流程图形化 Node & Flow

--- 流程图 技术选择与抽象设计
技术选型 -- 绘图 DrawGraphics
Web实现图形方式有3种:纯DOM节点、SVG矢量图和Canvas方式。纯DOM节点这种方式是一个基于旧版本浏览器,非主流Web绘图方式,并且性能不高的。当现主流的实现方式有两种:SVG和Canvas,SVG矢量DOM节点绘制技术,由于其类似于DOM的工作方式,所有绘制出的图形都是以DOM节点的形态存在的。当图形不复杂并且单位面积内所需要绘制的节点数少的时候,它的效率很高实现代价最小。而Canvas是最典型的像素绘制技术,也就是位图(Bitmap)绘制技术。它基础就是通过算法去绘制所有的点,当图形复杂且有堆叠时,它的效率会比较高。值得注意的是,当显示区域越大时,也就是分辨率越大时,它所需要的性能资源也就越多。
SVG是基于盒模型的每一次绘制都有可能改变文档节点之间的关系,不太适用绘制真正的矢量场景。典型的例子就是画布的缩放。使用SVG方式缩放画布,只能改变画布的大小(就是改变画布坐标系单位与标准参考坐标系的比率)。虽然,SVG节点本身不会失真(因为,SVG节点自身是个矢量图)。但SVG内的节点图标,或者其它非矢量元素都会随着自己的参考坐标系变化而失真。即使所有的节点都用矢量图形。也会有一个更严重的问题就是,SVG画布缩放最终看到的结果就是所有的东西都变大了,或者变小了。节点间的关系并不会随着缩放产生变化。比如,当节点很多的时候。你想看一下全局的流程执行情况,于是就把画布缩小,这时你就会发现,所有东西都变小了,甚至线也变小了,节点也小的都看不清楚了。如果可以像地图那样进行矢量缩放,就可以解决这个问题。也就是在不同的缩放情况下,只突出最想表现的东西或者节点关系。
