
(十)简单解释: 分布式数据流的异步快照(Flink的核心)

(注意:文章其实是给“我自己看的备注”,内容力求“自己”忘记了重点之后,“自己”回来瞄一眼就能想起来,会有很多自己的理解和“原论文没有的内容”在里边,“可能会为了其他读者”加入一些内容,比如本文的问题描述部分,我自己其实不会去看。。。请谨慎选择阅读~ )
大家好,这是这个专栏的第十篇文章。。
嗯。。。先生,请放下手里的板凳,先听我解释。。。。
讲道理,这个专栏开篇第一篇应该写FLP Impossibility,一切分布式系统混乱的根源。但是由于一来FLP这篇论文记住结论就好,论证过程我有点懒得回去看,二来最近正好安利了评:Streaming System(简直炸裂,强势安利) 这本书,那么其实配合这本书,我们来学习下流系统几篇比较相关的论文比较好。(所以最近会开始给这个专栏写文章,全部都是流系统相关)
为了给“我心目中更重要的论文留位置”,我们暂且从index10开始吧~
注意:本专栏的文章目标是简单解释,不做冗长细致的论证解释,目的是给读者达到直觉上的理解即可(感觉非常难。。。把长文写短其实特别难。。。)
==================以下正文 ===================
问题简述
当我们有一个数据处理流中的各个处理节点,需要保持自己的状态的时候(比如接受一个消息之后,就根据消息更新自己的状态,比如消息记数),怎么保证node的自动failure recovery 的时候,不会造成各个节点的状态不统一从而影响后边的处理呢?
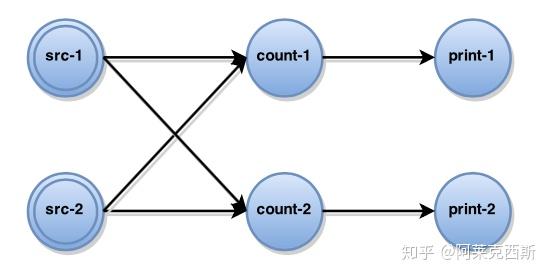

比如上图,当所有的src不再发出消息,那么最终count-1和count-2的计数必须是一样的,且print是只增的。然而当count-1节点挂掉,然后重启,怎么保证它和count-2一致呢?保证print-1和print-2最终会打出一样的数字呢?且保证print只增呢?
一种方法是所有节点记住所有发出的信息,失败重发,下游记住所有收到的消息和所有每个消息所导致的最新状态,failover之后要求所有上游从失败前的消息开始重发,且,只能重发给失败的节点(也就是src-1和src-2要记住不能给count-2重发),且count-1要记住所有这些重发的消息不能导致print打出老的数字(否则违反只增性),而重发结束就要立刻开始给print发出应有的消息。当系统内节点非常多和复杂的时候,记录整个图的消息流动会非常复杂和导致high cost。
Lightweight Asynchronous Snapshots这篇论文提供的算法,是Flink解决Exactly Once Message处理的核心算法。它的优点是不需要所有计算节点记住所有发出的信息。只需要数据源可以replay就行了,超级轻量级。【对比财大气粗的有完美infrastructure支持的Google DataFlow/MillWheel, 记录了所有Shuffle(因为一般shuffle才需要跨机器节点通信)的record在BigTable或者Spanner里,用一个保证consistent的垃圾回收算法来清理无限增长的record。回头讲MillWheel论文的时候会详细讲】
MillWheel [18] offers a complete end-to-end solution to processing guarantees, similarly to Flink. However, its heavy transactional nature, idempotency constraints and strong dependence on a high-throughput, always-available, replicated data store [28] makes this approach infeasible in commodity deployments.
---- Flink的一篇论文对MillWheel的评价
单向图算法(无环)
- 所有的通信channel需要是先进先出(FIFO)按顺序的
- 中心coordinator:需要有一个中心coordinator来不断广播持续增长的stage barrier到所有的src数据流里。(比如先给所有src发1,然后5秒后发2,10秒发3..... 如此增长)
- 数据源src,当数据源收到第n个barrier的时候:
- -保存状态,保证当需要replay从任意n开始的消息时,可以replay在自己收到barrier-n之后的所有消息。
- -广播barrier给下游。
- 中间处理节点或最终叶子节点:假设一个中间处理节点或最终叶子节点需要m个input流,当在某个input流收到barrier-n的时候,
- -block这个input流保证不再收取和处理。
- -当收到所有m个input的barrier-n的时候,
- --Pi-LocalSnapshot-n: 保存本地状态(take local snapshot n), 保证可以从这个状态恢复(比如存到云端, 在另外x台机器做replica),假设我们每个logic processor都有一个id为Pi,那么每个logic processor的在收到所有inputs的barrier-n之后所保存的本地状态快照则设为Pi-LocalSnapshot-n
- --向自己的下游广播barrier-n (如果是叶子节点没有下游,那么不需要广播)
- CompleteGlobalSnapshot-n: 当所有的节点(源,中间处理,叶子节点)都处理完barrier-n且完成取快照(take snapshot)的任务之后,我们说我们有了一个完整的全局快照。这意味着我们的deterministic的进度,进步到了barrier-n
单向图Failover
当需要任意节点挂掉,我们从最近的Complete Global Snapshot-n,来重启整个系统;即,健康的节点rollback自己的状态到“接收到barrier-n时候所取的状态快照。fail掉的节点的逻辑Processor Pi被jobManager之类的东西,用自己在的Pi-LocalSnapshot-n重启设置本地状态之后,才开始接收上游的消息。
为什么这样就consistent了?
可以看到当failover的时候,全部节点的状态都回退到了barrier-n之前的数据源message所导致的全网状态,就好像数据源在barrier-n之后根本没有发过消息一样。不断发出的barrier就好像逻辑时钟一样,然而“时间”流动到不同地方的速度不同,只有当一个时间“点”全部流动到了全网,且全网把这个时间“点”的状态全部取了快照(注意当网络很大,最后一个节点取完快照,初始节点可能已经前进到n+5,n+10了,但是由于最后一个节点才刚取完快照,CompleteGlobalSnapshot-n只到n,n是全局consistent的记录点),
如何可以不用全网rollback?
如果没挂的节点的运算可以自动忽略老的已经处理过的消息(或者说replay导致的消息),那么我们只需要重启所有从源到fail掉的节点的这条线即可(比如下图的黄色节点)。
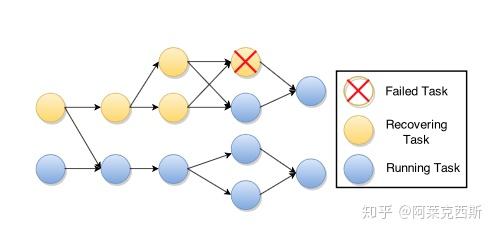

带环图算法/Failover
(先留空吧。。。单向图都不一定有人看。。。。有人看再补上。。。)
==================正文结束=================
最后想说几点:
- 论文的内容往往相当硬核,这也是我这个专栏开了快半年了一篇文章都没写的原因。因为知乎里按原文讲论文的其实不少,但是观者了了... 所以我打算以自己的理解和语言来写简短的解释,忽略我觉得不重要的,补充我觉得可以帮助理解的(比如状态存在云端或者replica这句话,原论文没有,但是我觉得肯定有小朋友有疑问说本地硬盘随着机器一起挂了怎么办,所以加上),而不是严格遵循原论文的用词和行文(因为这样做文章会非常非常长)。
- 即便如此,论文也一般比较抽象难懂,我选这篇作为第一篇的原因之一,也是因为这篇论文在分布式系统论文里算比较简单易懂的,我们先来看看它的效果。。。。
- 分布式系统的论文对于理解分布式系统非常重要,因为它往往抓住了问题的本质,然后去给出一个抽象解。这些对问题的分析和它们的解,是任何分布式系统的骨架(backbone);这样我们在学习具体系统的时候,我们就可以从纷纷扰扰,超级逻辑复杂的细节中,隔离出这些会影响系统本质设计的主线,来理解系统在面对问题时候的取舍。当你对骨架了解之后,你翻Streaming System或者High Performance Spark这种书,基本跟玩儿一样。(迫真,亲身体验)
- 开始难,但是一旦明白了这群人写论文的套路,其实刷论文也非常简单。实在不行可以在知乎提问,老司机自会来答疑解难。


我选择了气宗,这一年疯狂看论文的感觉,棒极了!
(感谢观看~)

