论文笔记:arXiv'20 GraphFL: A Federated Learning Framework for Semi-Supervised Node Classification

前言
本文研究内容为基于联邦学习的 Graph-based semi-supervised node classi cation (GraphSSC),现有的方法存在以下限制:
- 跨客户端的数据分布特点为 no-IID 时表现不佳(FL 常见问题,尤其是 Graph data);
- 不能处理具有新标签域的数据(可扩展性不足);
- 不能利用无标签的数据(训练过程存在限制);
基于此,本文提出了 GraphFL,用于图上的半监督节点分类。该框架以元学习方法为驱动。具体来说,本文提出了两种 GraphFL 方法,分别解决图数据中的 no-IID 问题和应对新标签域的任务。此外还设计了一种自监督训练的方法来利用未标记的图数据。
如果大家对大图数据上高效可扩展的 GNN 和基于图的隐私计算感兴趣,欢迎关注我的 Github,之后会不断更新相关的论文和代码的学习笔记。
1. Motivation
GraphFL 框架受最近的元学习方法启发,称为 model-agnostic meta-learning (MAML),MAML 对新任务具有快速适应能力。给定一组从基础分布中抽取的任务,MAML 学习一个与任务无关的初始化,在几步梯度更新后在所有任务上都表现良好。MAML 适合与 FL 进行结合。可以把每个任务看作是一个客户端,而与任务无关的初始化是在服务器上学习的全局模型。基于此,本文提出两种 GraphFL 方法来解决数据分布 no-IID 问题和可扩展性问题。为了解决数据分布 no-IID 问题,在 MAML 中跨任务的数据分布不需要满足 IID 假设,因此将MAML 与 FL 进行结合。
- 解决数据分布 no-IID 问题:首先遵循 MAML 的训练方法在服务器上学习一个全局模型,从而缓解 no-IID 分布引起的问题。然后利用现有的 FL 方法进一步更新全局模型,使其能够在测试节点上实现良好的泛化。
- 解决可扩展性问题:提出与现有 FL 方法不同的新目标函数。基于此在服务器上为所有本地客户端学习一个共享全局模型,全局模型可以快速适应标签域与训练节点不同的测试节点。
- 解决无标签节点利用问题:提出一个自监督训练方法,首先使用 GraphSSC 方法利用客户端的标签训练一个本地模型。然后使用每个训练好的局部模型来预测客户的未标记节点,并选择预测结果最准确的未标记节点。这些被选中的节点以及它们的预测标签被用作额外的标签节点来训练 GraphSSC 方法。
本文实现了 GraphSSC 与 GCN 和 SGC 的融合。
2. GraphFL
2.1 Problem definition
假设有一个共有 I 个客户端的集合 \mathbb{C} = \{C^{(1)}.C^{(2)},\dots,C^{(I)}\} ,其中客户端 C^{(i)} 持有本地私有图数据 G^{(i)} = (\mathbb{V}^{(i)},\mathbb{E}^{(i)}) 包含图节点集合和边集合。每一个节点 v^{(i)}\in\mathbb{V}^{(i)} 具有特征向量 x_{v^{(i)}} 和标签 y_{v^{(i)}} 。其中标签集为 \mathbb{K} = \{1,2,\dots,K\} 。同时在每个本地客户端有一些有标签节点 \mathbb{L}^{(i)}\subset\mathbb{V}^{(i)} 。本地模型表示为 f_{\theta^{(i)}} 。
基于有标签集合 \mathbb{L}^{(i)} 和图 G^{(i)} ,考虑一个中心服务器 \mathbb{S} ,可以通过聚合多个本地模型的参数 \{\theta^{(i)}\}_{i=1}^I 来学习全局模型参数 \theta 。同时假设有一个测试节点集合 \mathbb{T} 与训练节点标签的标签域不同,基于此本文 GraphSSC 有如下定义:


GraphFL 的目标是设计一个基于联邦学习的 GraphSSC 方法,实现以下三个目标:
- 解决图数据中的 no-IID问题;
- 泛化到具有新标签域的测试节点;
- 利用本地客户端中的无标签节点。
2.2 Model-agnostic meta learning (MAML)
基于一个基本任务分布 \mathcal{T} 给出一个训练任务集合 \{T_i\} ,MAML 相比于学习一个在所有任务上都表现良好的模型,更倾向于学习一个任务无关的初始化参数 \theta ,并基于此初始化,经过几次梯度更新后可以在所有任务上都有较好的表现。具体来说每一个任务 T_i 划分其带标签的训练集 \mathbb{L}^{(i)} 为 support set \mathbb{L}_S^{(i)} 和 query set \mathbb{L}_Q^{(i)} ,MAML 的两步优化:内部优化(inner-optimization)和元优化(meta-optimization)。
在 inner-optimization 中,对于每一个任务 T_i ,MAML 基于 support set \mathbb{L}_S^{(i)} 训练一个模型 f_\theta ,并输出一个任务相关的模型参数 \theta^{(i)} 。基于此 MAML 将 \theta^{(i)} 作为初始化并验证模型 f_{\theta^{(i)}} 在相关 query set \mathbb{L}_Q^{(i)} 上得到的任务相关损失。
在 meta-optimization 中,MAML 通过对所有任务的 query set 的总损失进行最小化,以学习与任务无关的初始化。形式上,MAML的目标函数如下:
\min_{\theta}\mathcal{L}(\theta) = \sum_{T_i\sim\mathcal{T}}\mathcal{L}_{\mathbb{L}_Q^{(i)}}(\theta^{(i)}) = \sum_{T_i\sim\mathcal{T}}\mathcal{L}_{\mathbb{L}_Q^{(i)}}(\theta-\alpha\cdot\nabla\mathcal{L}_{\mathbb{L}_S^{(i)}}(\theta))\tag{1}
其中,为简便起见,在 inner-optimization 中使用一步梯度下降法; \alpha 是学习率;support set 和 query set 的任务特定损失分别表示为:
\mathcal{L}_{\mathbb{L}_S^{(i)}}(\theta) = \frac{1}{{\mathbb{L}_S^{(i)}}}\sum_{(x,y)\in\mathbb{L}_S^{(i)}}\ell(f_\theta(x),y)\tag{2}
\mathcal{L}_{\mathbb{L}_Q^{(i)}}(\theta^{(i)}) = \frac{1}{{\mathbb{L}_Q^{(i)}}}\sum_{(x,y)\in\mathbb{L}_Q^{(i)}}\ell(f_{\theta^{(i)}}(x),y)\tag{3}
式(1)可以通过元学习率为 \beta 的梯度下降法来计算:
\theta\leftarrow\theta-\beta\cdot\nabla\mathcal{L}(\theta)\tag{4}
MAML 从任务分布 \mathcal{T} 中抽出一批任务进行训练。当一个新任务到来时,MAML 使用学习到的与任务无关的初始化作为初始模型,并通过几步梯度下降对新任务中的损失进行更新。然后,更新后的模型被用来进行预测。
如果将每个本地客户端看成是任务,把与任务无关的初始化当作在服务器上学习的全局模型,MAML 自然符合 FL 的要求。受此启发,本文将 MAML 纳入 FL,并提出 GraphFL 框架来研究基于图的半监督节点分类问题。
2.3 GraphFL Framework
2.3.1 GraphFL for federated GraphSSC with non-IID graph data


GraphFL由两个阶段组成:
- 通过 MAML 在服务器上学习全局模型,从而可以缓解 no-IID 图数据引起的问题;
- 利用现有的 FL 方法进一步更新全局模型,使其达到良好的泛化能力。
