
卡方检验:离散变量的关联性分析

目录:
- 前言
- 卡方检验定义
- 什么是 \chi^2 (具体原理)
- 两个离散变量的关联性分析
前言:
前面两篇文章谈到了
分别是两变量和多变量的线性相关性的检验,
注意:这里的两变量 X,Y 和多变量 X_1···X_n 要求的都是连续变量
万一遇到了不是连续变量,而是两个离散变量的该如何判断其是否相关呢?
这里简单聊聊啥是离散变量,例如常见的性别,学历等等
这就要用到卡方检验了
卡方检验 \chi^2
卡方检验是一种计数资料的假设检验方法。属于非参数检验的范畴,
主要是比较两个及两个以上样本率(构成比)以及两个二值型离散变量的关联性分析。
其根本思想就是在于比较理论频数和实际频数的吻合程度或拟合优度问题。
用通俗的话来分析一下它的定义:
- \chi^2 检验是非参数检验,就是我们根本不知道分类变量的分布。
- 比较理论频数和实际频数的吻合程度
其实就是独立性检验的反向检验,如果不独立,那肯定有关联
这里用的是Pearson \chi^2 检验
举个热身的例子:
我要检验一个骰子是否均匀
- 假设每个面出现的概率为 \frac{1}{6}
- 设计实验:投骰子 n 次,记录每个面出现的次数 c_1···c_6 ,用 \frac{c_i}{n}(i=1,...,6) 求出每个面频率 p_1...p_6
- 用 p_1...p_6 与 \frac{1}{6} 比较,如果各个面的频率与 \frac{1}{6} 相差不大,说明骰子是均匀的,如果每个面频率与 \frac{1}{6} 相差很大,说明骰子是不均匀的
原理:就是比较理论频数 \frac{1}{6} 与实际频数 p_1...p_6 的吻合程度
什么是卡方 \chi^2 ?
\chi^2 衡量观察值与理论值之间的偏离程度
还是拿"检验一个骰子是否均匀"作为例子
设总体 X 可以分成 r 类
可以分成 6 类
记为 A_1,A_2,...,A_r
这里就是骰子出现的点数 1,2,...,6
要检验的假设为: H_0:P(A_i)=p_i i=1,2,...,r
对应的 H_0:P(X=i)=\frac{1}{6} i=1,2,...,6 ,p_i 不一定为同一个数,可设出现 1 点概率为 \frac{1}{2} ,出现 2 点概率为 \frac{1}{3} 等等
现在对总体作了 n 次观测,各类出现的频数分别为 n_1,...,n_r 且 \Sigma_{i=1}^rn_i=n
投骰子 100000 次,
用 R语言 来模拟一下(不严谨,请轻喷)
# 生成1到6的随机数
# sample()就是有放回抽样
> X <- sample(1:6, size = 100000, replace = T)
> head(X)
[1] 6 3 1 5 1 6
> tail(X)
[1] 1 2 6 3 5 3
# 计算出各个值的频数
> count_table <- table(X)
> count_table
X
1 2 3 4 5 6
16619 16572 16704 16819 16695 16591
# 计算各个值的频率
> prop.table(count_table)
X
1 2 3 4 5 6
0.16619 0.16572 0.16704 0.16819 0.16695 0.16591 都在 0.166 上下浮动,也就是 \approx\frac{1}{6}
据此想法,可以直接用 \chi^2 统计量来表示
\chi^2=\Sigma_{i=1}^r\frac{(n_i-np_i)^2}{np_i}
看分子:
(n_i-np_i)^2 ,对应的就是实验出现的次数 n_i 与根据理论概率值计算出来次数 np_i 的误差,因为有正有负,所以加平方。
看分母:
np_i 就是根据理论概率值计算出来次数
通俗来说就是看总误差占比大不大
当样本容量 n 充分大,H_0 为真时,分子的每一项误差都不会太大,每个分类的误差的占比也不会太大,最后误差的总占比也不会太大, \chi^2 就会近似服从自由度为 r-1 (分类数少一个)的 \chi^2 分布
如果 \chi^2 过大,人们就会认为原假设 H_0 就会不真。 \chi^2 就会落入拒绝域 W=(\chi^2 \geq c)
所以在给定显著水平 \alpha ,由分布 \chi^2(r-1) 可算出 c=\chi_{1-\alpha}^2(r-1)
结论:如果 \chi^2>c=\chi_{1-\alpha}^2(r-1) ,拒绝原假设 H_0
离散变量的关联性分析
具体跟着例子就明白了:
检验:性别和化妆是否有关联
原假设: H_0 :性别与化妆没有关联(性别 与 化妆 相互独立)
第一张表
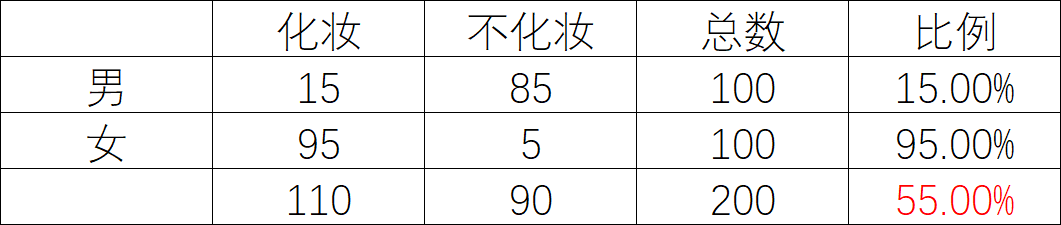

