DeepHash 论文简要

由于项目的需要,需要用到从图片生成hash值的方法,以期能够在图像去重和视频去重中发挥作用。
Liu_Deep Supervised Hashing for Fast Image Retrieval_CVPR_2016_paper
首先DeepHash的目的是对一张图片生成一个hash值,相似的图片的hash值尽可能完全一样,不相似的图片最好没有一位相同。
两个问题:hamming距离不可导,只是比对相不相同;生成的hash值为0或者1。
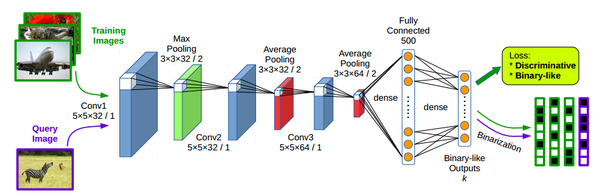

训练模型分辨图片是不是相似,自然得用上经典的孪生网络的结构。
在每个batch内部生成pair 对。
Loss方面得做一些改变。
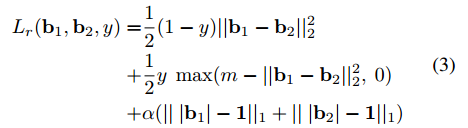

很显然不能用hammming距离,只能用欧式距离,整体的loss和Contrastive Loss 一样,再加上一个正则项,使得每一位尽可能接近于1或者-1,方便生成hash值。
训练是一套relaxed loss,实际使用的时候直接使用符号函数,这里存在的GAP已经决定了效果不会太好,至少很难做到两张相似的图片产生完全相同的hash值。
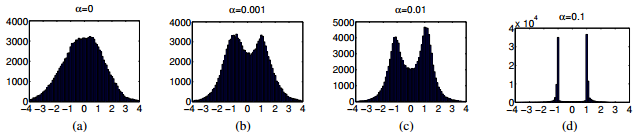

如图中所示,alpha越大,输出值越接近1或者-1.
Deep Learning of Binary Hash Codes for Fast Image Retrieval_cvprw2015
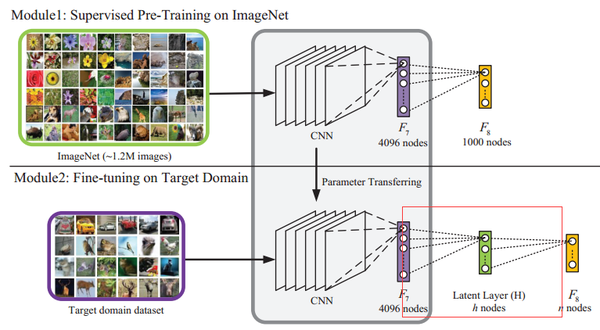

文章的idea极为简单,就像文中所说,一张图片属于某一个类,一定是图像中某些concept起作用,于是加入H层,节点数目为hash值的维度,利用sigmoid 激活函数,使得输出为0或1,从而得到一个近似的hash值。
文中最大的问题,也是所有DeepHash最大的问题,就是用的数据集是带label的,也就是图片如果属于同一类就会认为是相似图片,这样的结果是太粗粒度,实际上hash 值需要定义为输出来的类别即可,何必弄的那么复杂。
Deep Supervised Discrete Hashing NIPS2017
主要的不同点在于优化方式上,我觉得文章声称的主要的创新点--利用分类的信息,这一点实在不是创新,而是一个短板,利用图像原有的label,和上一篇论文的思想一样。
几个不同点:
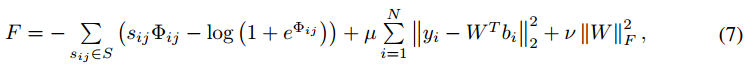

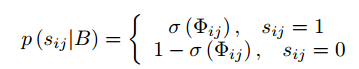
如果是相似图片,最后一层的输出做內积,而不是欧式距离。
最后一层输出直接拿来做分类,这里只是简单L2范数。
训练方式,迭代更新:
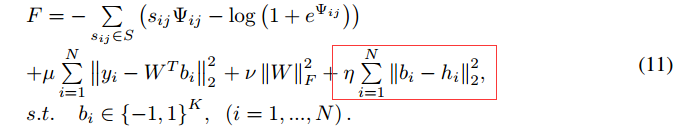