想要做到矢量缩放,就要使用矢量缩放算法。这是绘图技术的基础算法。由于要实时绘制(屏幕更新技术的绘制也能做到非实时)节点关系。这样的工作很不适合在以解析文档描述为基础的DOM形态节点上完成。因为,DOM文档是解释性的,性能本来就不高。它的主要还是突出静态块的关系。
HTML5推出了一个更适合绘图的技术Canvas。什么是Canvas。官方的解释是:元素提供了一个空白绘图区域,可以使用 APIs (比如 Canvas 2D 或 WebGL)来绘制图形。这个区域是专门用来绘制图形的。并且,提供了专门的API来完成更高效的绘制。从兼容性的角度看。Canvas完全不用考虑在不同设备或不同浏览器的表现差异。因为,Canvas的绘制是基于像素与算法的。本质上说,如果你要绘制图形。在任何设备上你能使用的单位都是基于像素的(当然,你可以通过单位换算转化成你要的任何长度单位)。Canvas没有节点的概念,所有的业务逻辑节点,都是算法上的节点,不是像DOM节点那样的文档节点。既然节点都是逻辑上,这样算法可优化的途径就变的非常多了。本质上在Canvas上画图就是在计算像素或坐标点的集合。是线性的几何绘制,会比单纯的盒子模型来的更直接。
现在很多浏览器都专门针对Canvas绘图进行了性能优化。甚至可以直接使用目标设备上的GPU资源。Canvas这种绘图方式,很早就有了。各种图形技术细节也已经很成熟。所以,在复杂绘制场景的需求下Canvas一定是绘图的最佳方式。
以Canvas方式绘图的库很多。比如D3JS、PaperJS、RaphaelJS、GoJS等。也有很多已经对流程图进行基础封装的库。大多都是开源的。
