
旋转目标检测方法解读(KFIoU, ICLR2023)


1. 前言
新年第一卷,先祝大家元宵节快乐,paper++!
arXiv:
TensorFlow code:
PyTorch code:
Jittor code:
2. 动机
在通用检测中,IoU损失一直是备受欢迎的,它可以有效对齐当前评估(IoU主导)和回归损失( L_{n} 损失)的不一致性。由于旋转IoU(SkewIoU)损失在当前开源框架中并没有被支持,且用现有的算子实现比较困难,因此SkewIoU损失在该领域中被没有被广泛使用。
下面是开源社区中相关的SkewIoU损失算子的实现:
convex_iou: https://github.com/open-mmlab/mmcv/blob/master/mmcv/ops/convex_iou.py
rotated_iou: https://github.com/csuhan/s2anet/blob/master/configs/rotated_iou
也有一些工作研究如何近似的SkewIoU损失,比如PIoU、projection IoU、GWD、KLD等。值得注意的是,GWD和KLD引入了高斯建模,使得检测器能免疫边界不连续等问题。但是它们本质上不是SkewIoU损失,这是因为它们的计算并不是按照SkewIoU的计算过程得到的,而是使用了高斯分布距离度量,所以在最终损失函数的设计上引入了非线性变换以及超参数。
此次工作的目的是设计一个简单且更高效的SkewIoU近似损失,目标如下:
- 可以通过当前深度学习框架现有的算子轻松实现
- 不引入额外超参数,不需要额外调参
- 效果比朴素的SkewIoU、GWD、KLD等损失更好
3. 方法
由于设计的是损失函数,因此我们并不需要严格实现精确的SkewIoU计算。这是显然的结论,如 y=\left| x \right| 和 y=\left| x \right|+b 作为损失函数来说是等效的。因此我们只需要实现一个和朴素SkewIoU损失具有高度一致性的损失函数就行了,也就是文中提到的保证trend-level consistency而不需要value-level consistency,这一个发现其实大大简化了设计的难度。理想的trend-level consistency是设计的损失函数和理想的损失函数之间的差值是一个常数。为有效衡量损失函数之间的trend-level consistency,我们设计了一个损失函数的误差方差(error variance, EVar),公式如下:
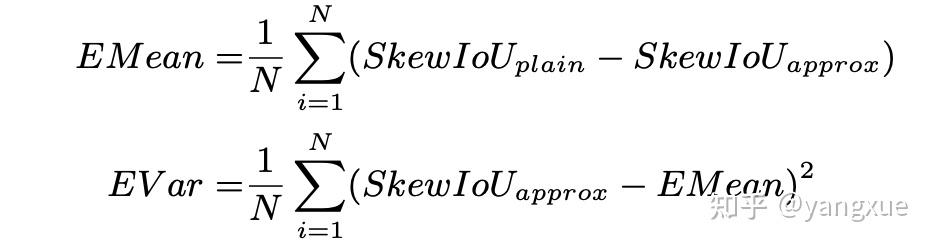

我们可以比较一下L1、GWD、KLD与plain SkewIoU损失之间的误差方差:
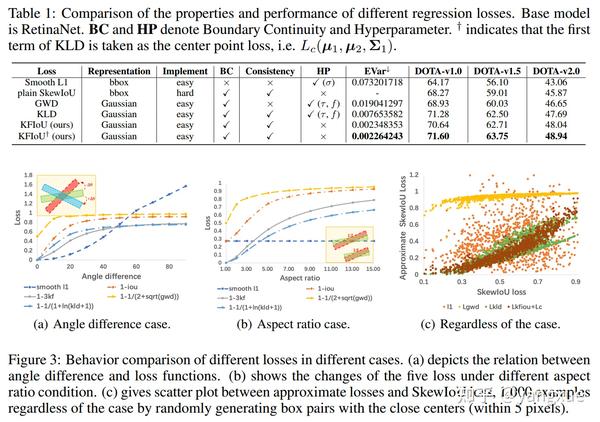

如果仅关注误差方差和性能的话,我们可以发现误差方差越小,性能趋向于越好。这一个发现也很好佐证了我们上面的发现:保证trend-level consistency而不需要value-level consistency。
吸取了GWD和KLD在近似SkewIoU路上的经验教训,此次我们依然采用高斯建模的方式,但不再通过分布距离度量来构建新的损失函数而是想通过高斯分布模拟SkewIoU的计算过程,具体步骤如下图:


- 将两个旋转矩形框转换成高斯分布;
- 引入中心点损失拉近使得两个分布同中心(需要这个步骤的原因会在后面分析);
- 通过两个高斯相乘的到相交区域的高斯分布;
- 将三个高斯分布反转换成旋转矩形,计算近似的SkewIoU
很显然整个过程是按照SkewIoU(交/并)的计算过程进行的,但是计算出来的结果肯定不是精确的SkewIoU,上面分析过,精确的SkewIoU这个并不重要。这里需要解释一下为什么最后取名KFIoU(Kalman filtering IoU),主要是因为卡尔曼滤波中同样应用到了高斯分布相乘,我也是通过这个想到通过相乘后的高斯分布来计算相交区域的面积,从而达到近似SkewIoU的目的,参考资料如下:
因为核心是高斯相乘,所以取名Kalman filtering有点草率,但我确实是从Kalman filtering中受到的启发,就当致敬一下。当然也不是不可以强行解释一波:我们将预测框、真实框和重叠区域分别建模为预测值、观察值和不确定性。由于卡尔曼滤波中的预测值、观察值都不是确定的,所以需要迭代的过程,而旋转检测中的预测框、真实框是确定的,所以就不需要迭代过程了。当然,卡尔曼滤波我自己是一知半解的,并没有深入研究,上面的解释在行家眼里可能就是瞎扯,大家就随意看看就行了。
回到正题,我们来更详细地解释上述过程。首先,我们可以通过高斯分布计算出其对应旋转矩形框的面积,其实就是协方差特征值累乘(协方差特征值对应旋转矩形的两条边),公式如下:
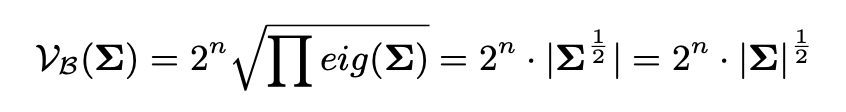

要计算SkewIoU,得到相交区域的面积才是关键。如果我们将相交区域也近似成一个高斯分布的话,就可以通过上面的公式计算相交区域面积了。而这个高斯分布则可以通过当前两个高斯分布的乘积的到,公式如下:
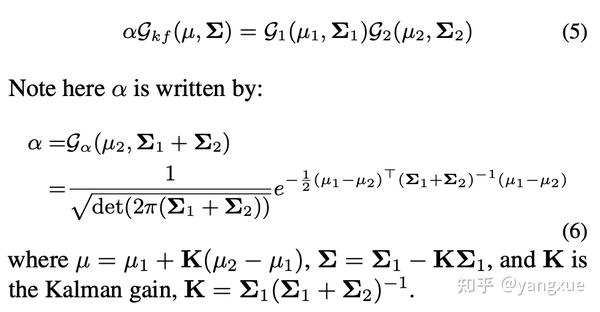

得到新的高斯分布之后,我们不忙着急用它来计算相交区域面积。先仔细观察一下新高斯分布的协方差,该协方差只和相乘的两个高斯的协方差有关,也就意味着无论两个高斯分布如何移动,只要它们的协方差固定,计算出来的面积就不会改变。这显然不符合直觉:当两个高斯分布相距较远时,应该重叠区域面积应该减少。造成这个现象的原因是得到的新高斯分布并不是一个标准的高斯分布,它的前面有一个系数 \alpha ,这个系数则与中心点的距离有关。因此,如果我们要计算相交面积,是需要同时考虑这个系数。根据上述发现,我们引入了中心点损失使得两个高斯分布同中心,这样系数 \alpha 就可以近似成一个常数,从而不需要考虑了。另外,中心点损失的引入也会使得整个损失可以优化没有相交的情况,这个是SkewIoU损失无法做到的,也是当前GIoU等变种损失所考虑到的。最后计算KFIoU的公式如下:


我们在文中附件部分证明了KFIoU的取值范围,在n维下,值域是 0\leq KFIoU \leq \frac{1}{2^{\frac{n}{2}+1}-1} 。在二维检测任务中,取值范围是[0, \frac{1}{3} ]。我们可以轻松将KFIoU的值域拉升到[0, 1]和SkewIoU保持一致,但这个操作并不是必要的,因为我们的目标是trend-level consistency。通过计算,KFIoU损失的EVar是最小的,而性能也几乎都是最好的,进一步证明了维持trend-level consistency的正确性。我们再来逐个分析我们最开始的目标:
- \checkmark可以通过当前深度学习框架现有的算子轻松实现:高斯分布转换、矩阵计算都有现成的算子。
- \checkmark不引入额外超参数,不需要额外调参:由于KFIoU就是模拟的IoU的计算过程(交/并),因此不需要超参数。
- \checkmark效果比朴素的SkewIoU损失更好:可以优化非相交情况;计算完全可导;高斯建模的优势。
补充:
为了在性能上超越KLD,我们对中心点损失也做了实验,默认使用的是Faster RCNN中采用的形式,缺点在于不具备尺度不变性以及没有像KLD那样较好的中心点优化机制,因此为了公平地和KLD比较,我们将KLD中的中心点损失项拿过来直接使用
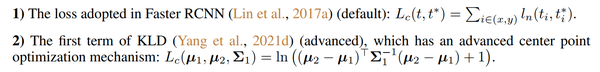

通过实验发现性能得到了进一步提升,如表1、表2和表4所示。
4. 实验
2D数据集下的消融实验:
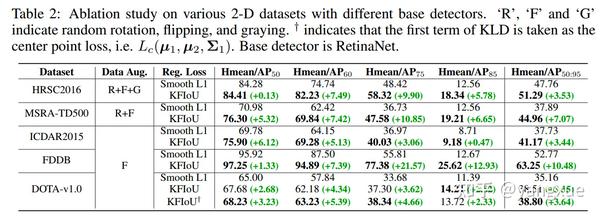

3D数据集下的消融实验:


不同检测器下的消融实验:
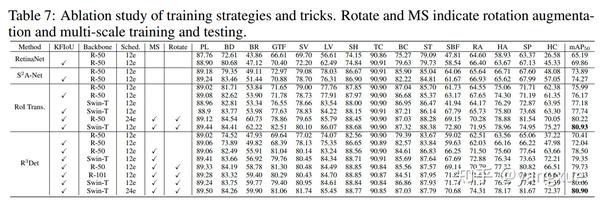

同行方法对比实验:
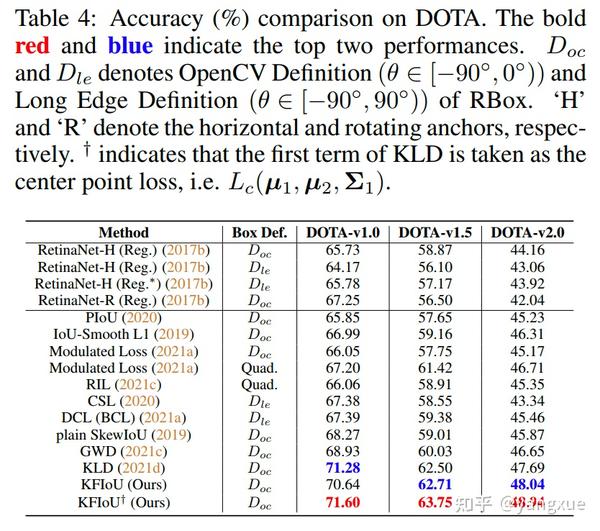

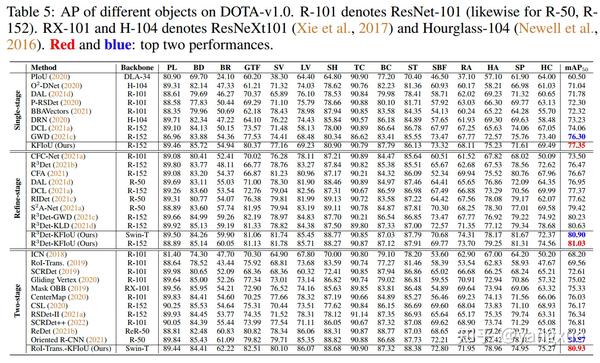
SOTA实验:

5. 总结
这篇是我在高斯建模的第三个工作,目前还是都是局限于旋转矩形检测,后面有机会我们会介绍一下如何将高斯建模思想迁移到四边形甚至是基于点集的目标检测方法。文章还有一个贡献是将高斯建模用到了3D目标检测,有一定的效果,但有几个问题需要考虑:1)行人类接近于正方形,此时高斯分布就是圆形了,不利于高精度检测尤其是对于行人方向的预测;2)3D检测数据集的评估指标并不都是以IoU主导的,所以KFIoU的有效性也会被削弱。