对于每一个本地客户端 C^{(i)} 划分其带标签的训练集 \mathbb{L}^{(i)} 为 support set \mathbb{L}_S^{(i)} 和 query set \mathbb{L}_Q^{(i)},假设在第 t 个 round,服务器端 \mathbb{S} 拥有全局模型 \theta_t ,并且服务器端 C^{(i)} 持有本地模型 \theta_t^{(i)} ,基于上述假设,分别定义客户端 C^{(i)} 在 support 节点集 \mathbb{L}_S^{(i)} 上的损失为 \mathcal{L}_{\mathbb{L}_S^{(i)}}(\theta_t) = \frac{1}{|{\mathbb{L}_S^{(i)}}|}\sum_{v^{(i)}\in\mathbb{L}_S^{(i)}}\ell(f_{\theta_t}(\mathbf{x}_v^{(i)},G^{(i)}),y_v^{(i)}) ,在 query set 上的损失为 \mathcal{L}_{\mathbb{L}_Q^{(i)}}(\theta_t^{(i)}) = \frac{1}{|{\mathbb{L}_Q^{(i)}}|}\sum_{v^{(i)}\in\mathbb{L}_Q^{(i)}}\ell(f_{\theta_t^{(i)}}(\mathbf{x}_v^{(i)},G^{(i)}),y_v^{(i)}) ,其中 f_{\theta_t},f_{\theta_t^{(i)}} 分别为 GraphSSC 模型基于客户端所持图数据 G^{(i)} 在 support set 和 query set 学习得到的模型权重。在通信回合 t ,服务器端可以学习全局模型权重 \theta_t ,总结如下:
- 中心服务器随机发送全局模型权重 \theta_t 给以概率 \rho 采样的客户端 \mathbb{C}_t ;
- 每一个参与的客户端 C^{(i)}\in\mathbb{C}_t 首先通过最小化 support set \mathbb{L}_S^{(i)} 的损失 ,基于梯度下降法学习本地模型权重 ,一步梯度下降表示为:
\theta_t^{(i)}\leftarrow \theta_t-\alpha\cdot\nabla\mathcal{L}_{\mathbb{L}_S^{(i)}}(\theta_t)\tag{5}
基于此,每个本地客户端 C^{(i)} 在 query set \mathbb{L}_Q^{(i)} 上验证本地模型参数 \theta_t^{(i)} ,得到损失的梯度 \nabla_theta\mathcal{L}_{\mathbb{L}_Q^{(i)}}(\theta_t^{(i)}) ,并将梯度发送回服务器。
3. 服务器端通过收集本地客户端上传的梯度更新全局模型参数 \theta_t 为 \hat{\theta}_t ,以一步梯度下降法为例,可以得到:
\hat{\theta}_t\leftarrow-\beta\nabla_{\theta} \sum_{C^{(i)}\in\mathbb{C}_t}\mathcal{L}_{\mathbb{L}_Q^{(i)}}(\theta_t^{(i)})\tag{6}
按照 MAML 的训练方法,服务器学会了一个全局模型,可以缓解图数据中的 no-IID 问题。之后进一步更新全局模型,使其在所有客户端上都能达到良好的泛化能力。
4. 每一个参与的客户端 C^{(i)}\in\mathbb{C}_t下载全局模型权重 \hat{\theta}_t 通过梯度下降对支持节点的局部模型进行 finetune。以一步梯度下降法为例,可以得到:
\hat{\theta}_t^{(i)}\leftarrow\hat{\theta}_t-\alpha\cdot\nabla\mathcal{L}_{\mathbb{L}_S^{(i)}}(\hat{\theta}_t)\tag{7}
5. 服务器端采用现有的 FL 方法,例如 FedAvg 更新全局模型:
\theta_{t+1}\leftarrow\frac{1}{|\mathbb{C}_t|}\sum_{C^{(i)}\in\mathbb{C}_t}\hat{\theta}_t^{(i)}\tag{8}
最终的全局模型用来预测全新标签域的测试节点 \mathbb{T}
2.3.2 GraphFL for federated GraphSSC with new label domains


本文假设训练节点和测试节点有不同的标签域。可能的解决方案是利用 transfer learning。具体来说,首先在服务器上基于现有的 FL 方法(FedAvg)学习一个全局模型。接下来,采用全局模型作为初始模型,并使用一些具有新标签域的标签节点对模型进行 finetune。然后使用finetuned 模型来预测具有新标签域的测试节点的标签。然而这种基于 transfer learning 的解决方案所取得的性能不佳。
进而提出了一种新的 GraphFL 方法,可以推广到具有新标签域的测试节点。具体来说,作者在 FL 框架中重新表述 MAML,旨在为所有客户在服务器上学习一个共享的全局模型,这样,每个客户在经过几步梯度更新后,可以得到较好的性能。损失函数如下:
\min_{\theta}\mathcal{L}(\theta) = \frac{1}{I}\sum_{i=1}^I\mathcal{L}_i(\theta) = \frac{1}{I}\sum_{i=1}^I\mathcal{L}_{\mathbb{L}_Q^{(i)}}(\theta-\alpha\cdot\nabla\mathcal{L}_{\mathbb{L}_S^{(i)}}(\theta))\tag{9}