绘图方式的重构肯定是不可逃避的。SVG只是一个过度方式。Canvas才是最终解决绘图问题的途径。
以当前的需求设计看。绘图重构的优先级不高。因为,展示业务的设计没有变化,没有很强烈的用户体验要求,只要能基本表现业务想传达给用户的意思就可以了。
抽象 -- 流程 Flow
这里所阐述的流程是指从一个节点输入数据以产生结果并输出到下一个节点以此类推的过程的集合。节点能以输入的数据为条件执行既定的任务(可以是异步任务也可以是同步任务)。同时,会产生相应的结果或将结果有选择性的传递给下一个特定的节点。
流程主要突出的是执行过程与执行的最终结果,可能成功,也可能失败。流程是抽象的,它是数据走过的所有可预测结果的节点的集合。你能为某些连续的节点集合起一个名字,来方便其区别于其它的节点集合。就像路径一样,达到特定的目标,有交叠,也有分支。
既然流程是节点的集合,在设计流程模型时,就可以根据这一点特性抽象出流程的模型(Flow)。Flow模型应该具有一个集合属性,集合是由节点或子流程组成。该属性是由节点任意组合形成的集合。(任意组合的含义是指业务变化的多样性)。
流程可以很复杂,也可以很简单。从便于理解的角度看,流程可以是多个分支流程的集合。换句话说就是,复杂流程其实是由多个基本单路径流程组成的,如下图。
业务X [总揽]
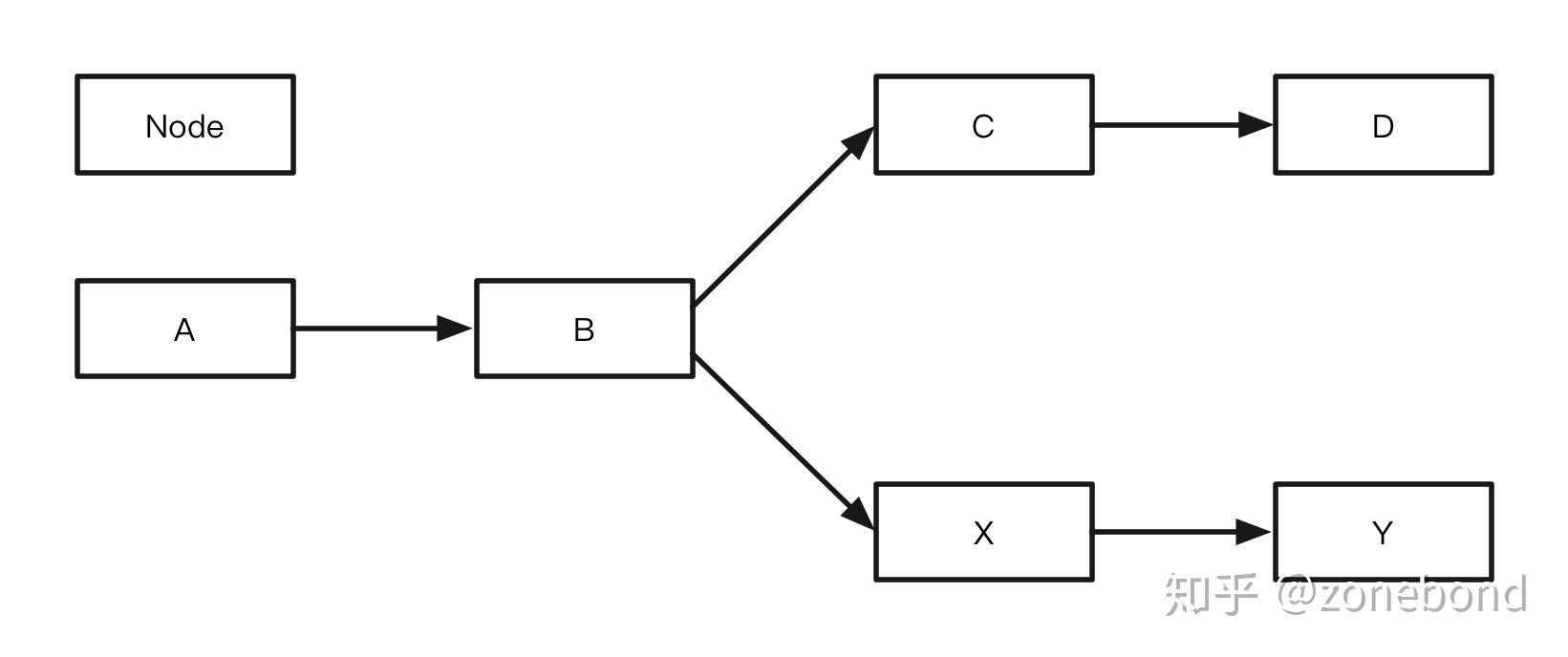
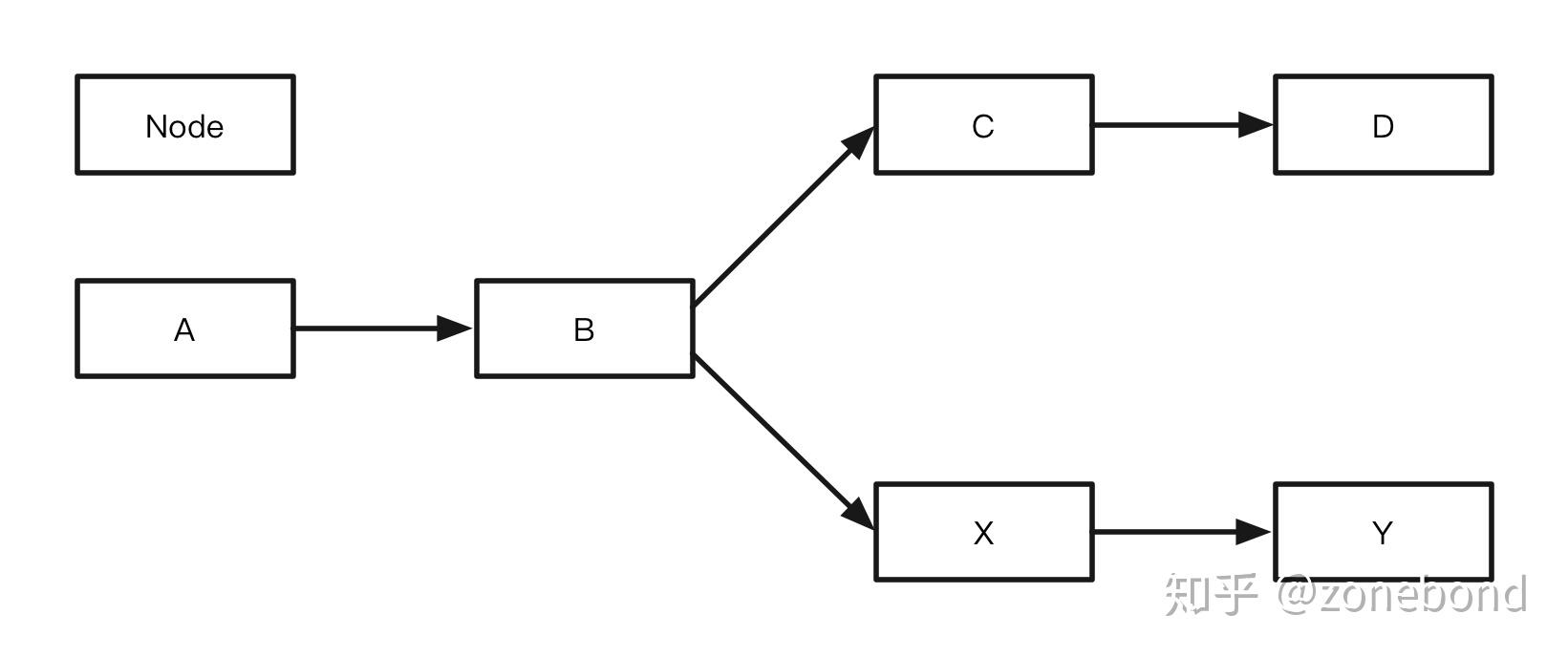
