
【关于立体视觉的一切】Deep Depth Completion 基于深度学习的深度图补全

前言:
深度图目前应用在很多场景,比如自动避障、活体检测、三维建模等等。但是,当面对光滑/明亮/透明/遥远场景时,深度图往往会存在一些无效点组成的缺失区域。本文介绍的是CVPR2018 的一项最新研究deep depth completion,不受RGB-D相机类型的限制,只需要输入一张RGB加一张depth图,可以补全任意形式深度图的缺失。目前主要针对的是室内环境。
项目主页:http://deepcompletion.cs.princeton.edu/
论文:
Deep Depth Completion of a Single RGB-D Image
作者:Yinda Zhang, Thomas Funkhouser.
会议:Computer Vision and Pattern Recognition (CVPR 2018)[Materials]
代码和数据:
[Git Repository]: https://github.com/yindaz/DeepCompletionRelease
数据创建自公开数据集: SUNCG-RGBD, Matterport3D, and ScanNet.
效果:
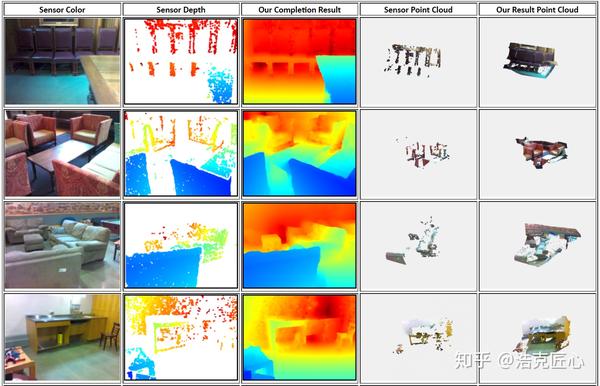

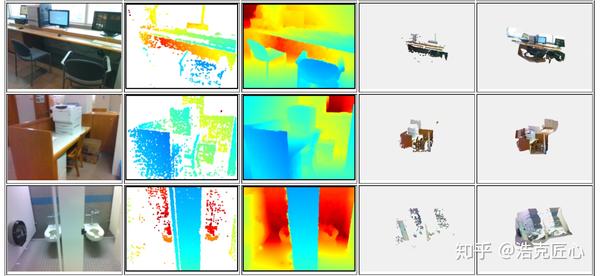

原理:
由于RGB图像和深度图像处是完全不同类型的数据,所以在这之间构筑联系通道是很困难的。举个例子,如果你同样使用深度卷积神经网络,使用像素对齐的RGB和深度图分别作为输入输出,那这个模型是很难拟合,即使你提供再多的训练数据。因为,彩色图获取的是可见光信息,而深度图是距离信息,这两者的跨维度差别是难以找到映射关系的。所以,作者选择的沟通渠道是平面法向量和物体边界,再基于能量函数进行全局优化。
深度图补全主要分两步走:
1.基于RGB图像估计表面法向量和障碍物闭合边界;
2.使用监督学习方法,基于大量表面重建渲染的数据训练出深度模型,来补全深度图像。


表面法向量图N,障碍物边界B,建立一个方程,补全深度图D。目标函数被定义成四项的方差加权求和:
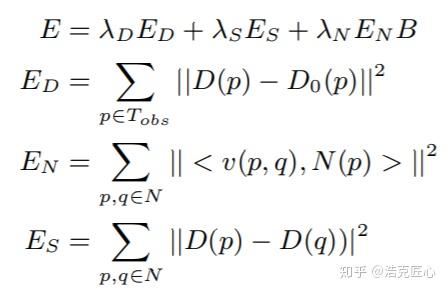
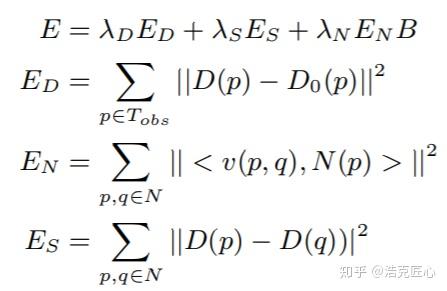
关键的三个问题:
1.how can we get training data for depth completion?
有一些公开数据集比如 Matterport3D , ScanNet , SceneNN, and SUN3D ,本文使用了 Matterport3D.
对于每一个场景,使用基于屏幕空间的泊松曲面重建(screened Poisson surface reconstruction),从全局曲面重建中提取一个包含1~6百万三角形的三角网格M;然后,在场景中对RGB-D图像进行采样,我们从图像视点的摄像机姿态渲染重建的网格M,以获得一个完整的深度图像D。这个过程为我们提供了一套RGB-D->D*图像对,而不需要收集新数据。
这样采集数据集的好处有三:a.同一场景会有不同视角的多张图像数据,便于模型去学习如何填补空洞(一张图里是洞,换个角度就没有了,这样第一张图里也能分享这个事实);b.对于远景有更高的分辨率;c.噪声得到了很好的控制;
2.what geometric representation is best for deep depth completion?
深度图上没做什么特殊处理,就是使用的原始raw color和depth图像;使用上分两步走,先基于每个像素预测可视平面的局部特征,然后基于这些结果预测深度图;
3.what is the best way to train a deep network to predict surface normals and occlusion boundaries for depth completion?
肯定选那个能更好预测表面法向量和物体边界的模型。模型是基于带有对称编解码器的VGG-16的全卷积网络。对应最大池化和非池化层加入了short-cut连接和shared pooling masks,可以更好的学习局部图像特征。训练的时候,加入了基于重建网格计算出来的表面法向量和轮廓边界作为ground truth。
亮点:
- 思路很新。非传统思路。搭建桥梁沟通了彩色图和深度图信息。
2. 效果很好。深度图缺失的补全效果比传统方法更好;文章中对比了联合双边滤波和深度学习深度图估计等方法。
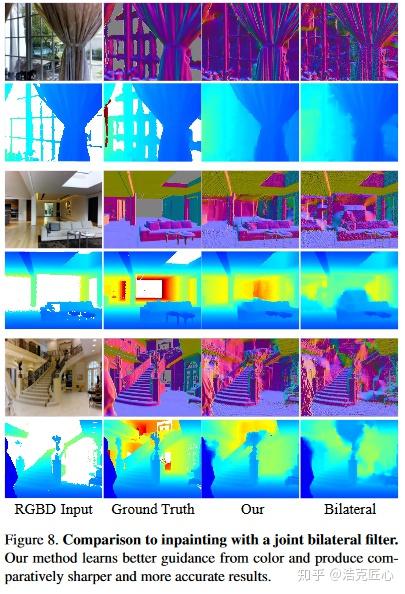
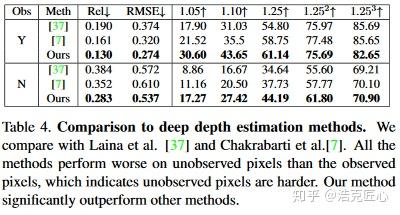
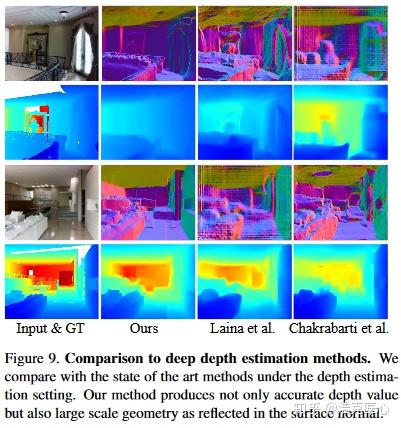
局限:
1.速度很慢。
分辨率320x256的图像,使用NVIDIA TITAN X GPU还需要大约0.3秒;Intel Xeon 2.4GHz CPU上大约1.5秒.
2.依赖高性能硬件。难以控制成本。
总结:
显而易见,这是一个牺牲时间换取图像质量的游戏。增加了彩色图的输入和额外的计算量,深度图质量确实有明显提升,但是以当前的耗时和对高性能硬件的依赖,距离工业化应用还有距离。
对于后处理的应用场景,比如基于多帧的三维重建,这个方法是非常实用的。
对于实时应用场景,比如在避障中使用的话,耗费数秒(甚至数十秒)才能计算出一帧,估计黄花菜都凉了。
当然,这样的方法依然是非常值得探索和研究的。君不见,R-CNN目标检测刚刚出来的时候,也是几十秒一帧的水平,然今日速度已提升了了数百倍。所以,对类似研究可以保持期待。
<完>
更多文章请关注同名微信公共号 BloomCV:计算视觉与深度学习的小屋
相关文章:
