BiLSTM+CRF、CRF++比较实验与思考

跟着这篇博客来走的,最后加入了CRF++的比较试验:
github代码也在上面的链接中
两篇经典的论文:
Bidirectional LSTM-CRF Models for Sequence Tagging
1.Abstract:
state of the art (or close to) accuracy on POS, chunking and
NER data sets, less dependence on word embedding
2.Introduction:
LSTM:use both past and future input features
CRF:use sentence level tag information
3.Model:
Bi-LSTM:BPTT、dropout
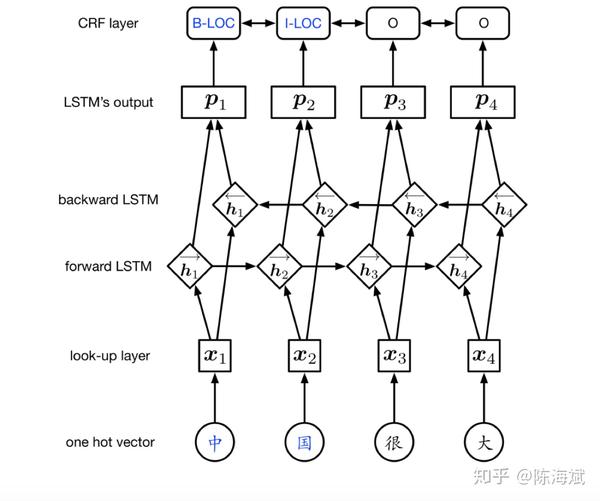
Neural Architectures for Named Entity Recognition
1.Abstract:
models rely on character-based word representations learned from the supervised
corpus and unsupervised word representations learned from unannotated corpora
2.Introduction:
NER problem: a very small amount of supervised training data available,few constraints on word
(1)NER consist of multiple tokens BiLSTM+CRF和stack-LSTM 字向量
(2)one token:词向量
dropout提高泛化
3.Model:
LSTM直接输入对POS较有效,对NER这种对外部语料依赖性很大的效果较差,因此把LSTM输出作为打分矩阵,表示某个词被标注为某个标签的概率
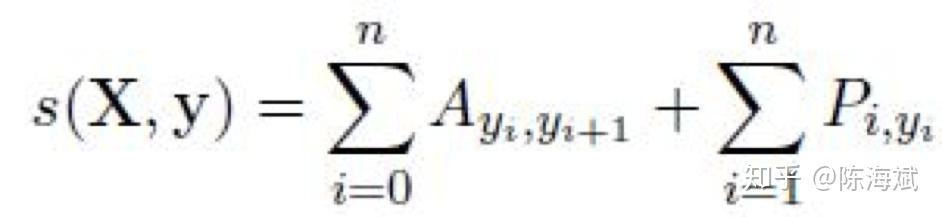

打分系数,其中A为标签转移得分,训练时使用极大似然估计
4.Parameterization and Training
变量:打分矩阵A,BILSTM计算P参数,词向量
若A随机生成 似乎效果也不是很好
为了更好的效果,把LSTM输出全连接接入线性隐层
5.word embeddings
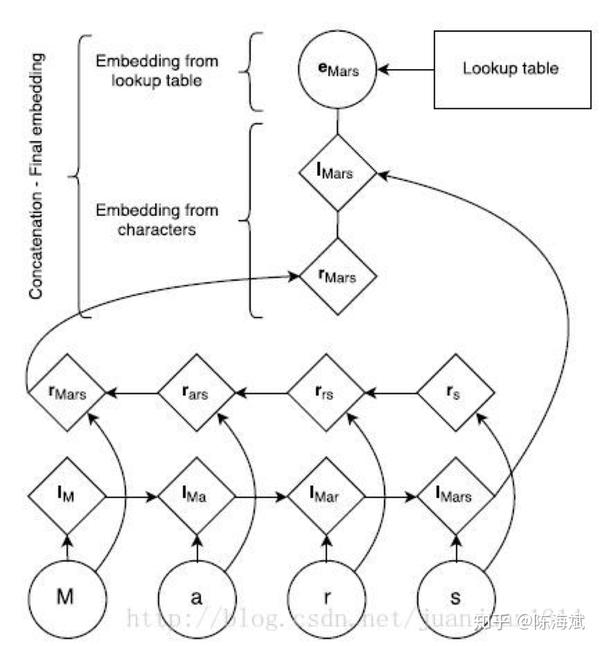

随机生成字母向量表,根据LSTM正序逆序加上原先词向量获得最后的词向量(也可用cnn提取前缀后缀特征)
实验用的是github已完整实现的命名实体识别的代码
ner语料为msra语料库
作者的默认数据都是到40轮,我只跑了15轮到达相对接近的准确率就停下来了
无CRF Bilstm后接softmax输出 loss一下子就下降到很低(局部信息易拟合?)在0.03左右一直波动,准确率缓慢提高


有CRF默认数据 loss稳定变小最后到0.15左右 但准确率变化已经比较少了 比不接CRF的更快拟合 总体准确率比无CRF的更高 ORG组织名明显比无CRF的好多了 看起来对于组织名的实体识别 前后几个字的线性加权特别重要


以下单跑一个CRF++的
参数:-f 3 -c 4
跑了1小时就完成了…传统方法还是快
accuracy is 0.141521111264 recall is 0.939211555823 f is 0.245978061254
准确率出了很大问题
准确率公式记错了..导致结果出了问题 一开始还以为是crf++参数的问题 这过程中一些自己的猜想在最后进行否定和解释
CRF++结果:参数 –f 1 –c 4
地名:accuracy is 0.845963416311 recall is 0.9573540856 f is 0.89821845794
组织:accuracy is 0.852735323525 recall is 0.9008601177 f is 0.87613736425
人名:accuracy is 0.916380494505 recall is 0.9549114331 f is 0.93524927714
实验对比:
三个准确率为地名、组织、人名
BILSTM+softmax(15轮)准确率分别为85%、70%、81%
BILSTM+CRF(15轮)准确率分别为84%、85%、91%
作者跑了40轮准确率分别为91%、85%、87%
CRF++跑准确率分别为91%、85%、86%
如下表
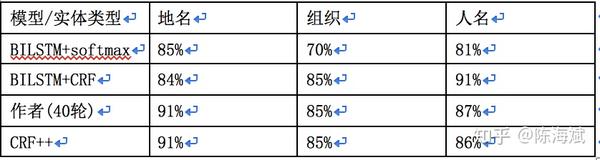

实验效果总结:
目前来看BILSTM+CRF效果略优于CRF++,只有BILSTM效果明显最差
时间来看,普通语料CRF++1 2个小时肯定能跑完,而用深度学习模型跑了15轮大概用了4个小时(只是接近稳定而已),是传统模型的好几倍。
结论:
1.训练集和测试集差距比较大,训练集普通句子多,命名实体少,测试集命名实体多了很多,但是这并不影响实验结果
2.在网上看到其他人用crf++做NER达到90%准确率,是先提取出了更多特征:词性、是否为实体结尾词、是否为句子结尾词等等,准确率能进一步提高。注:常用特征工程可用spacy包来做。
3.NER训练语料特别“稀疏”,但这并不会导致欠拟合,传统方法、深度学习方法都是这样,CRF++只使用出现3次以上特征对结果影响也不大
4.调参对传统方法CRF++影响并不大,正则化系数、特征选择等参数改变对结果影响不到1%,但深度学习方法参数选择不好效果远远不如传统方法CRF++
为什么LSTM+CRF是最好的baseline?提供一些可能的可解释性:
1.crf构造字符间的特征对应关系,而lstm提供了词向量的泛化,比如“我”和“是”的对应关系,经过lstm的泛化后相近语义的两个字符也得到了这种对应关系。
2.lstm提供了长距离的依赖建模,加强了局部窗口(当前字符以及上下字符)的联系关系,序列标注问题比较简单就得到了还可以的效果。
