
3 种方法实现逻辑回归多分类

逻辑回归分类器(Logistic Regression Classifier)是机器学习领域著名的分类模型。其常用于解决二分类(Binary Classification)问题。
但是在工作/学习/项目中,我们经常要解决多分类(Multiclass Classification)问题。
为方便各位求职者在积累项目经验时使用,本文总结了 3 种扩展逻辑回归使其成为多分类器的方法。
One-Vs-All
假设我们要解决一个分类问题,该分类问题有三个类别,分别用△,□和×表示,每个实例(Entity)有两个属性(Attribute),如果把属性 1 作为 X 轴,属性 2 作为 Y 轴,训练集(Training Dataset)的分布可以表示为下图:
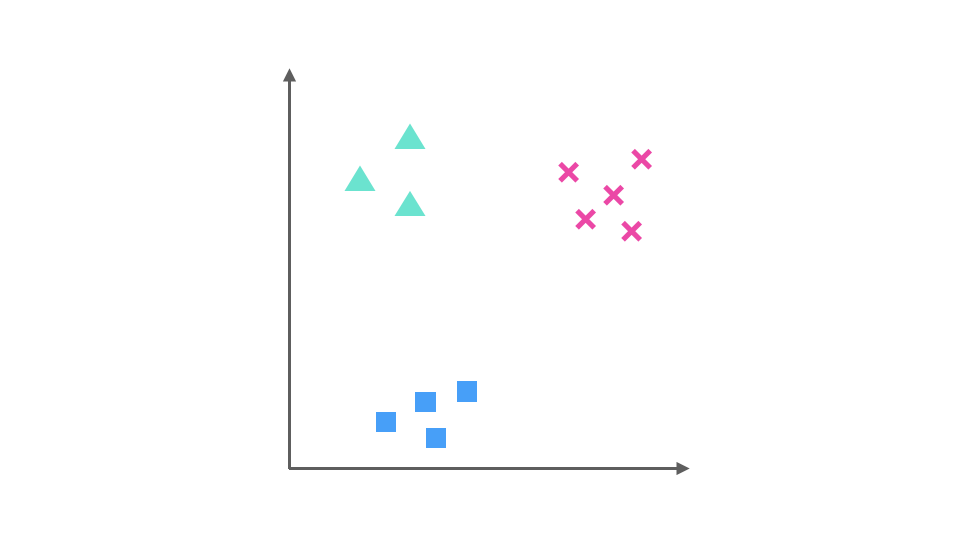
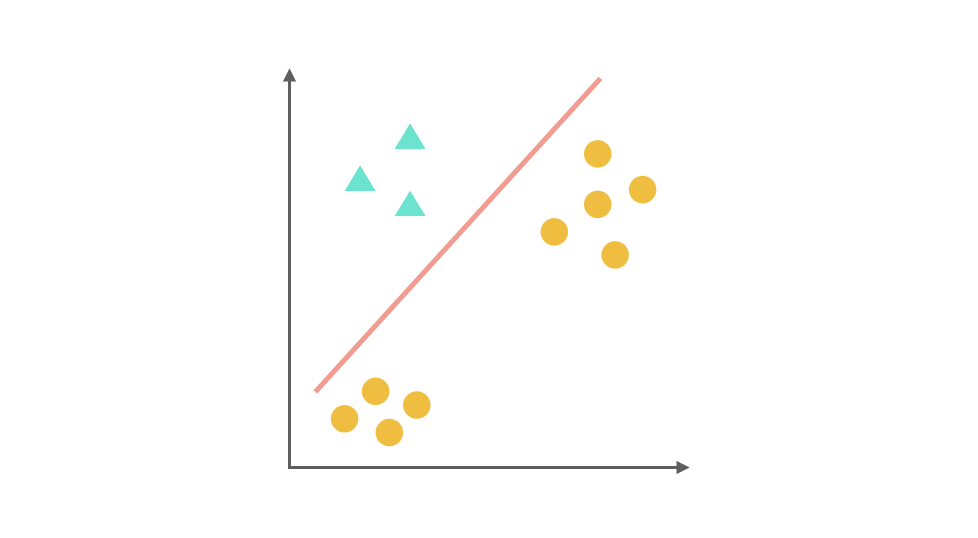
One-Vs-All(或者叫 One-Vs-Rest)的思想是把一个多分类的问题变成多个二分类的问题。转变的思路就如同方法名称描述的那样,选择其中一个类别为正类(Positive),使其他所有类别为负类(Negative)。比如第一步,我们可以将三角形所代表的实例全部视为正类,其他实例全部视为负类,得到的分类器如图:

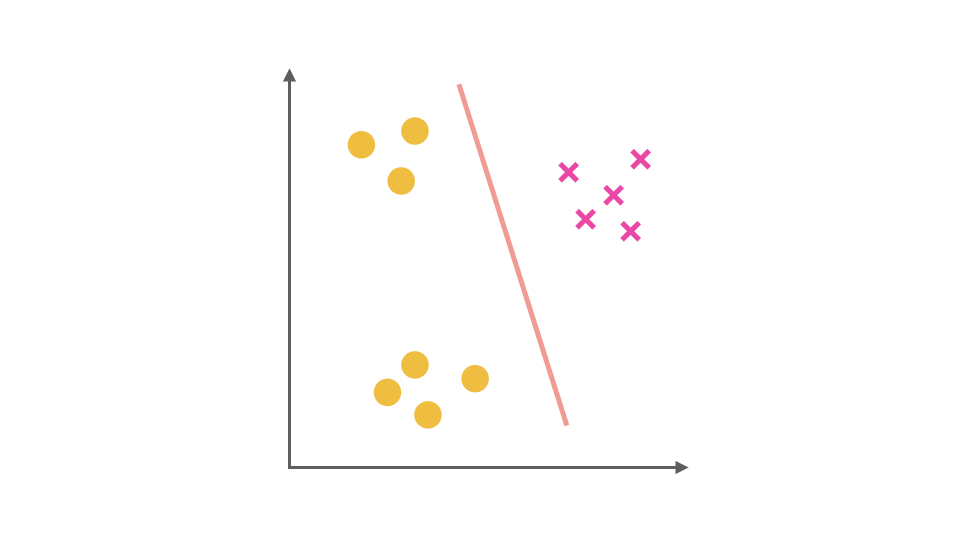
同理我们把 X 视为正类,其他视为负类,可以得到第二个分类器:

最后,第三个分类器是把正方形视为正类,其余视为负类:
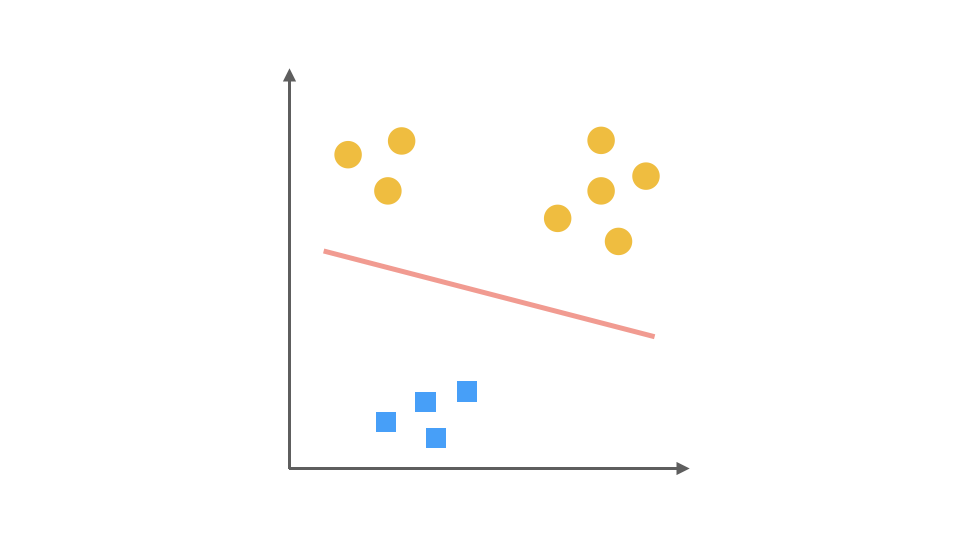

对于一个三分类问题,我们最终得到 3 个二元分类器。在预测阶段,每个分类器可以根据测试样本,得到当前正类的概率。即 P(y = i | x; θ),i = 1, 2, 3。选择计算结果最高的分类器,其正类就可以作为预测结果。
One-Vs-All 最为一种常用的二分类拓展方法,其优缺点也十分明显。
优点:普适性还比较广,可以应用于能输出值或者概率的分类器,同时效率相对较好,有多少个类别就训练多少个分类器。
缺点:很容易造成训练集样本数量的不平衡(Unbalance),尤其在类别较多的情况下,经常容易出现正类样本的数量远远不及负类样本的数量,这样就会造成分类器的偏向性。
One-Vs-One
相比于 One-Vs-All 由于样本数量可能的偏向性带来的不稳定性,One-Vs-One 是一种相对稳健的扩展方法。对于同样的三分类问题,我们像举行车轮作战一样让不同类别的数据两两组合训练分类器,可以得到 3 个二元分类器。
它们分别是三角形与 x 训练得出的分类器:
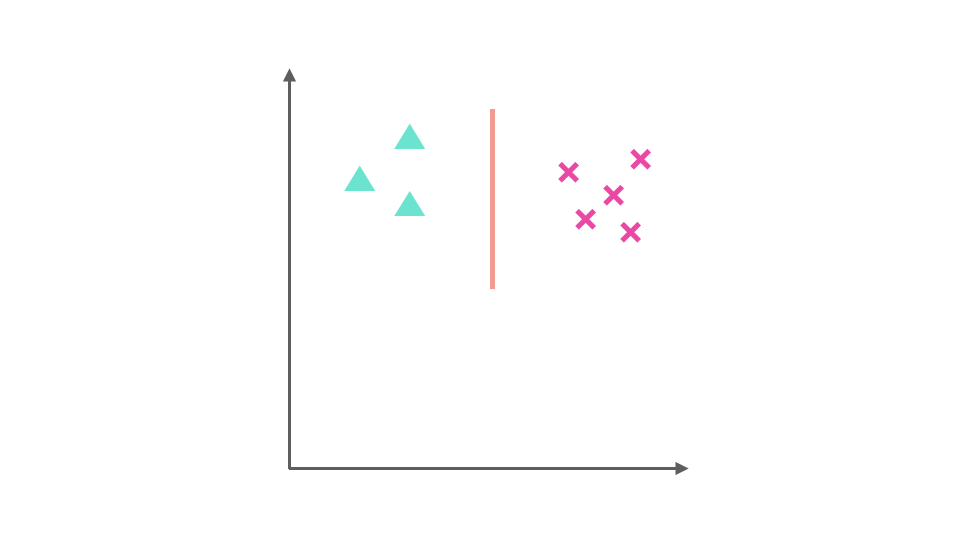

三角形与正方形训练的出的分类器:
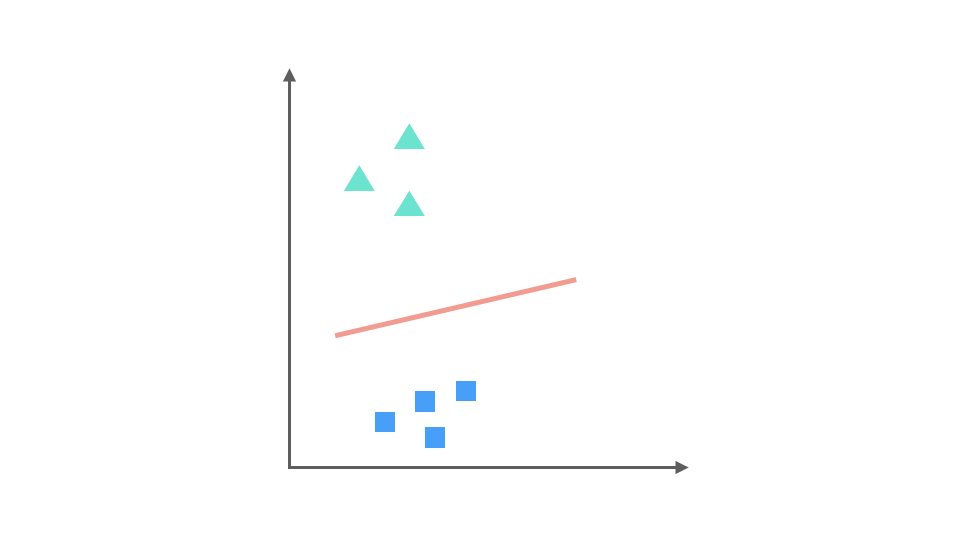

以及正方形与 x 训练得出的分类器:
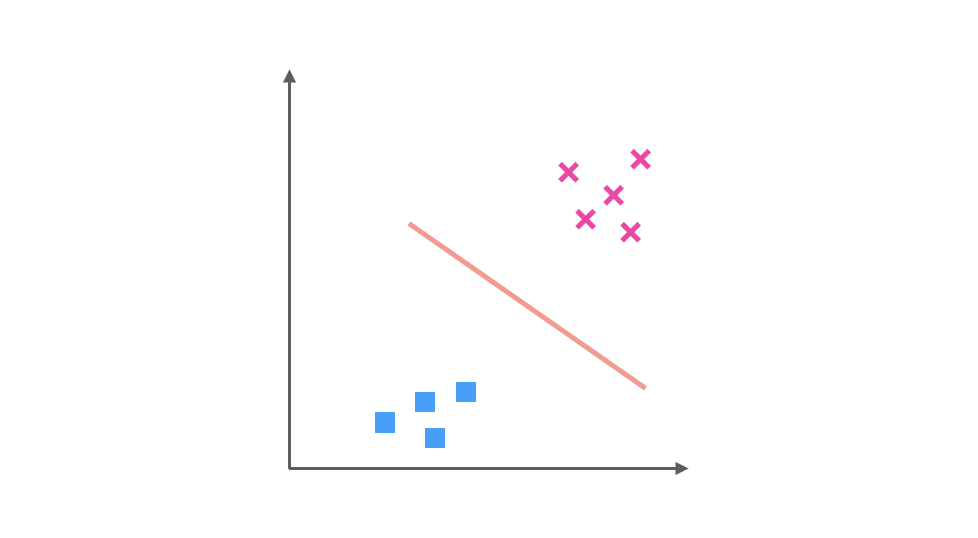

假如我们要预测的一个数据在图中红色圆圈的位置,那么第一个分类器会认为它是 x,第二个分类器会认为它偏向三角形,第三个分类器会认为它是 x,经过三个分类器的投票之后,可以预测红色圆圈所代表的数据的类别为 x。
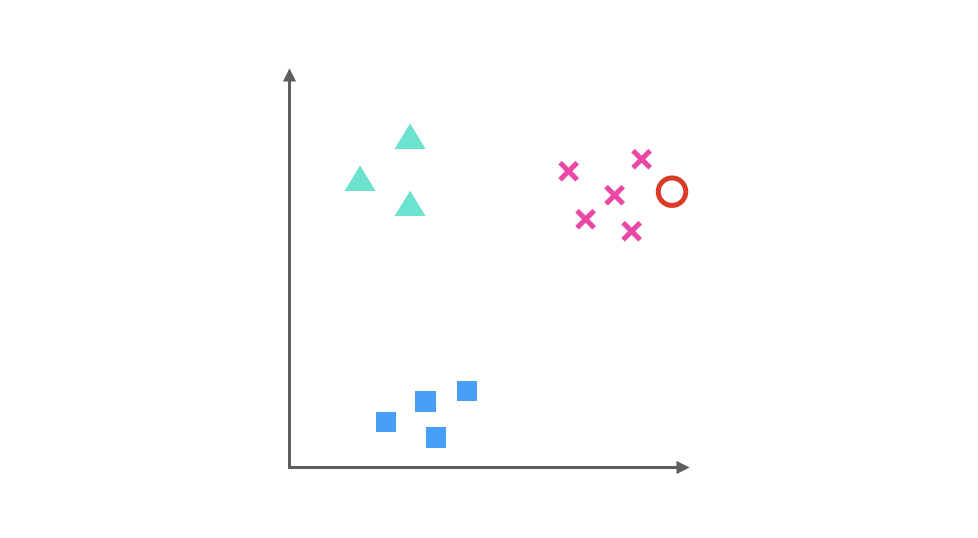

任何一个测试样本都可以通过分类器的投票选举出预测结果,这就是 One-Vs-One 的运行方式。
当然这一方法也有显著的优缺点,其缺点是训练出更多的 Classifier,会影响预测时间。
虽然在本文的例子中,One-Vs-All 和 One-Vs-One 都得到三个分类器,但实际上仔细思考就会发现,如果有 k 个不同的类别,对于 One-Vs-All 来说,一共只需要训练 k 个分类器,而 One-Vs-One 则需训练 C(k, 2) 个分类器,只是因为在本例种,k = 3 时恰好两个值相等,一旦 k 值增多,One-Vs-One 需要训练的分类器数量会大大增多。
当然 One-Vs-One 的优点也很明显,它在一定程度上规避了数据集 unbalance 的情况,性能相对稳定,并且需要训练的模型数虽然增多,但是每次训练时训练集的数量都降低很多,其训练效率会提高。
Softmax
在二元的逻辑回归模型中,我们用 Sigmoid 函数将一个多维数据(一个样本)映射到一个 0 - 1 之间的数值上,有没有什么方法从数学上让一个样本映射到多个 0 - 1 之间的数值呢?答案是通过 Softmax 函数。
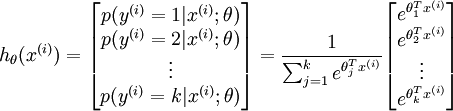

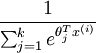
使所有概率之和为 1,是对概率分布进行归一化。
为什么选用指数函数呢?有一些简单的理由 [2]:
- 指数函数简单,并且是非线性的
- 该函数严格递增
- 这是一个凸函数
定义了新的假设函数(hypothesis function)之后,我们要得到其对应的代价函数(cost function)。
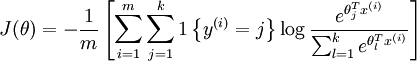
其中 1\left\{ \cdot \right\} 的取值规则为大括号内的表达式值为真时,取 1,为假时取 0。
对该代价函数求最优解同样可以使用如梯度下降之类的迭代算法,其梯度公式如下:
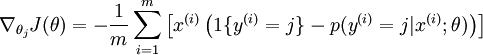

有了偏导数,就可以对代价函数进行优化,最终求解。
本质上讲,Softmax 回归就是 logistic 回归进行多分类时的一种数学拓展,如果让分类数为 2 带入 softmax 回归,会发现其本质上和 logistic 回归是一样的。
在处理一些样本可能丛属多个类别的分类问题是,使用 one vs one 或 one vs all 有可能达到更好的效果。
Softmax 回归适合处理一个样本尽可能属于一种类别的多分类问题。
Reference
- http://ufldl.stanford.edu/wiki/index.php/Softmax_Regression
- https://houxianxu.github.io/2015/04/23/logistic-softmax-regression/
- http://mlwiki.org/index.php/One-vs-All_Classification
- 台湾大学《机器学习基石》
作者:宫业奇