这张表怎么来的?
举例子,一般我们都会读到下面的数据表
> df
Id sex make_up
1 1 male yes
2 2 male yes
3 3 male yes
4 4 male yes
5 5 male yes
6 6 female no
7 7 female no
8 8 female no
9 9 female no
10 10 female no用 xtabs() 函数就能得到列联表,再用 addmargins() 函数就能得到带边际频数的列联表,用 addmargins(prop.table(...)) 函数就能得到带边际频率的列联表
> mytable = xtabs(~ sex+make_up, data = df)
> mytable
make_up
sex no yes
female 5 0
male 0 5
# 带边际频数
> addmargins(mytable)
make_up
sex no yes Sum
female 5 0 5
male 0 5 5
Sum 5 5 10
# 带比例
> addmargins(prop.table(mytable))
make_up
sex no yes Sum
female 0.5 0.0 0.5
male 0.0 0.5 0.5
Sum 0.5 0.5 1.0继续说回上面,
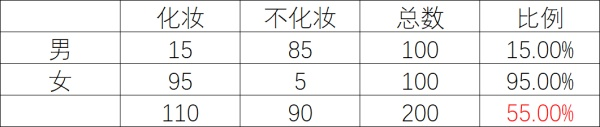

比例就是,化妆人数占性别总人数的比例
红色标红的比例,就是无论男女,化妆人数占总人数的比例为55%(理论值)
第二张表:根据理论值来算出来的对应的理论人数


把实际值和理论值作差取平方
\chi^2=\frac{(15-55)^2}{55}+\frac{(85-45)^2}{45}+\frac{(95-55)^2}{55}+\frac{(5-45)^2}{45}=129.2929293
上代码检验一下我们算得是否正确
> x <- c(15, 95, 85, 5)
> dim(x) <- c(2, 2)
> chisq.test(x, correct = FALSE)
Pearson's Chi-squared test
data: x
X-squared = 129.29, df = 1, p-value < 2.2e-16X-squared = 129.29跟我们算得一样
【注意】如果 \chi^2 的值接近于 0 ,说明两者独立,几乎没有什么关联性
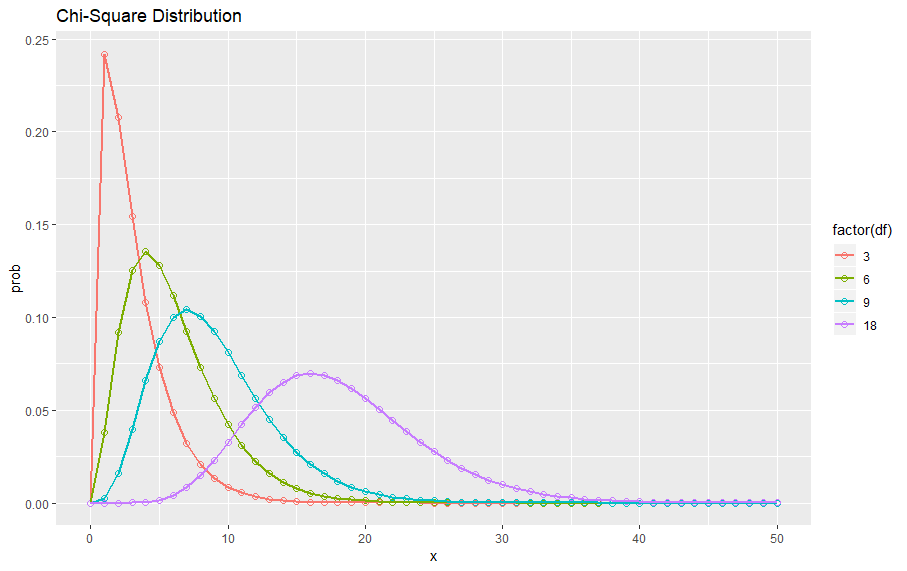
先看看卡方分布分布图
分别是自由度为3、6、9、18的 \chi^2 分布图

而这题是自由度df为 1 , \alpha=0.05 即置信度为 95\% 对应的 \chi^2=3.84
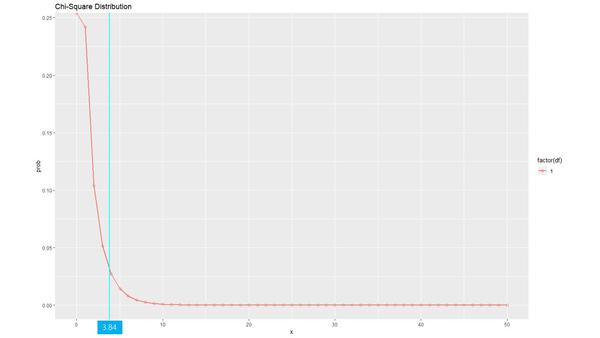

因为
\chi^2=129.2929293>\chi_{95\%}^2(1)=3.84
所以落入拒绝域,拒绝原假设 H_0
数值越大, H_0 的拒绝程度越大,就是化妆与性别无关的概率越低(有点拗口)
数值越小, H_0 的接受程度越大,就是化妆和性别真的可能无关,概率越高
现在 \chi^2 的值比 3.84 大,
p-value < 2.2e-16 即 p-value < 0.05 ,拒绝原假设 H_0
结论:化妆和性别是存在关联的
后话
卡方检验不仅可以检验拟合优度、是否关联,反面就是是否独立,想看卡方检验来检验两个变量独立性的,请看我之前写的一篇文章