确实也只有迭代更新上有点不同的感觉。
Learning Compact Binary Descriptors with Unsupervised Deep Neural Networks cvpr2016
重点是无监督,图像可以是无label的。
实际上是大量的样本自己去产生类似的hash值,隐含的聚类。
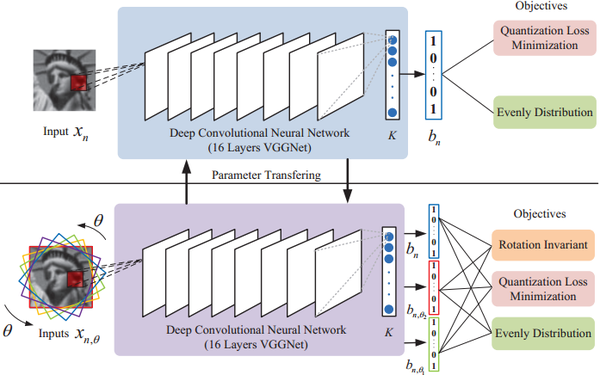

同一张图片,3个loss
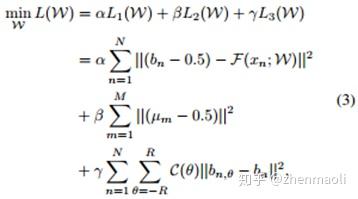
第一个loss和其他方法一样,尽量让输出趋于符号函数。
第二个loss,主要是让hash值每一位为1或0的概率为0.5,没有什么偏向性,。。这点存疑,由数据的分布决定了。
第三个loss,主要是图像旋转带来的误差消去。
实际上一个隐含的事实是,一个网络对相似的图片更可能产生相似的输出,取符号函数则更容易。可能最大的问题,没有显式的规定相似的图片产生相似的hash 值。
HashNet Deep Learning to Hash by Continuation_arxiv_2017
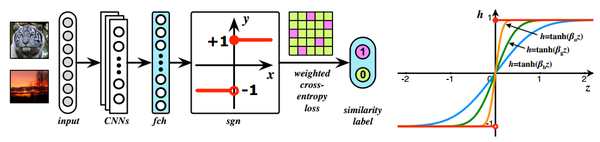
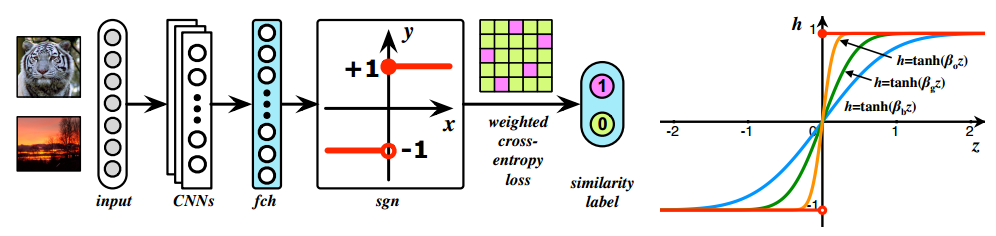
最大的改进是用tanh激活函数不断的去逼近符号函数,其他地方和普通的方法差不多。
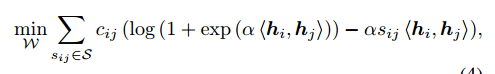

距离取的是內积。
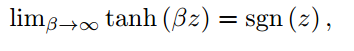
训练起来有些麻烦,不太好调的样子。
Feature Learning based Deep Supervised Hashing with Pairwise Labels IJCAI2016
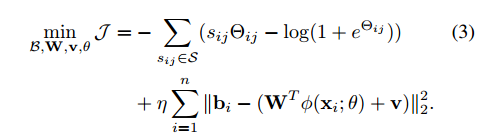

没啥特别的,內积+正则
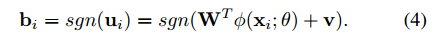

总结一下:
看似每年的顶会中都有一些DeepHash的文章,但是方法上几乎没有大改变,所有看少量有代表性的 文章就足够了。
基本都是siamese network+contrastive loss。但是为了产生hash 值,需要加入正则项,使得输出尽可能符合符号函数。衡量两个hash值的距离不能用hamming 距离,因为不可能,所以采用欧式距离或是余弦距离。
然后DeepHash的工作最大的问题是用了带label的数据集,本身图片就可以通过网络分类的类别来搜索,所以用hash值进行搜索的意义何在??以类别作为hash值岂不是更准,然后就退化成简单的分类问题了。这点一直不太明白。(评论中有回答)