
文本检测之TextBoxes

简介
论文题目:TextBoxes: A Fast Text Detector with a Single Deep Neural Network
论文地址:https://arxiv.org/abs/1611.06779
代码实现:https://github.com/MhLiao/TextBoxes
传统的文本检测方法分为:1).character-based;2).word-based;3).text-line-based;论文中提出的TextBoxes属于word-based,与其它方法相比,它采用的是端到端的训练方式
论文关键idea
本文和SegLink一样,也是在SSD的基础上进行改进的.相比SSD做了以下的改进:
- 修改了default box的apect ratio,分别为[1 2 3 5 7 10],目的是适应文本行长度比较长,宽度比较短的特性,也就是说现在的default box是长条形
- 提出了text-box层,修改classifier卷积核的大小为 1\times5 ,而SSD中卷积核的大小为 3\times3 ,这样做的目的是更适合文本行的检测,避免引入非文本噪声
- 提出了端到端的训练框架.在训练的时候,输入图像由单尺度变成了多尺度
- 增加文本识别来提高文本行检测的效果,印象当中,白翔老师好像在一个报告中说过,增加文本识别在可以提高文本行检测的准确率(这里如果记错了,请告诉我).
Pipeline:
TextBoxes是一个28层的全连接卷积网络,整个网络结构是基于SSD的改进版,具体步骤如下:
- 对于特征提取层:依然采用VGG16作为主干特征网络,保持conv1_1到conv4_3不变,将VGG16的最后两个全连接层改成卷积层.并在此网络的基础上增加若干个卷积层和池化层(conv_6到pool11).
- 对于text-box层:主要是通过提取不同层(包括conv4_3,conv7,conv8_2,conv9_2,conv10_2,pool11)的feature map,分别通过不规则形状( 1\times5 )的卷积核.对于不同的feature map,最后输出的维度为72
- 将上述的输出经过非极大值抑制(NMS),得到最终的输出结果.
具体的网络结构如下:


为了更好地与SSD网络结构进行对比,这里也给出SSD的网络结构,如下:


具体实现细节
Text-box layer
它是TextBoxes的核心,同时负责两种预测:文本行/非文本行预测和文本行的bbox预测.在每个特征图的每个位置上,它同时输出文本行的概率及其相对于default box的偏移.
- 文本行的bbox预测
对于bbox的预测其具体的公式如下:
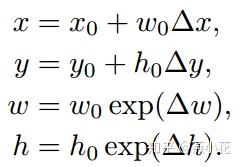
其中即为当前检测的bbox, (x_0,y_0,w_0,h_0) 表示feature map上的default box, (\Delta{x},\Delta{y},\Delta{w},\Delta{h}) 为当前网络学习到的偏移,这里说白了就是我有一个default box,然后网络学习了bbox的偏移,那么最终检测得到bbox就是在default box上偏移后的bbox(可能说的有点绕口).
- 训练图像中文本行的ground truth与default box的匹配原则
这里与SSD文中的方法一样,采用的也是box overlap.这有效地将文本行按照各自的尺寸和宽高比进行划分
- default box
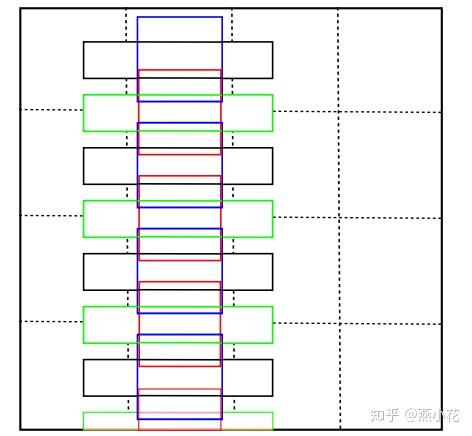
为了更好地适应文本行的large aspect ratio,论文中设计了长宽比分别是1、2、3、5、7、10的default box(即长条形的default box)。但同时也引入了另外一个问题:default box在水平方向上排列紧密而垂直方向上排列稀疏,这会造成检测失误的情况
针对上述问题,论文中将水平方向上的这些默认框全部向下平移半个区域的单位(下图中黑色与绿色,蓝色与红色),这样一个位置总共12个默认框,解决了默认框排列不均匀的问题。

- 输出层的卷积核
在text-box层采用的是不规则(核大小为 1\times5 )的卷积核,而SSD中采用的是的 3\times3 卷积核,这就产生了矩形感受野,更适合用于文字检测,避免正方形感受野引入的噪声.
值得注意的是:TextBoxes主体结构全部由卷积层和池化层构成,因此它在训练和检测的过程中可以适应任何尺寸的图片。
- 层输出维度
每个位置有12个default boxes,所以网络的输出维度: 12\times(2+4)=72 ,其中2表示文本/非文本,4表示bbox的(x,y,w,h)
Learning
损失函数方面,TextBoxes的损失函数与SSD的损失函数一样,也包含两部分构成:文本行的二分类损失和文本行的bbox位置回归损失,具体公式如下:


其中N表示已匹配的default box的数量, \alpha=1 .文本行的二分类( L_{conf} )损失采用的是soft-max,文本行的bbox( L_{loc} )采用的是Smooth L1
Multi-scale Inputs
虽然在default box和卷积核上进行了改进和优化,但是在检测长文本行(即超过了默认框的最大比例)还是会出现检测不到的情况.针对这个问题,论文提出将原图片放缩到不同的大小(这里缩放到5个不同的尺寸,分别为 300\times700,700\times700,300\times700,500\times700,1600\times1600 ),这样某些在水平方向很长的文字就会被挤压从而满足默认框的比例,这种方法提高了检测的准确度,但是会消耗一定的运算能力。
非极大值抑制(NMS)
对tex-box层的输出,采用非极大值抑制得到最终的检测结果
端到端的识别模块
这里识别模块采用的是CRNN模型,TextBoxes检测的结果会被送入CRNN网络中识别.通过加入识别模块,增加文本行检测的准确性
注意:关于识别模块之后会有专门的文章详细介绍
训练参数
TextBoxes训练的图片大小为 300\times300 ,使用的SGD进行优化,Momentum设置的是0.9,权重衰变(weightdecay)设置的是 5*10^{-4} 。学习率开始的时候为 10^{-3} ,经过40k次迭代后 10^{-4}
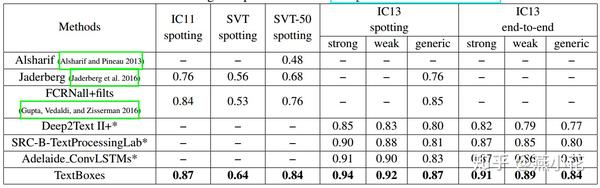
在ICDAR2015上的评测结果

使用TextBoxes训练自己的数据
这里不给出源码编译过程,直接上检测结果图








总结及源码实现
总结
- 与SegLink一样,TextBoxes也是基于SSD进行改进,与SSD和SegLink的不同之间在于default box的个数及aspect ratio.输出层的卷积核大小也不一样
- 与CTPN一样,TextBoxes在水平方向检测效果的好,因为其default box是水平框,回归的是水平矩形框
- TextBoxes的不足之处,对于曝光过度的地方并不能识别出文字,对于字符之间间距过大的单词识别效率也不高
源码实现与论文中的差异
- TextBoxes的源码是基于caffe的实现,虽然文中说的text-box层中每个feature map的输出维度是72(12个default box的文本/非文本得分及bbox的位置信息),而实际源码中除了conv4_3的输出维度是 12\times(2+4)=7 ,其它层的(conv7,conv8_2,conv9_2,conv10_2,pool11)的输出维度是 14\times(2+4)=84 ,这里和SSD一样,每层的default box的个数不同.
- 论文中text-box层中的pool11的卷积核大小为 1\times1 ,而实际源码中的卷积核的大小为 1\times5
文人文笔粗浅,以上是个人对这篇文章的理解,若有理解错误的地方,欢迎指正
