
SVM 与 LR 的对比

首先在进行对比之前,我们必须得搞清楚几个概念: 高维映射,核方法,参数化方法,非参数化方法。
我看了很多网上的讨论,绝大多数人都没有彻底理清楚这几个概念,以及它们之间的联系。所以很多争论,甚至很多人在争论的根本不是同一个问题。
一、高维映射
首先解释下高维映射,它是一个解决非线性问题的一种通用手段,通常记作 \phi(\bm{x}) 。
对于如下问题,我们是找不出来一个 \bm{w}^T\bm{x} + b = 0 ,让它能分割开两个数据集的。任何不做高维映射的线性分类器,都无法解决这个问题。
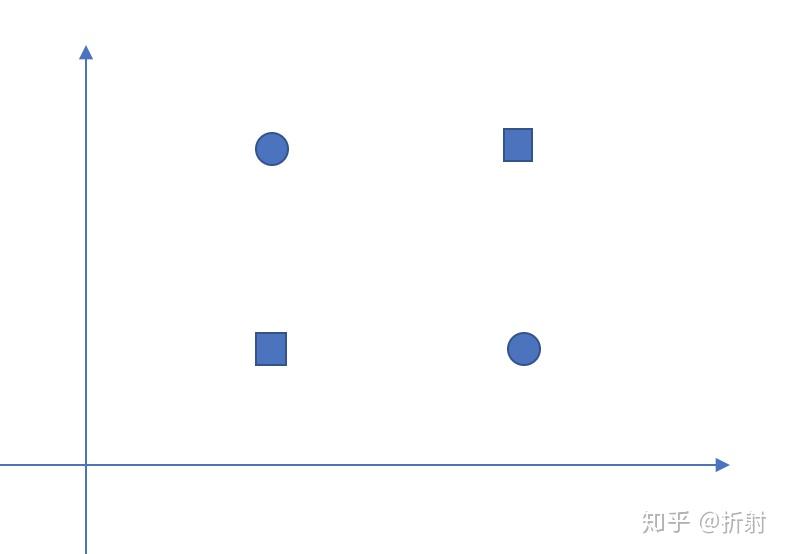

一旦做了高维映射,我们就能在平面上产生曲线。注意,高维映射不是SVM专属的,高维映射是对于输入样本 \bm{x} 的一个变换。理论上任何分类器,只要有输入样本,它都能做高维映射。包括逻辑回归分类器,感知机,神经网络等等。


大家肯定经常看到这个画一个红线,这其实描述的是高维映射的过程,并不是SVM的过程。这条红线其实就是方程 \bm{w}^T\phi{(\bm{x})} + b = 0 。那我们把这条直线作为逻辑回归所确定的直线,自然也是可以的。
映射其实就是选多个特征进行组合。我来举一个例子,一个样本有3个维度 [x_1,x_2,x_3] 我们每次选取其中的两个维度进行组合,一共有 \{x_1x_1,x_2x_2,x_3x_3 , x_1x_2,x_1x_3,x_2x_3\} 六种组合形式。
其实在训练模型的时候,大部分人都会去做的一个工作,叫做特征组合。为了构造新的特征,从而提升效果。其实做特征组合,它的本质就是对样本进行高维映射。比如,把长度属性乘宽度属性可以得到面积属性。
二、核方法
高维映射存在一个问题, \phi(\bm{x}) 的计算量大。你想想,每个特征就算只做两两组合,复杂度起码也得是 O(n^2) 的,那1000个维度的特征,就得做100W次计算。跟何况还要3个组合,4个组合,多个组合。
就算给你一个完美的超平面: \bm{w}^T\phi{(\bm{x})} + b = 0 ,也就是说有个上帝过来告诉你理想的 \bm{w},b 的值。你要去预测一个样本也是不容易的。因为这个公式里面算 \phi(\bm{x}) 的复杂度就不可接受了。
核方法是一种技巧,它可以避免计算 \phi(\bm{x}) 。
核方法也是可以用在任何做了高维映射的分类器上的。通常它是把 \bm{w}^T 变成一个 \sum_m\alpha_m \phi^T(\bm{x}_m) 的形式。这里的 \bm{x}_m 其实是我们的训练样本。
\bm{w}^T\phi{(\bm{x})} = \sum_m\alpha_m \phi^T(\bm{x}_m)\phi{(\bm{x})} ,两个在一起的高维映射可以替换成核函数。
这样我们不需要做高维映射了。
具体核方法介绍参见:
三、参数化方法跟非参数化方法
注意,核方法其实是通过训练样本来代替计算高维映射。一旦用了核方法,模型就会从参数化方法模型变成非参数化方法模型。
参数化方法有什么好处呢?我们只需要确定参数,模型就定了。也就是说,我们只需要保存参数,不需要保存训练样本。
非参数化方法,就是用训练样本的值来做预测。也就是说,我们得将所有的训练样本保存下来,才能做预测。
核方法虽然绕开了做高维映射,但是带来的坏处是,我们得保存下所有的训练样本,才能预测别的数据。
SVM叫做支持向量机,那这个支持向量是什么意思呢?支持向量,只有在非参数化方法中才有存在的意义。也就是说我们说的SVM是默认做了高维映射加核方法的。本来用完核方法以后,我们得用到全部训练样本,来对一个新样本做做预测。现在由于SVM的特殊性,很多训练样本对预测不起作用,只需要一部分特殊的训练样本来做预测了。这部分特殊的训练样本就叫做,支持向量。
四、 SVM 与 LR 的概念
下表列出了各种情况所对应的损失函数。如果你看懂了这个表,很多问题就会迎刃而解了。


在应用中,我们所说的SVM,都是做过高维映射再加上核方法的SVM,因为只有非参数方法支持向量才有存在的意义。


而我们常用的逻辑回归LR,通常是不做高维映射的。这并不代表LR不能做高维映射,我在高维映射里面中说过,任何有输入的模型,都能做高维映射。也就是说,LR也可以做高维映射,那么照样也可以用核方法。
高维映射显然可以提高模型的拟合能力,也就是准确度。理论上做完高维映射以后的LR,准确度应该是跟SVM会是一样的。
那我们为什么不把LR也高维映射一下呢,别忘了,做高维映射是有代价的,计算高维映射的过程太费时间了。你可能会说,我们不是还有核方法吗?对啊,确实可以用核方法避开高维映射计算,那对应也是有代价的,我们得保存下来所有训练样本。保存所有训练样本对于样本过大的时候,LR几乎是不可接受的。SVM强就强在,它根本不需要保存所有训练样本,只要保存一小部分叫做支持向量的样本。

五、SVM 跟 LR 的对比
下面是Andrew NG大佬的课件,我们来深入理解一下。


总结一下就是:
1. 如果Feature的数量很大,跟样本数量差不多,选用LR或者是Linear Kernel的SVM。
2. 如果Feature的数量比较小,样本数量一般,不算大也不算小,选用SVM+Gaussian Kernel
3. 如果Feature的数量比较小,而样本数量很多,需要手工添加一些feature变成第一种情况
在什么情况下,我们需要做高维映射呢?我们之所以要做映射,就是因为特征数量不够多。如果特征数量多,那么用现有的特征就足够了。所以情况(1)的时候,我们特征数量多。并不需要映射。
但是,这也不是绝对的,想象一种极端情况,假设特征之间是线性相关的,每个特征是第一个特征的X倍,那么就算你有10000个特征,其实本质上也只有1个特征。这时候,仍然需要做高维映射。
总之,做了高维映射一定比不做准确率要高,但是效率显然也会变低。一旦做完高维映射,再用上核方法以后,我们就需要保存所有训练数据了(SVM只要保存部分)。如果需要保存的数据量在可以接受的范围内,那么我们能做高维映射,就做高维映射,可以增加准确率,何乐而不为。
对于大数据集,还没有大到那种程度的,SVM显然更好(有高维映射就是牛B)。
对于超级超级超级大的数据集,用SVM肯定巨慢,因为这时候支持向量数量也肯定很多,复杂度肯定跟支持向量的数量有关。这时候显然只能用LR。它是一个参数化的方法,我们只需要保存两个向量参数 \bm{w},b ,预测的复杂度甚至是 O(n) ,其中n代表数据的维度。
六、做几道练习题
如果你真的懂了,我相信你能找出这个问题里面各位答主所犯的错误:
