
【NLP】Transformer模型原理详解

大家好,我是在算法前沿旋转跳跃的焦燥女青年rumor。
注:文末附上我总结的BERT面试点&相关模型汇总,还有NLP组队学习群的加群方式~
自Attention机制提出后,加入attention的Seq2seq模型在各个任务上都有了提升,所以现在的seq2seq模型指的都是结合RNN和attention的模型。之后google又提出了解决Seq2Seq问题的Transformer模型,用全attention的结构代替了lstm,在翻译任务上取得了更好的成绩。本文主要介绍《Attention is all you need》这篇文章,自己在最初阅读的时候还是有些不懂,希望可以在自己的解读下让大家更快地理解这个模型^ ^
Attention原理还不熟悉的可以看:
1. 模型结构
模型结构如下图:
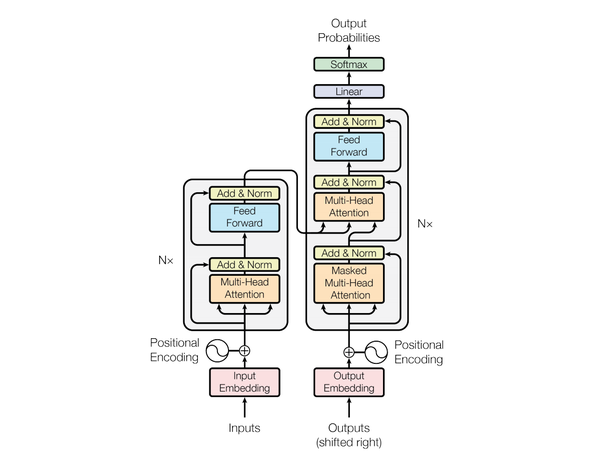
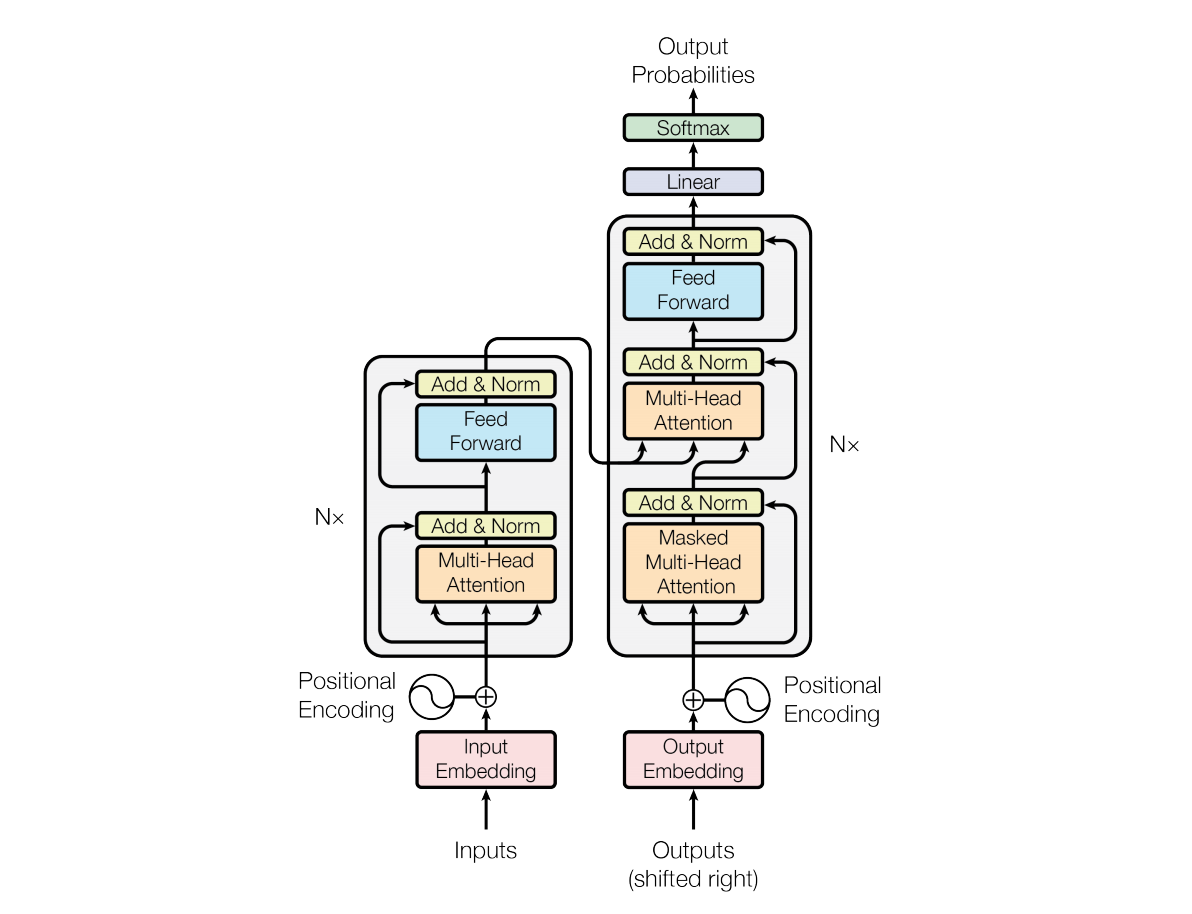
和大多数seq2seq模型一样,transformer的结构也是由encoder和decoder组成。
1.1 Encoder
Encoder由N=6个相同的layer组成,layer指的就是上图左侧的单元,最左边有个“Nx”,这里是x6个。每个Layer由两个sub-layer组成,分别是multi-head self-attention mechanism和fully connected feed-forward network。其中每个sub-layer都加了residual connection和normalisation,因此可以将sub-layer的输出表示为:
sub\_layer\_output = LayerNorm(x+(SubLayer(x))) \\
接下来按顺序解释一下这两个sub-layer:
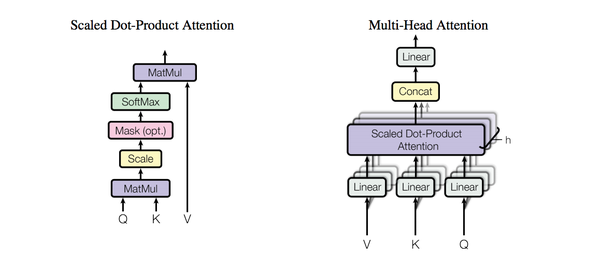
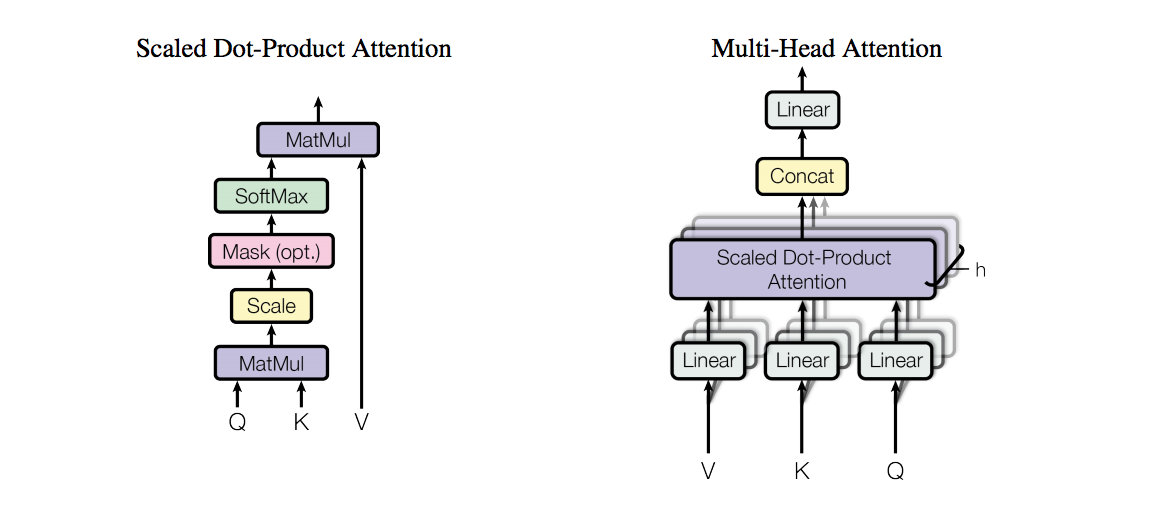
- Multi-head self-attention
熟悉attention原理的童鞋都知道,attention可由以下形式表示:
attention\_output = Attention(Q, K, V) \\
multi-head attention则是通过h个不同的线性变换对Q,K,V进行投影,最后将不同的attention结果拼接起来:
MultiHead(Q, K, V) = Concat(head_1, ..., head_h)W^O \\
head_i = Attention(QW_i^Q, KW_i^K, VW_i^V) \\
self-attention则是取Q,K,V相同。
另外,文章中attention的计算采用了scaled dot-product,即:
Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V \\
作者同样提到了另一种复杂度相似但计算方法additive attention,在 d_k 很小的时候和dot-product结果相似,d_k大的时候,如果不进行缩放则表现更好,但dot-product的计算速度更快,进行缩放后可减少影响(由于softmax使梯度过小,具体可见论文中的引用)。
- Position-wise feed-forward networks
这层主要是提供非线性变换。Attention输出的维度是[bsz*seq_len, num_heads*head_size],第二个sub-layer是个全连接层,之所以是position-wise是因为过线性层时每个位置i的变换参数是一样的。
1.2 Decoder
Decoder和Encoder的结构差不多,但是多了一个attention的sub-layer,这里先明确一下decoder的输入输出和解码过程:
- 输出:对应i位置的输出词的概率分布
- 输入:encoder的输出 & 对应i-1位置decoder的输出。所以中间的attention不是self-attention,它的K,V来自encoder,Q来自上一位置decoder的输出
- 解码:这里要注意一下,训练和预测是不一样的。在训练时,解码是一次全部decode出来,用上一步的ground truth来预测(mask矩阵也会改动,让解码时看不到未来的token);而预测时,因为没有ground truth了,需要一个个预测。
文末附上我总结的BERT面试点&相关模型汇总,还有NLP组队学习群的加群方式~明确了解码过程之后最上面的图就很好懂了,这里主要的不同就是新加的另外要说一下新加的attention多加了一个mask,因为训练时的output都是ground truth,这样可以确保预测第i个位置时不会接触到未来的信息。
加了mask的attention原理如图(另附multi-head attention):
1.3 Positional Encoding
除了主要的Encoder和Decoder,还有数据预处理的部分。Transformer抛弃了RNN,而RNN最大的优点就是在时间序列上对数据的抽象,所以文章中作者提出两种Positional Encoding的方法,将encoding后的数据与embedding数据求和,加入了相对位置信息。
这里作者提到了两种方法:
- 用不同频率的sine和cosine函数直接计算
- 学习出一份positional embedding(参考文献)
经过实验发现两者的结果一样,所以最后选择了第一种方法,公式如下:
PE_{(pos, 2i)} = sin(pos/10000^{2i/d_{model}}) \\
PE_{(pos, 2i+1)} = cos(pos/10000^{2i/d_{model}}) \\
作者提到,方法1的好处有两点:
- 任意位置的 PE_{pos+k} 都可以被 PE_{pos} 的线性函数表示,三角函数特性复习下:
cos(\alpha+\beta) = cos(\alpha)cos(\beta)-sin(\alpha)sin(\beta) \\
sin(\alpha+\beta) = sin(\alpha)cos(\beta) + cos(\alpha)sins(\beta) \\
2. 如果是学习到的positional embedding,(个人认为,没看论文)会像词向量一样受限于词典大小。也就是只能学习到“位置2对应的向量是(1,1,1,2)”这样的表示。所以用三角公式明显不受序列长度的限制,也就是可以对 比所遇到序列的更长的序列 进行表示。
2. 优点
作者主要讲了以下三点:


- Total computational complexity per layer (每层计算复杂度)
2. Amount of computation that can be parallelized, as mesured by the minimum number of sequential operations required
作者用最小的序列化运算来测量可以被并行化的计算。也就是说对于某个序列x_1, x_2, ..., x_n ,self-attention可以直接计算 x_i, x_j 的点乘结果,而rnn就必须按照顺序从 x_1 计算到 x_n
3. Path length between long-range dependencies in the network
这里Path length指的是要计算一个序列长度为n的信息要经过的路径长度。cnn需要增加卷积层数来扩大视野,rnn需要从1到n逐个进行计算,而self-attention只需要一步矩阵计算就可以。所以也可以看出,self-attention可以比rnn更好地解决长时依赖问题。当然如果计算量太大,比如序列长度n>序列维度d这种情况,也可以用窗口限制self-attention的计算数量
4. 另外,从作者在附录中给出的栗子可以看出,self-attention模型更可解释,attention结果的分布表明了该模型学习到了一些语法和语义信息
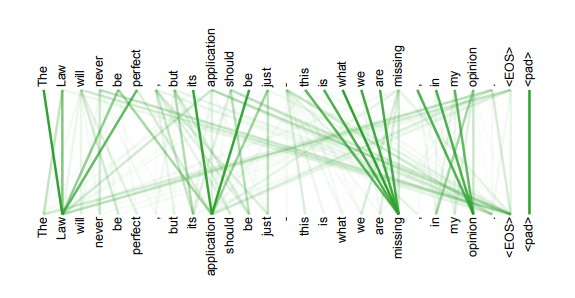

3. 缺点
缺点在原文中没有提到,是后来在Universal Transformers中指出的,在这里加一下吧,主要是两点:
- 实践上:有些rnn轻易可以解决的问题transformer没做到,比如复制string,或者推理时碰到的sequence长度比训练时更长(因为碰到了没见过的position embedding)
- 理论上:transformers非computationally universal(图灵完备),(我认为)因为无法实现“while”循环
4. 总结
Transformer是第一个用纯attention搭建的模型,不仅计算速度更快,在翻译任务上获得了更好的结果,也为后续的BERT模型做了铺垫。
---
欢迎初入NLP领域的小伙伴们加入rumor建立的「NLP卷王养成群」一起学习,添加微信「leerumorrrr」备注知乎+NLP即可,群里的讨论氛围非常好~
---
肝了BERT的面试知识点和相关前沿模型,下面的链接可以直接下载~
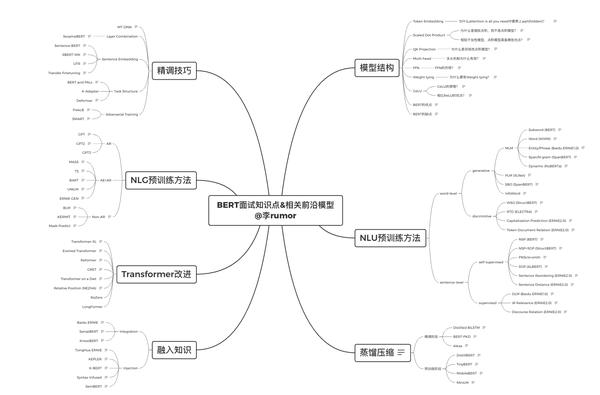

相关阅读:
- 预训练改进
- BERT+生成式
- BERT加速
- 用于特定任务的模型