其中 \theta 代表我们希望学习到的共享权重。
首先根据指定的客户端损失来更新本地模型,然后通过汇总本地模型来更新全局模型:
- 中心服务器随机发送全局模型权重 \theta_t 给以概率 \rho 采样的客户端 \mathbb{C}_t ;
- 每一个参与的客户端 C^{(i)}\in\mathbb{C}_t 首先通过最小化本地客户端损失 \mathcal{L}_i(\theta_t) ,基于梯度下降法学习本地模型权重 ,一步梯度下降表示为:
\theta_t^{(i)}\leftarrow\theta_t-\beta\cdot\nabla\mathcal{L}_i(\theta_t)\tag{10}
其中 \nabla\mathcal{L}_i(\theta_t) 定义为:
\nabla\mathcal{L}_i(\theta_t) = (\mathbb{I}-\alpha\cdot\nabla^2\mathcal{L}_{\mathbb{L}_S^{(i)}}(\theta_t))\cdot\nabla\mathcal{L}_{\mathbb{L}_{Q}^{(i)}}(\theta_t-\alpha\cdot\nabla\mathcal{L}_{\mathbb{L}_{S}^{(i)}}(\theta_t))\\
上述过程可分解为如下过程,首先客户端 C^{(i)} 得到通过执行基于 support set \mathbb{L}_S^{(i)} 定义的损失的梯度下降得到的中间模型权重参数 \hat{ \theta}_{t}^{(i)} ,一步梯度下降表示为:
\hat{\theta}_t^{(i)}\leftarrow\theta_t - \alpha\cdot\mathcal{L}_{\mathbb{L}_S^{(i)}}( \theta_t)\tag{11}
之后,每一个客户端 C^{(i)} 通过 query set \mathbb{L}_Q^{(i)} 来更新本地模型参数得到 \theta_t^{(i)} :
\theta_t^{(i)}\leftarrow\theta_t-\beta(\mathbb{I}-\alpha\nabla^2\mathcal{L}_{\mathbb{L}_S}(\theta_t)\cdot\nabla\mathcal{L}_{\mathbb{L}_Q^{(i)}}(\hat{\theta}_t^{(i)}))\tag{12}
3. 基于此,服务器端通过最小化所有参与的客户端的损失,基于梯度下降更新全局模型参数 \theta_{t+1} ,可表示为:
\theta_{t+1}\leftarrow\theta_t - \frac{\beta}{|\mathbb{C}_t|}\sum_{C^{(i)}\in\mathbb{C}_t}\nabla\mathcal{L}_i(\theta_t) = \frac{1}{|\mathbb{C}_t|}\sum_{C^{(i)}\in\mathbb{C}_t}\theta_t^{(i)}\tag{13}
最后的汇总更新机制采用 FedAvg。
上述过程使用全局模型作为初始模型,并通过几步梯度下降,使用一些来自新标签域的标记节点更新模型。然后,采用更新的模型来预测来自新标签域的测试节点的标签。
2.3.3 Leveraging unlabeled nodes via self-training
现有的 FL 方法主要用于监督学习,只使用带标签数据。基于此,本文提出了一种自监督训练方法来利用客户端所持隐私图数据中的未标记节点。
给定一个基于图的半监督节点分类方法,首先使用该方法在每个客户端使用少数标记节点来训练一个本地模型。接下来,在每个客户端使用其本地模型来预测未标记的节点,并选择一组预测结果最准确的未标记的节点。然后将所选节点的预测标签视为其伪标签,并将每个客户端的所选节点(以及其伪标签)添加到客户端的训练集中。最后在增强的训练集上训练GraphFL。
3. Experiments

主要对比的两个方法:
- Individual learning (IL):只有客户端,每个客户端采用 GraphSSC 方法,并根据其少数标记的节点来训练一个本地节点分类模型。然后,每个学习到的本地模型被用来对测试节点进行分类,并获得分类的准确性。将最终的分类精度报告为所有客户端的平均精度。
- Federated learning (FL):有一个中心服务器和几个客户端。每个客户端都有几个标记的节点,服务器不能访问这些标记的节点。服务器初始化一个全局模型并将其发送给选定的参与客户端;每个选定的客户端采用 GraphSSC 方法来训练。
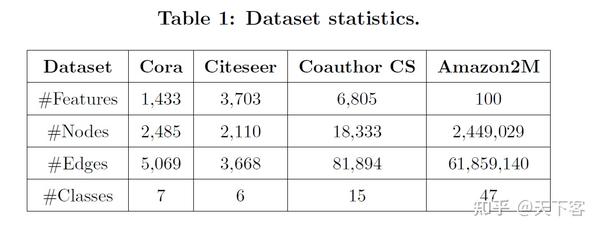
为了对 no-IID 情况进行实验,作者从每个数据集中的每个类别中随机抽取80个节点来形成训练集,并将这些标记的节点平均分配给所有的客户(在本文实验中存在 50 个本地端)。每个客户端总共会被分配到很少的标签节点(9 到 70 个之间),这意味着客户之间的标签节点可能是高度 no-IID。训练集被进一步分成两部分,其中第一部分被用作比较方法中的训练节点或作为 GraphFL 的 support set;第二部分用于比较方法中的超参数调整或作为 GraphFL 中的 query set。此外,考虑到数据集中不同图的大小,作者在 Cora 和 Citeseer 中随机选择1000个节点,在 Coauthor CS 和 Amazon2M 图中随机选择 10000 个节点作为测试集。对训练集和测试集进行5次抽样,并将平均分类准确率作为最终结果。
为了对具有新标签域的测试节点进行分类的实验,作者将每个图数据集中具有 K 类的节点分成两个独立的集合。第一组包含前 K-K_0 的节点,第二组包含其余 K_0 类的节点。考虑到不同的类的数量,在不同的数据集中使用不同的 K_0 。从第一组中对每个客户的节点进行抽样以形成训练集,并从第二组中抽样形成测试集。这样一来,测试集和训练集中的节点具有不同的标签域。具体来说,从第一组中对每个客户随机抽取 K_0 个类,每个类抽取 10 个节点组成训练集。训练集在 GraphFL 中被进一步分成 support set 和 query set;或者在比较 FL的方法中分成训练节点和验证节点。还从第二组中为每个客户端抽出 K_0 个类,每个类抽出与 support set 相同数量的节点进行快速适应/网络调整,并抽出 20 个节点作为测试节点。
超参数设置可详见 Parameter settings
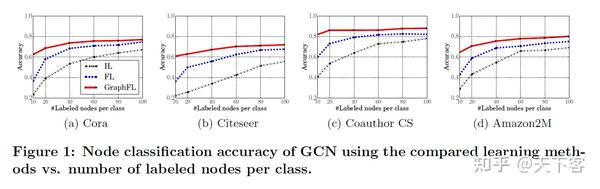
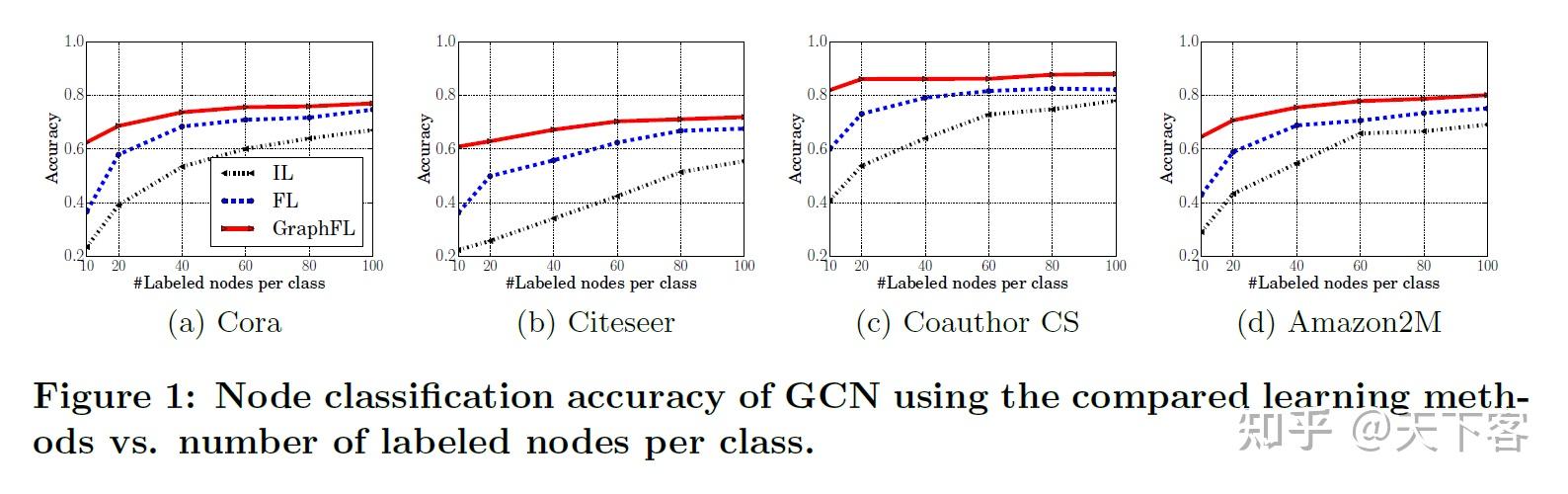
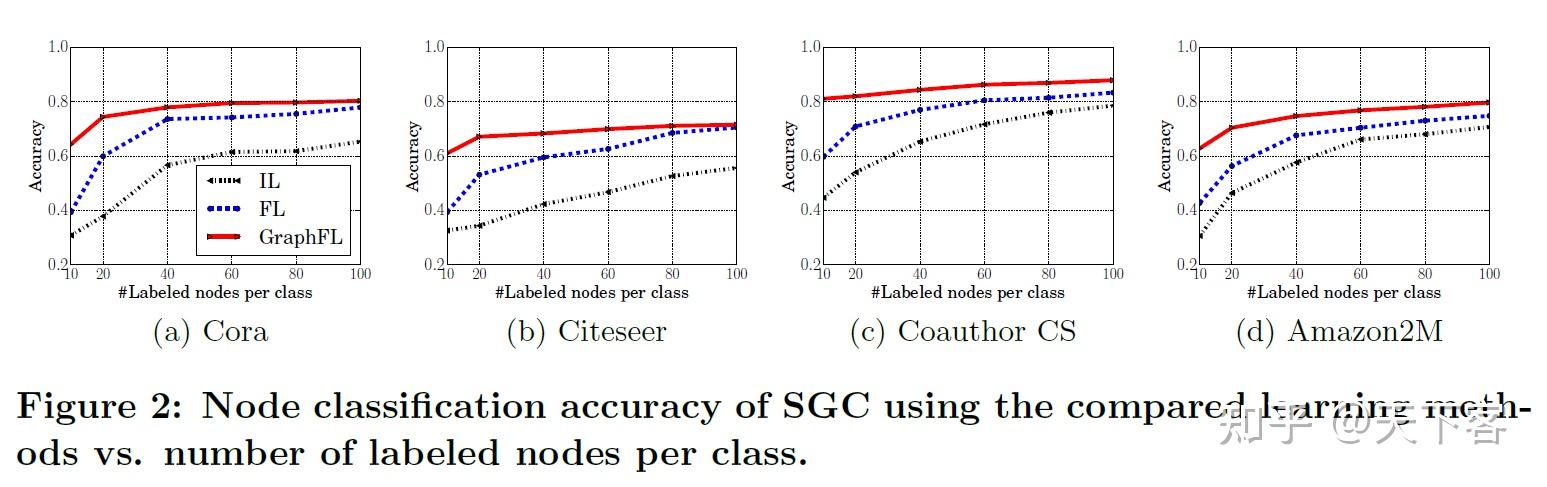
GCN 和 SGC 的节点分类准确率随着每类标记的节点数的变化曲线图:

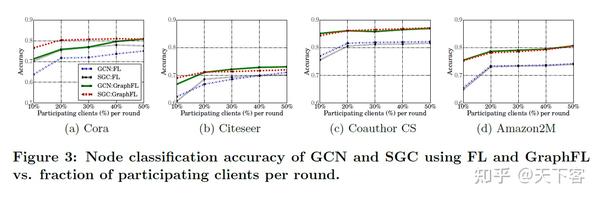
使用 FL 和 GraphFL 的 GCN 和 SGC 的节点分类精度随着参与客户端数量的变化:

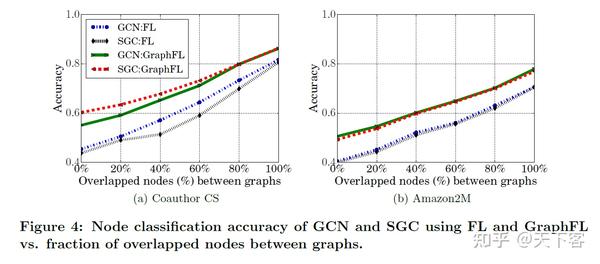
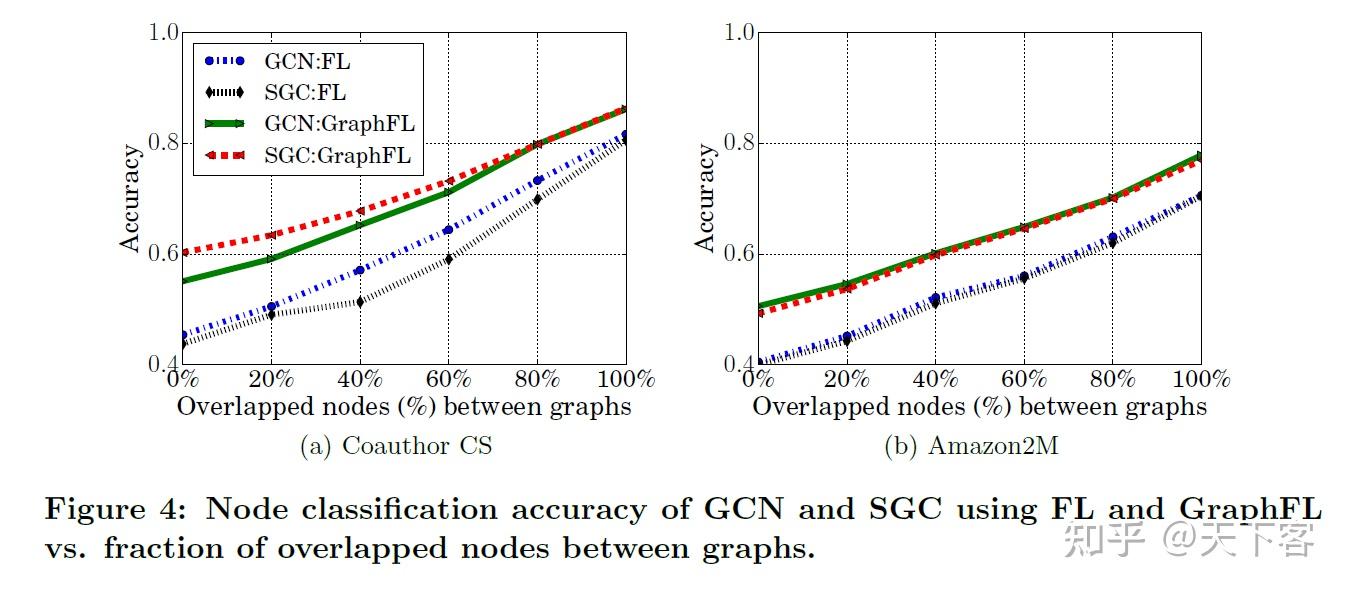
FL 和 GraphFL 的 GCN 和 SGC 的节点分类准确率随客户端之间重叠节点的比例的变化:
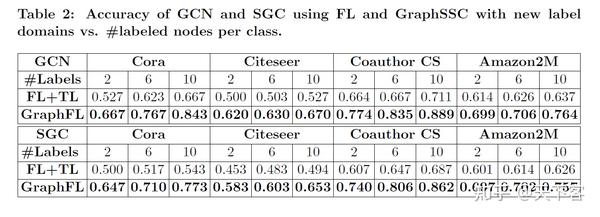
使用 FL 和 GraphFL 的 GCN 和 SGC 的节点分类准确率随每类标记节点的数量变化的结果:

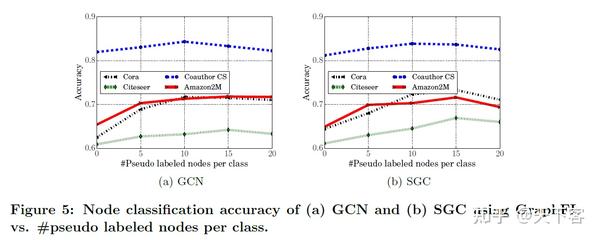
使用 GraphFL 的 GCN 和 SGC 节点分类准确率与通过自监督生成的每个类的伪标记节点数量变化的结果:

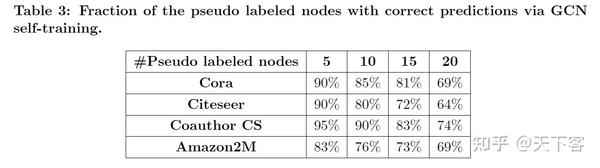
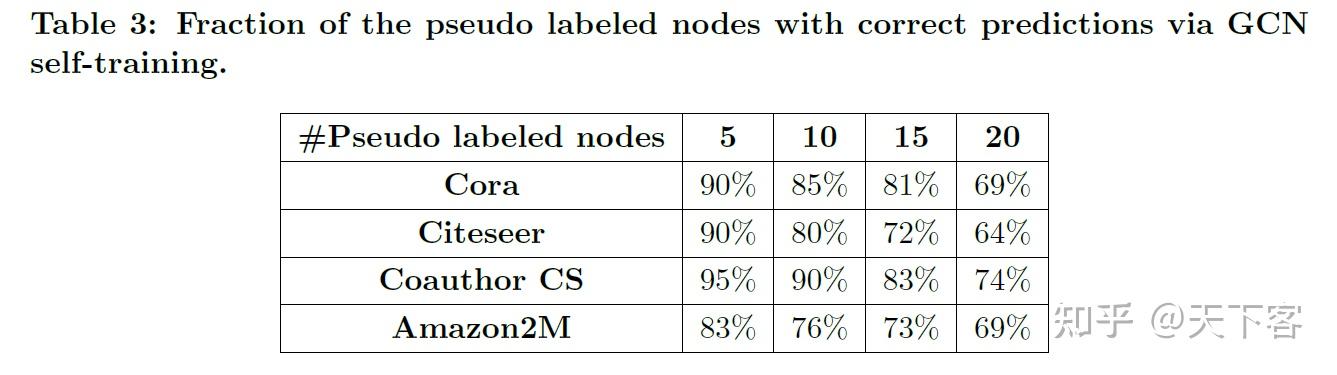
通过 GCN 自训练得到的预测正确的伪标记节点的比例结果: