area的特征进行相关性计算得到相关性矩阵
3、使用PointNet对2中得到的相关性矩阵进行处理,使其获得排列无关性
4、在相关性矩阵上拼接上template area的特征进行特征增强
5、通过增强后的特征生成选票并利用VoteNet的投票机制生成target proposals
每个proposals是一个5D的向量,维度中包括了 目标的中心坐标(3D),旋转角度信息(1D),和对该proposals的打分(置信度)(1D)。得分最高的propoals就被认为是最终的目标所在地。
BAT:
该文章聚焦于P2B的第一个部分,也就是如何更好的进行特征增强。
本文提出的BAT算法结构如图2(a)所示,也就是图3的这个部分
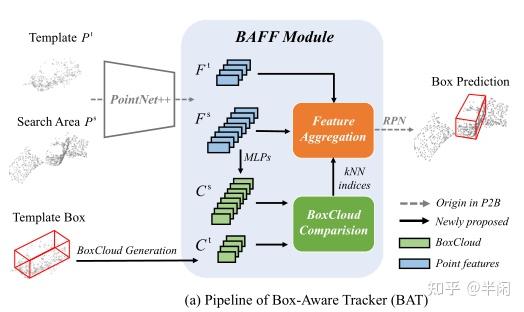

BAT的大概流程如下:
1、首先使用PointNet++分别对模板区域的点云 P^{t} 和搜索区域的点云 P^{s} 进行特征提取。得到F^{t} 和F^{s}。
2、通过 F^{t} 中的点云数据和box计算出BoxCloud,记为 C^{t} 。然后使用1个multi-layer perceptron(MLP)预测 F^{s} 中每个点的BoxCloud,记为。
3、将C^{t}和C^{s}放入到BoxCloud比较器中进行相似度计算,并将相似度最高的k的点取出,用于对F^{s}的特征加强。
4、得到加强后的特征 \bar{F_{s}} ,并从\bar{F_{s}}中生成最终的target proposals.
3.3. BoxCloud Representation
这一部分讲的是这个BoxCloud到底是怎么表示,怎么计算的。
BoxCloud是一种点对盒的关系表示。假设目标点云为 P ,他的BBox为 B 。对于在 P 中的任意一个点 p_{i} ,计算出其在空间中到BBox每个顶点(8个)和中心(1个)的距离。然后将这个9个距离按照预先设定好的排序方式,生成一个9D的向量 c_{i} 。如图4所示
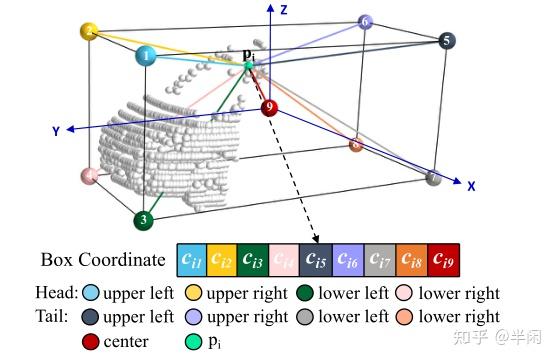

用公式语言来说就是:
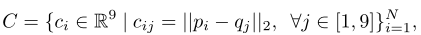

用BoxCloud进行数据表示时,会有如下的特点:
1、Size-Awareness 也就是可以从BoxCloud中得到Box的形状信息。
2、Part-Awareness 可 i 以获知每个点在Box中的相对位置
这些都是曾经不使用Box信息时,拿不到的东西。
3.4 Box-Aware Feature Fusion
这个模块简称为BAFF,其作用是融合搜索区域和模板的信息进行特征加强。原文如下:
The goal of the Box-Aware Feature Fusion (BAFF) module is to generate an enhanced target-specific search area by augmenting the search area with the template, which enables us to locate the target in the search area using a 3D
RPN.
BAFF模块由两部分组成,为 BoxCloud Comparison 和 Feature Aggregation
BoxCloud Comparison:
首先使用1个multi-layer perceptron(MLP)预测 F^{s} 中每个点的BoxCloud,记为C^{s}(也就是前面BAT流程处的第2步)。MLP的输入是F^{s}中的每个点 f_{i}^{s} ,输出的是1个9D的box坐标 c_{i}^{s} 。该过程使用的损失函数为smooth-L1函数,如下所示:
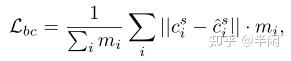
其中 m_{i} 表示第 i 个点是否在目标的Box内,如果是,等于1否则为0
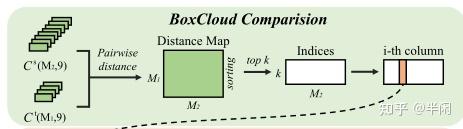
随后计算 模板区域的boxcloud C^{t} 与搜索区域的boxcloud C^{s} 之间的相似度。这里的相似度使用L2距离表示。并选出相似度最高的k个点及其对应的特征。
参考代码可见:
top_k_nearest_idx_b = torch.argsort(dist_matrix, dim=1)[:, :self.k, :] # B, K, N
top_k_nearest_idx_b = top_k_nearest_idx_b.transpose(1, 2).contiguous().int() # B, N, K对应于图5所示:

Feature Aggregation
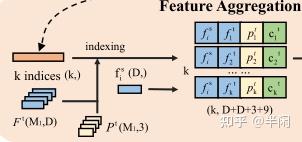
这个模块致力于将前面选出的K个得分最高的特征融入到F^{s}中去。对于F^{s}中的每个点f_{i}^{s},我们首先在F^{t}对应得分最高的f_{j}^{t}。然后将f_{j}^{t}(维度为D )、f_{i}^{s}(维度为D)、对应模板seed的坐标 p_{j}^{t} (维度为3)以及对应模块seed的boxcloud坐标c_{j}^{t}(维度为9)拼接在一起,构成了维度为(2D+3+9)的新特征。参考代码如下:
template_xyz_feature_box = torch.cat([template_xyz.transpose(1, 2).contiguous(),
template_bc.transpose(1, 2).contiguous(),
template_feature], dim=1)
# search_xyz_feature = torch.cat([search_xyz.transpose(1, 2).contiguous(), search_feature], dim=1)
top_k_nearest_idx_b = torch.argsort(dist_matrix, dim=1)[:, :self.k, :] # B, K, N
top_k_nearest_idx_b = top_k_nearest_idx_b.transpose(1, 2).contiguous().int() # B, N, K
correspondences_b = pointnet2_utils.grouping_operation(template_xyz_feature_box,
top_k_nearest_idx_b) # B,3+9+D,N,K对应如图6所示:
其实这一块相对于P2B网络而言,只是拼接的特征上多了一个boxcloud数据。
之后就简简单单使用了PointNet常用了那一套进行了特征处理,公式如下:
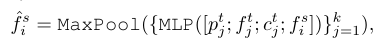
参考代码如下:
fusion_feature = self.mlp(correspondences_b) # B,D,N,K
fusion_feature, _ = torch.max(fusion_feature, dim=-1) # B,D,N,1
fusion_feature = self.fea_layer(fusion_feature.squeeze(dim=-1)) # B,D,N对应如图7所示:
拿到增强特征后,使用与P2B类似的手段,生成最终的proposals,参考代码如下:
def forward(self, xyz, feature):
"""
:param xyz: B,N,3
:param feature: B,f,N
:return: B,N,4+1 (xyz,theta,targetnessscore)
"""
estimation_cla = self.FC_layer_cla(feature).squeeze(1)
score = estimation_cla.sigmoid()
xyz_feature = torch.cat((xyz.transpose(1, 2).contiguous(), feature), dim=1)
offset = self.vote_layer(xyz_feature)
vote = xyz_feature + offset
vote_xyz = vote[:, 0:3, :].transpose(1, 2).contiguous()
vote_feature = vote[:, 3:, :]
vote_feature = torch.cat((score.unsqueeze(1), vote_feature), dim=1)
center_xyzs, proposal_features = self.vote_aggregation(vote_xyz, vote_feature, self.num_proposal)
proposal_offsets = self.FC_proposal(proposal_features)
estimation_boxes = torch.cat(
(proposal_offsets[:, 0:3, :] + center_xyzs.transpose(1, 2).contiguous(), proposal_offsets[:, 3:5, :]),
dim=1)
estimation_boxes = estimation_boxes.transpose(1, 2).contiguous()
return estimation_boxes, estimation_cla, vote_xyz, center_xyzs大概就是P2B中的这部分,如图8所示
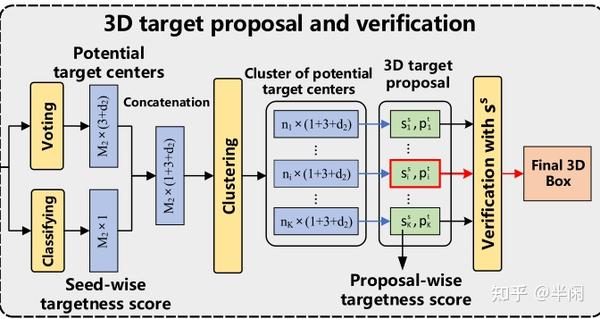

毕竟文章开头也说了,他们着力于改善特征增强部分,所以如何处理改善后的增强特征,并没有与P2B有区别。
该网络的损失函数又P2B的损失函数加上本文提出的 L_{bc} 组成,如下所示:
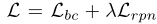
P2B部分的损失函数如下,也就是这里的 L_{rpn} :
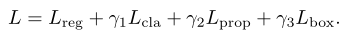
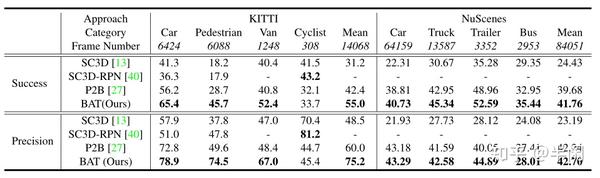
4.实验

5.总结
作者:本文充分利用了盒的形状信息来增强激光雷达点云信息的上的目标追踪。对P2B结构进行扩展,构建了BAT结构,并且取得了良好的效果,特别是在稀疏目标跟踪方面。
笔者:说实话整体文章相对于P2B的改动是不大的,作者提到了只是进行了微小的修改。但是本文的思路我觉得很有意思,使用上了以前一直被大家忽略的盒形状信息。在2D图像中,由于畸变,目标会在图像中发生尺度和形状的改变,所以从Faster RCNN开始,大家都倾向于对尺度进行一定程度的预测。但是在三维空间中,咱们的尺度信息是不会改变的,所以可以放心大胆的使用最开始给出的目标盒形状信息以改善跟踪效果。直觉上的问题:1、每个seed需要计算到空间中9个点的欧氏距离,会不会算力消耗比较大?2、文章提出了在稀疏目标跟踪时有很好的效果,我很好奇这是为什么,是因为提供了盒信息?让每个seed可以聚合更多的信息,所以在面临稀疏问题时有很好的鲁棒性?
2021.11.10 20:03
兴庆
上课还是很费时间啊,昨天都没有敲完
今晚双11,抢个方向盘来开车玩(=-=)