一个完整的业务流程图,是由多个步骤(节点。如上图有A、B、C、D、X、Y节点)组成的。每个步骤都能根据其内部设定好的逻辑对输入的条件做出响应并输出对应的结果。由于不同的结果需要不同的步骤处理,节点需要选择正确的下一步处理节点来处理剩下的步骤。如上图:当B步骤执行完成并产生一个结果后,就需要选择C或X其中的一个步骤来执行下一步,又由于C步骤和X步骤处理的逻辑是不同的,结果有且满足C、X这两个步骤其中的一个,如果满足C则,由C步骤继续执行剩下的业务逻辑。如果满足X,就由X步骤继续执行剩下的业务逻辑。这样一来,完整的业务流程就是由两个相对简单,并且容易理解的单路径子流程(分支流程)组成。如下两图:
流程A
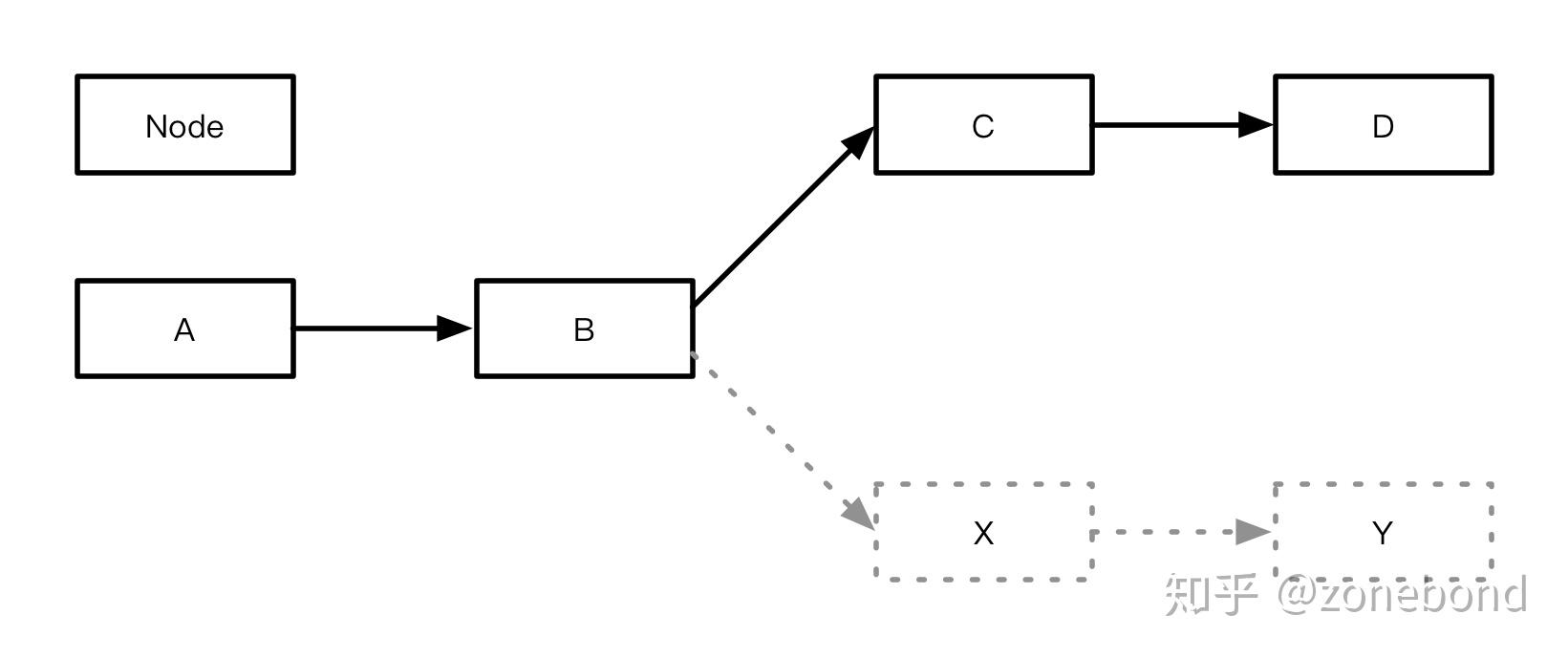

流程B
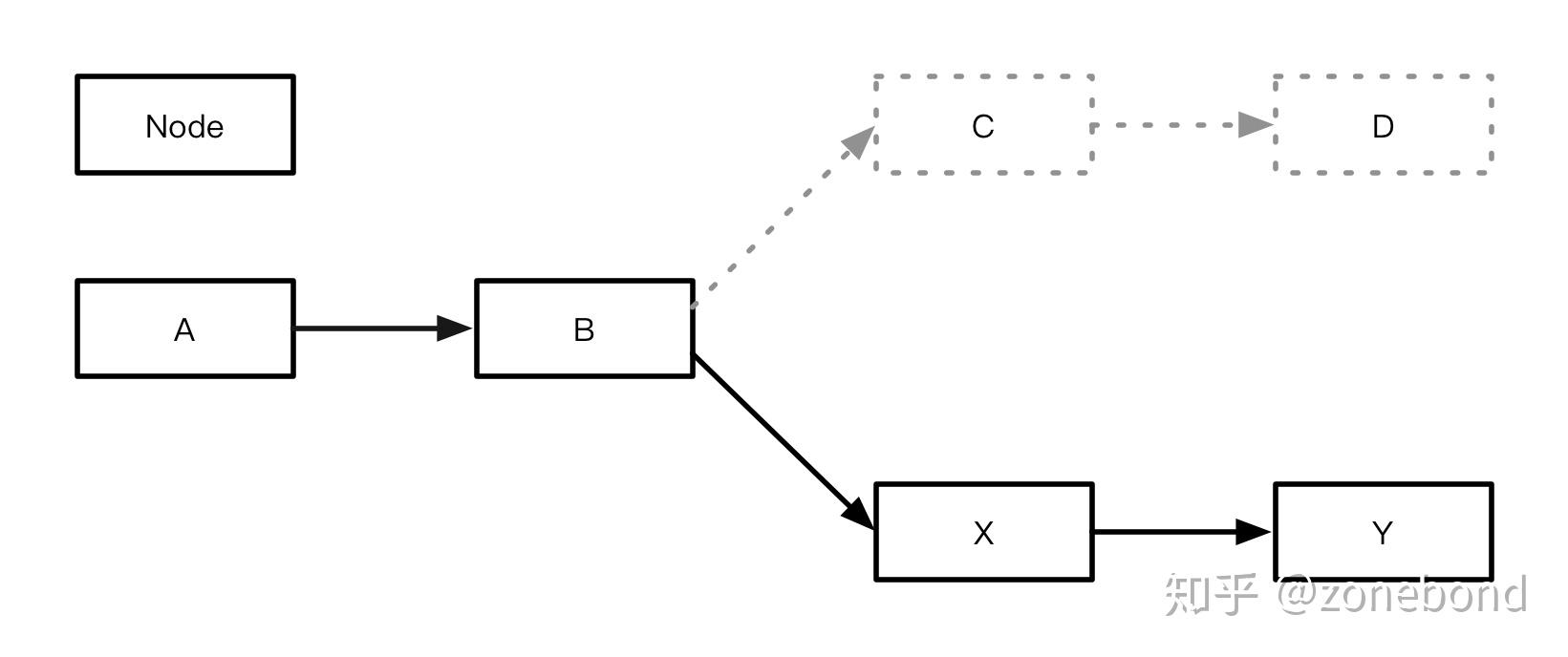

业务流程X是由具体的流程A+流程B组成的。
流程A : A -> B -> C -> D
流程B : A -> B -> X -> Y
从模型的角度看,这样做可以减少模型的复杂程度。每一个节点都只关心输入与输出。每一个步骤只需要处理自己的业务逻辑即可。这样的Flow模型,在可配置扩展方面也是非常便捷和容易的。试想一下。再复杂的业务流程都是由简单的流程组成。然而,简单的流程模型,只需要保存或描述一条完整流程上的步骤集合即可。一个简单的例子:手动从UI界面绘制一个X流程图,并不复杂。如果要从配置文件或从数据结构里(如:JSON、XML等)描述一个X流程会是什么样子。???
// FlowX [json-object]
{
nodes: [A, B]
if(B => B-true) >>> [C, D]
if(B => B-false) >>> [X, Y]
}
// ????
// 将逻辑写在数据里。将会是一种不可维护的灾难!!!很难用扁平化的数据结构完成对流程X的描述,但如果使用子流程的设计方式就可以做到。
// FlowX [json-object]
{
nodes: [FlowA, FlowB]
}
// FlowA [json-object]
{
nodes: [A, B, C, D]
}
// FlowB [json-object]
{
nodes: [A, B, X, Y]
}或者
// FlowX [json-object]
{
nodes: [
{ nodes: [A,B,C,D] }, // FlowA
{ nodes: [A,B,X,Y] } // FlowB
]
}上面这两种方式是类似的,要表达的意思都是由两个简单的子流程A、B组合
成完整的流程X。
在具体绘制流程X的过程中,算法是很容易绘制出如*业务X [总揽]*那样的图形。因为,虽然A、B节点看似同时分布在两个流程里。其实,在两个流程里的A、B节点实际上指的是完全相同的业务处理逻辑节点,也可以理解为A、B节是完全走的是同一段逻辑代码。这么一来就能知道在FlowA中的A、B与在FlowB中的A、B是同完全相同的节点了。也就能在一张图上绘制出合并了相同节点的图形了。
再从持久化的角度看子流程与节点的关系。首先,上面的数据结构是能很容易做持久化的;其次,真正的节点定义(也就是逻辑节点的定义)的逻辑被重用了。而Flow模型的数据里仅仅冗余了流程的标识而已。
*如果把手动拖拽生成流程图比作正向,把数据还原或从配置文件里生成流程图比作反向。以上做法就能很好的完成,从正向到反向,从反向到正向相互转化的过程。*
抽象 -- 节点 Node
无论是节点还是步骤,从抽象的设计层面理解,就是处理输入数据和输出合理结果。节点并不需要知道是谁输入的数据,也不需要关心给谁输出自己产生的结果。换句话说就是:节点不关心上一步节点,也不用知道下一步节点。
所有的节点都基于一个通用的规则。以这个规则实现的节点模型Node。需要有下面的能力来保证业务功能。
- 验证节点被其它节点合法链接的能力。
- 节点的数据处理能力。
- 处理完成的hook。
- 可预见的未完成处理的hook。
- 处理出现异常的hook。
*Node模型*
// Node [Model]
{
// 对接处理。验证是否能对接。
pipe();
// 处理过程集合。
// 处理器processor的逻辑集合。
process = [
// processors
];
// 处理完成
resolve();
// 无法完成
reject();
// 过程异常
catch();
}在设计流程的过程中,需要连接两个节点时(如图):
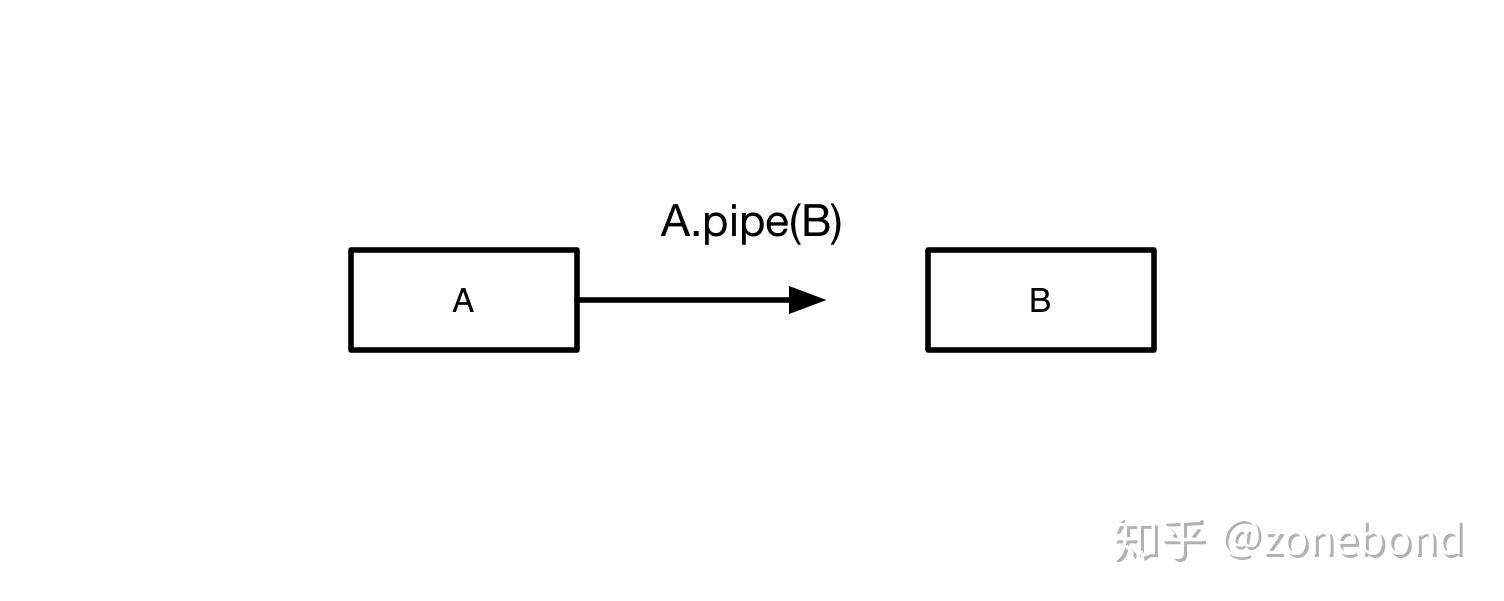

A节点试图连接B节点时,A节点对象主动执行pipe行为到目标节点B。 A节点将自己的*输出规则*与B节点的*输入规则*进行匹配(匹配规则可以是单个,也可以是多个组合。只要输出成功或失败即可)。如果匹配成功,就能连接。匹配不成功,就不能连接。这样,每个节点都只需要关注独立的输入规则和独立的输出规则,就可以轻易的完成节点合法连接的功能特性。
节点执行业务逻辑的过程。是顺序调用process中的处理器processor的过程。如图:
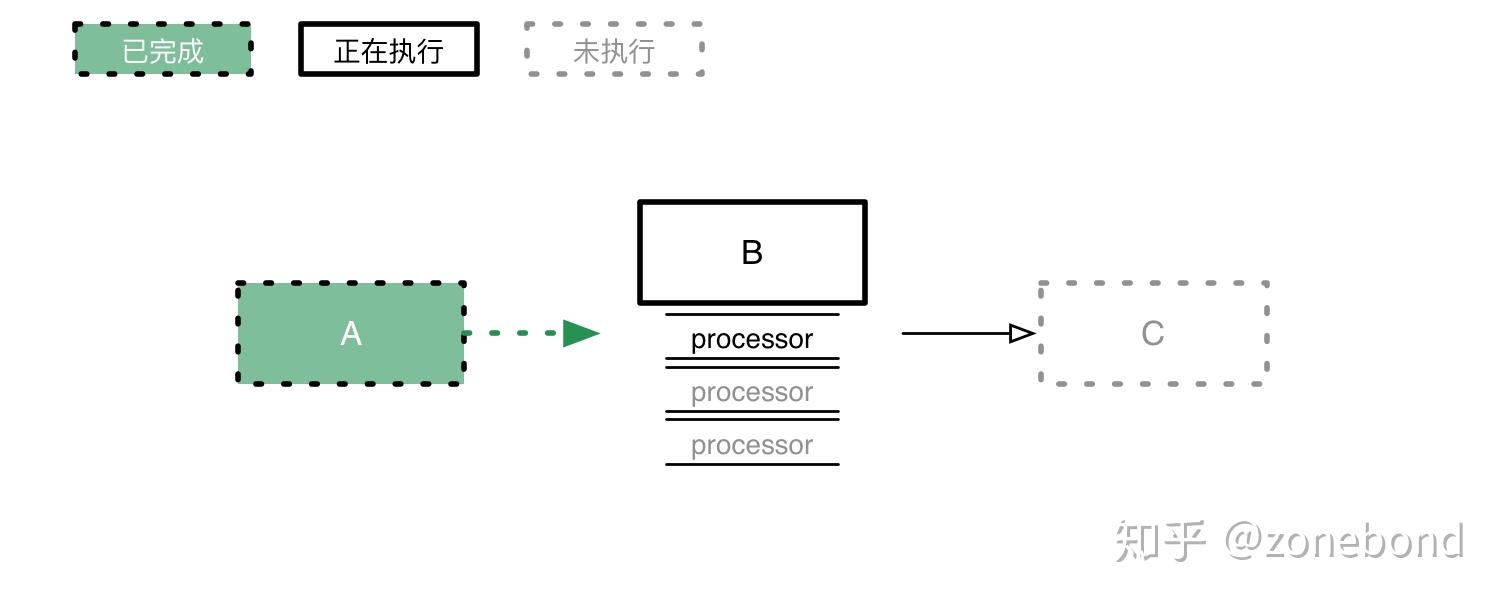

执行过程可能成功,也可能失败或者异常。节点根据processor实际执行情况,处理相应的hook钩子,如resolve,reject,catch。hook钩子具体行为会在Flow流程模型中实现。可以是继续执行后续的节点,或停止,或捕获异常,或在处理完异常后继续执行。
*这样一来,Flow流程就只关注流程本身的设计实现、与流程控制,Node节点就只关注处理具体的业务流程。*
规则
> 如何判断或不判断下一步执行逻辑。规则设计与描述。
> 如何流程与节点集合时。规则设计与描述。
关于*节点可连接性*判断的实现方式有很多。最简单粗暴的实现就是直接给出根据节点类型或节点标识来判断是否可以连接的*比对表*。从业务需求的实际情况出发给出节点的可连接节点的集合,最后综合成节点的可连接表。这样做的好处就是在初期,节点类型相对较少的情况下会比较简单、容易实现。这种做法的缺点很明显,当节点多的时候*比对表*的内容就会成倍增加,处理比对行为所需要的性能代价也会成倍增加。另一个问题是,每增加一个节点,就需要考虑它与其它所有已经设计好的节点的连接可能性,这就需要在设计新节点的同时,必须了解和关注其它所有已有的节点,这样一来扩展方面会是个问题。另一种*节点可连接性*判断的实现方式是。以发起连接行为的节点的输出内容做为被连接节点的输入条件,如果满足被连接节点的输入条件要求,原则上就表示,被连接节点是可以执行的,也就是说这两个节点是可以连接的。更复杂的情况是,当一个节点的输入条件被部分满足时,也是可以链接的。因为,有一种场景是节点会有多个输入节点。如图所示C节点就是一个这样的节点。
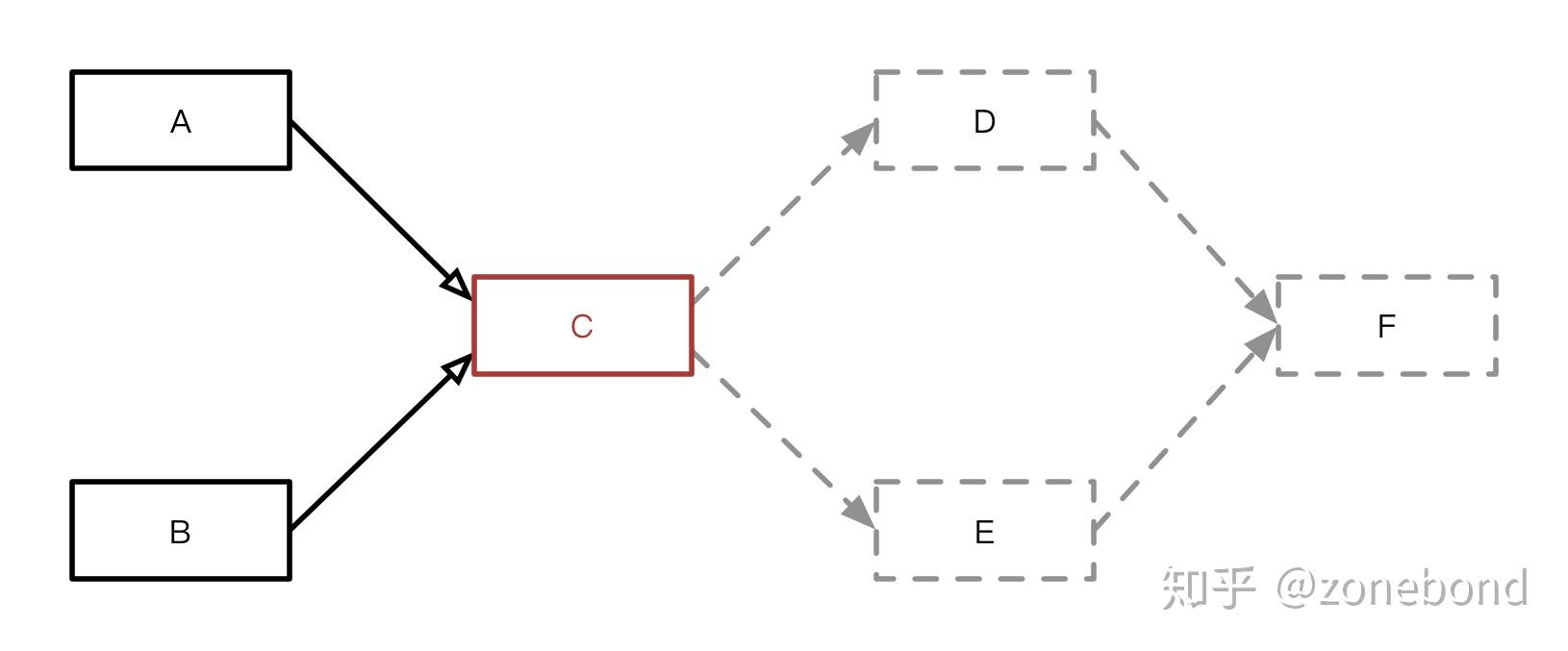
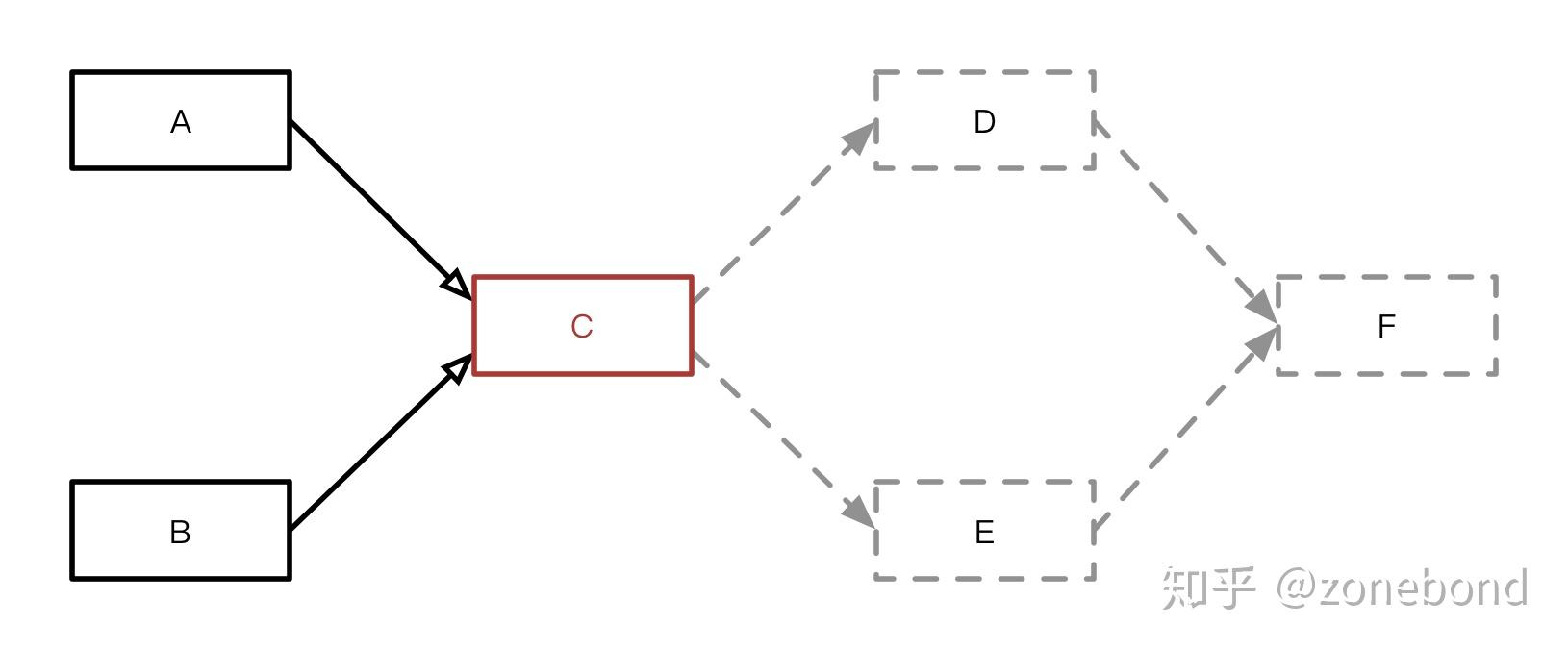
A、B两个节点的输出结合起来就能满足C节点所需的完整输入条件。匹配对应条件的实现方式使用*GOF设计模式*中的*建造者模式(Builder Pattern)*就能很容易和优雅的实现。使用输出结果匹配输入条件这种做法的优势很明显。节点在任何时候都只需要关注业务本身赋予自己应该有的处理逻辑的情况下,要保证正确的执行业务逻辑时,就需要满足正确的输入条件。换句话说就是:只要给节点输入节点要求的条件,节点就执行,就有可能完成业务任务。从性能与扩展的角度看,这样做可以使判断更有效率,添加新节点时所需要关注的点变少,扩展复杂度降低。
扩展
- 流程扩展:
上面已经描述了流程是处理节点或子流程的集合。从用户的角度看,把复杂的流程,拆分成更容易理解的简单流程的组合,会给用户更清晰,更友好的使用感受。并且在复杂的流程中,抽出重复的部分做为典型的公共流程,或者,设计出适应普遍场景的标准子流程,将它们进行任意合乎业务逻辑的组合,或者只创建新流程新增加的部分,再将其与标准流程或者已有流程结合,就能创造出更多更复杂流程。
2. 节点扩展:
节点模型扩展主要涉及的是,在业务变化时能快速创建出可以覆盖新业务能力的节点。节点的核心职责是处理业务行为,以节点模型为基础派生出的各种类型的业务节点模型,则可以做到更多,如:执行状态、扩展业务属性、节点特殊处理等。
前后端服务的交互
一般的设计是把所有的逻辑与操作都发请求到后台,即便是一些无效的用户操作行为,也会发请求到后台。这样设计的结果是,用户交互体验很不友好、卡顿、通信效率非常低下。并且,大量的请求也导致服务端资源的浪费。
从业务逻辑的实用性的角度看,前后台需要交互的点只有:状态保存、状态查询。状态保存可以用浏览器本地存储+定期计划同步的方式来实现更有效率的状态保存(不考虑,同一个流程在多个客户端同时编辑的情况。这种场景数据库只保存最后一次正确的同步即可)。即使是用户细微的无效操作再多,在一个同步周期内,状态会实时的保存在本地存储器内,当到达同步时间时,只要从本地存储中获取最后一次更新时间,加上在此期间是否有需要保存的有效的操作,就能很高效的实现状态保存,不会因为网络原因,或者服务器忙等因素导致用户操作不流畅、卡顿、停止等极差的用户体验。状态查询的实现有多种方式,主要还是考虑前后台数据交互的效率。比如,要查询一个正在执行流程的状态。当服务器获取到流程执行状态变化时,也就是需要更新流程状态的时候再推送状态数据给前端,减少不可控与不必要的请求。
