
嵌入式必备:如何学习Linux内核网络协议栈

一,准备工作
对于没有学习过 Linux 内核网络的人来说,可能会对这个它产生向往,也有可能产生恐惧。但当你深入理解并且验证后得到正反馈时,那种豁然开朗的感觉,会让你感到满足,信可乐也。
回想当初自己进入这个主题时,我产生过以下疑问:
Q1:内核网络子系统这么大,我应该从何处开始?会不会栽到里面就晕了?Q2:内核网络代码更新地那么快,应该从哪个版本开始学习?
Q3:有没有什么好的资料,教程?
Q4:如何验证自己的理解是否正确?
那么现在,我可以简单主观回答下:
Q1:内核网络子系统这么大,我应该从何处开始?会不会栽到里面就晕了?
内核网络子系统的代码虽然看着多,但核心流程和旁支还是分离的。并且,我认为它的水平是超过一大票开源代码的。注释的地方够用,炫技的地方寥寥,每一处修改都能从社区 GIT 仓库找到修改的原因,这已经很好了。
Q2:内核网络代码更新地那么快,应该从哪个版本开始学习?
需要哪个版本就用哪个版本。如果工作中指定了版本, 那么就选择它。如果教程书籍中是基于某个版本,那么就选择它。如果只是自己研究,那么我建议预先几个版本的代码:比如 2.6、3.7、4.4、4.9、5.3 (这些版本号是我拍脑袋写的)。
Q3:有没有什么好的资料,教程?
我是没有见到过完整的教程,我觉得可能是内容太多太杂的原因。不过,几乎所有方面互联网上都有相关内容的讨论和分析。这里,推荐以下三本书,讲得都比较全面,本文后面的内容很大程度上也受到了这几本书的影响。
- Understanding linux network internals
- TCP/IP Architecture, Design, and Implementation in Linux
- Linux Kernel Networking: Implementation and Theory
这几本书都有中文译本,不过我觉得还是看英文原版能避免翻译导致理解偏差...
Q4:如何验证自己的理解是否正确?
验证是十分重要的,否则你怎么知道是不是对的呢。除了使用 printk 加调试信息重新编译内核这种原始手段外,有一些更聪明的工具可以帮上忙。
- Systemtap:几乎无所不能,可以在内核放置探测点,然后执行自己的代码。
- kprobe:简单的工具,可以快速检验某个函数是否被执行到
- packetdrill:用于验证 TCP 协议的行为很有用
【文章福利】小编推荐自己的Linux内核技术交流群:【865977150】整理了一些个人觉得比较好的学习书籍、视频资料共享在群文件里面,有需要的可以自行添加哦!!!


内核学习网站:
二,协议栈的细节
下面将介绍一些内核网络协议栈中常常涉及到的概念
sk_buff
内核显然需要一个数据结构来表示报文,这个结构就是 sk_buff ( socket buffer 的简称),它等同于在<TCP/IP详解 卷2>中描述的 BSD 内核中的 mbuf。
sk_buff 结构自身并不存储报文内容,它通过多个指针指向真正的报文内存空间:
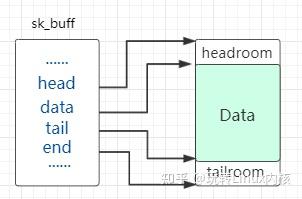
sk_buff 是一个贯穿整个协议栈层次的结构,在各层间传递时,内核只需要调整 sk_buff 中的指针位置就行。

net_device
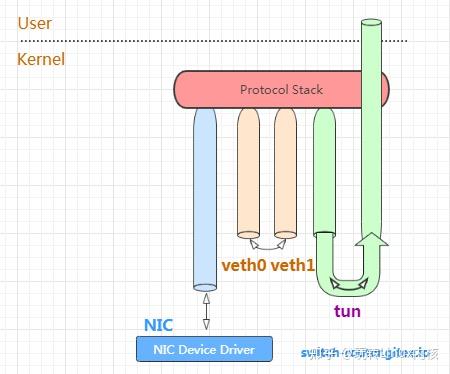
内核使用 net_device 表示网卡。网卡可以分为物理网卡和虚拟网卡。物理网卡是指真正能把报文发出本机的网卡,包括真实物理机的网卡以及VM虚拟机的网卡,而像 tun/tap,vxlan、veth pair 这样的则属于虚拟网卡的范畴。
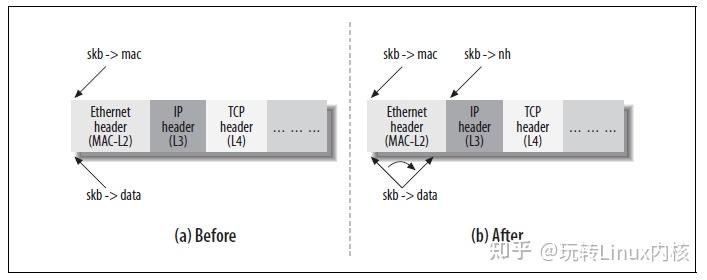
如下图所示,每个网卡都有两端,一端是协议栈(IP、TCP、UDP),另一端则有所区别,对物理网卡来说,这一端是网卡生产厂商提供的设备驱动程序,而对虚拟网卡来说差别就大了,正是由于虚拟网卡的存在,内核才能支持各种隧道封装、容器通信等功能。

socket & sock
用户空间通过 socket()、bind()、listen()、accept() 等库函数进行网络编程。而这里提到的 socket 和 sock 是内核中的两个数据结构,其中 socket 向上面向用户,而 sock 向下面向协议栈。
如下图所示,这两个结构实际上是一一对应的
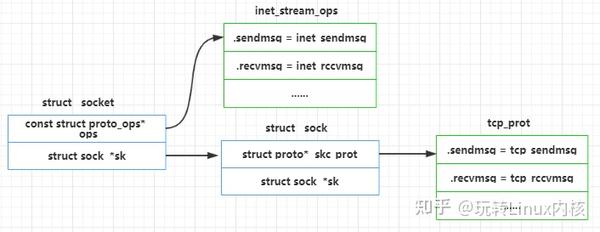

注意到,这两个结构上都有一个叫 ops 的指针, 但它们的类型不同。socket 的 ops 是一个指向 struct proto_ops 的指针,sock 的 ops 是一个指向 struct proto 的指针, 它们在结构被创建时确定
回忆网络编程中 socket() 函数的原型
#include <sys/socket.h>
sockfd = socket(int socket_family, int socket_type, int protocol);
实际上, socket->ops 和 sock->ops 由前两个参数 socket_family 和 socket_type 共同确定。
如果 socket_family 是最常用的 PF_INET 协议簇, 则 socket->ops 和 sock->ops 的取值就记录在 INET 协议开关表中
static struct inet_protosw inetsw_array[] =
{
{
.type = SOCK_STREAM,
.protocol = IPPROTO_TCP,
.prot = &tcp_prot, // 对应 sock->ops
.ops = &inet_stream_ops, // 对应 socket->ops
.flags = INET_PROTOSW_PERMANENT |
INET_PROTOSW_ICSK,
},
{
.type = SOCK_DGRAM,
.protocol = IPPROTO_UDP,
.prot = &udp_prot, // 对应 sock->ops
.ops = &inet_dgram_ops, // 对应 socket->ops
.flags = INET_PROTOSW_PERMANENT,
},
}
.......
L3->L4
我们知道网络协议栈是分层的,但实际上,具体到实现,内核协议栈的分层只是逻辑上的,本质还是函数调用。发送流程(上层调用下层)通常是直接调用(因为没有不确定性,比如TCP知道下面一定IP),但接收过程不一样了,比如报文在 IP 层时,它上面可能是 TCP,也可能是 UDP,或者是 ICMP 等等,所以接收过程使用的是注册-回调机制。
还是以 INET 协议簇为例,注册接口是
int inet_add_protocol(const struct net_protocol *prot, unsigned char protocol);
在内核网络子系统初始化时,L4 层协议(如下面的 TCP 和 UDP)会被注册
static struct net_protocol tcp_protocol = {
......
.handler = tcp_v4_rcv,
......
};
static struct net_protocol udp_protocol = {
.....
.handler = udp_rcv,
.....
};而在IP层,查询过路由后,如果该报文是需要上送本机的,则会根据报文的 L4 协议,送给不同的 L4 处理
static int ip_local_deliver_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
......
ipprot = rcu_dereference(inet_protos[protocol]);
......
ret = ipprot->handler(skb);
......
}L2->L3
L2->L3 如出一辙。只不过注册接口变成了
void dev_add_pack(struct packet_type *pt)谁会注册呢? 显然至少 IP 会
static struct packet_type ip_packet_type = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
}
而在报文接收过程中,设备驱动程序会将报文的 L3 类型设置到 skb->protocol,然后在内核 netif_receive_skb 收包时,会根据这个 protocol 调用不同的回调函数
__netif_receive_skb(struct sk_buff *skb)
{
......
type = skb->protocol;
......
ret = pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
}
Netfilter
Netfilter 是报文在内核协议栈必然会通过的路径,我们从下面这张图就可以看到,Netfilter 在内核的 5 个地方设置了 HOOK 点,用户可以通过配置 iptables 规则,在 HOOK 点对报文进行过滤、修改等操作。
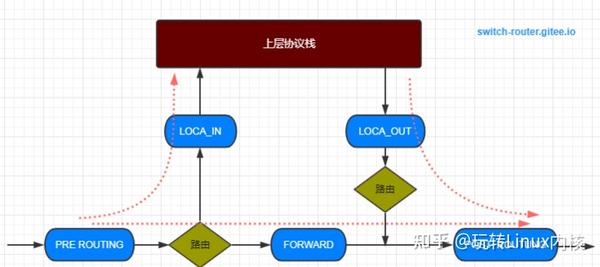

在内核代码中,我们时常可一件 NF_HOOK 这样的调用。我的建议是,如果你暂时不考虑 Netfilter,那么就直接跳过, 跟踪 okfn 就行。
static inline int
NF_HOOK(uint8_t pf, unsigned int hook, struct net *net, struct sock *sk, struct sk_buff *skb,
struct net_device *in, struct net_device *out,
int (*okfn)(struct net *, struct sock *, struct sk_buff *))
{
int ret = nf_hook(pf, hook, net, sk, skb, in, out, okfn);
if (ret == 1)
ret = okfn(net, sk, skb);
return ret;
}
dst_entry
内核需要确定收到的报文是应该本地上送(local deliver)还是转发(forward),对本机发送(local out)的报文需要确定是从哪个网卡发送出去,这都是内核通过查询 fib (forward information base, 转发信息表) 确定。fib 可以理解为一个数据库,数据来源是用户配置或者内核自动生成的路由。
fib 查询的输入是报文 sk_buff,输出是 dst_entry. dst_entry 会被设置到 skb 上
static inline void skb_dst_set(struct sk_buff *skb, struct dst_entry *dst)
{
skb->_skb_refdst = (unsigned long)dst;
}
而 dst_entry 中最重要的是一个 input 指针和 output 指针
struct dst_entry {
......
int (*input)(struct sk_buff *);
int (*output)(struct net *net, struct sock *sk, struct sk_buff *skb);
......
}
- 对于需要本机上送的报文rth->dst.input = ip_local_deliver;
- 对需要转发的报文rth->dst.input = ip_forward;
- 对本机发送的报文rth->dst.output = ip_output;


