
AI安全—对抗样本生成方法及伪代码

本人目前从事“语音识别”系统攻防的研究。由于深度神经网络的缺陷,语音识别系统将会成为黑客入侵的一个入口。比如,黑客播放威胁语音(通过广播、电视、网络视频等),可以攻击加载有基于DNN的语音识别系统的设备,从而发送信收费短信,下载木马,窃取个人隐私信息等。
下面主要介绍一些“对抗样本”生成方法以及自己总结的伪代码,相关文献总结在伪代码中,有兴趣的自己可以查一查。因为自己刚在做一块,所以存在很多错误,希望大家指正,多交流。(为了偷懒,有些话语完全摘自“综述论文:对抗攻击的12种攻击方法和15种防御方法”,但是今后会再做修改,让对抗样本原理和方法的解释更加通俗易懂。本人非常喜欢做对知识直观、通俗解释的事情^-^)
同其他机器学习算法一样,深度神经网络(DNN)也容易受到对抗样本的攻击,即通过对输入进行不可察觉的细微的扰动,可以使深度神经网络以较高的信任度输出任意想要的分类,这样的输入称为对抗样本(adversarial examples)。利用算法的这一缺陷,深度学习模型会被攻击者利用,以实现攻击者选择的特定输出和行为,构成安全威胁。比如,无人驾驶车可能使用DNN来识别交通标志,如果攻击者伪造的标志“STOP”导致DNN错误分类,汽车则不会停止,容易导致交通事故;网络入侵检测系统使用DNN作为分类器,若伪装成合法请求的恶意请求绕过了入侵检测系统,会使目标网络的安全性受到威胁。
“对抗样本”代表了AI安全领域里的一种具体问题,研究对抗样本的生成原理和算法实现,有助于分析基于深度学习的系统存在的安全漏洞,并建立针对此类攻击的更好的防范机制,进而加速机器学习领域的进步。对抗攻击是深度学习领域近两年的研究热点,其研究热度呈现上升趋势,2017年NIPS会议新增了基于Kaggle平台的“对抗攻击与防御”的竞赛议程。如何高效的生成对抗样本,且让人类感官难以察觉,正是对抗样本生成算法研究领域的热点。
能够形成对抗样本的原因,目前归结为三点:
- 实际模型由有限的训练集学习而来,模型具有未完全的泛化特性;
- 模型组件的线性特性,导致微小的扰动被放大;
- 模型偏移,决策边界倾斜。
一、基于梯度的方法
1. 凸优化算法(含box约束条件)
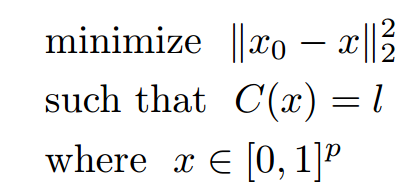
2013年,Szegedy等人首次证明了可以通过对图像添加小量的人类察觉不到的扰动误导神经网络做出误分类。他们首先尝试求解让神经网络做出误分类的最小扰动的方程。但由于问题的复杂度太高,他们转而求解简化后的问题,即寻找最小的损失函数添加项,使得神经网络做出误分类,这就将问题转化成了凸优化过程。
损失函数的选择
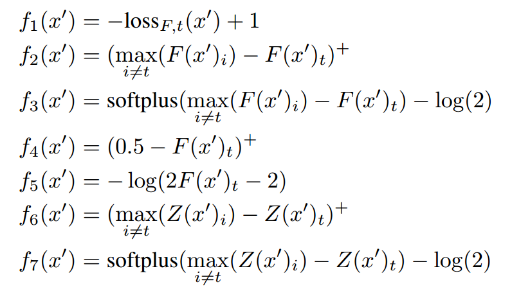

含等式约束优化问题,但是C()是高度非线性和非凸的:


构造合理的损失函数,转化为“凸优化”问题:
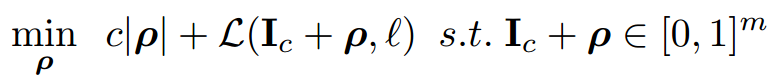



测试的结果(速度较慢,但成率高很高):

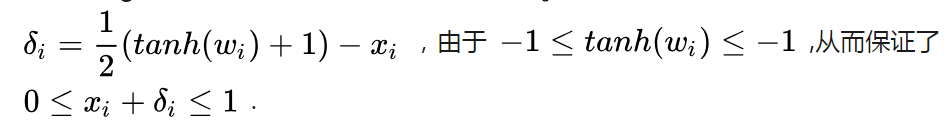


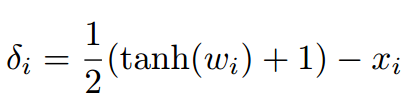
C&W攻击:
2. 快速梯度下降法(FGSM)
该方法得益于损失函数的梯度符号矩阵(sign matrix),在损失函数梯度变化的方向上寻找对抗样本,并用输入变化参数来控制损失函数梯度变化的幅度。输入变化参数越大,构造的对抗样本被错误分类的可能性越大,但人更容易被察觉。
梯度法产生最大化的微小扰动,但极大程度的改变输出;输入纬度越高,输出的影响越大;模型的线性导致这种现象发生。梯度法是最快的方法,但不是产生隐蔽性最高的方法,不保证扰动最小。


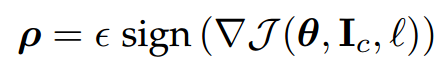



测试的结果(速度快,但成功率低;稀疏性):
FGSM


衍生方法:


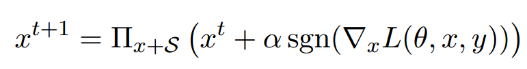

- Projected Gradient Descent Attack


该攻击是对FGSM攻击的改进,确保每一步更新的图像与原图像的距离在ε范围内,可以增加FGSM的攻击成功率。
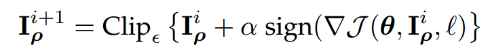

- Basic & Least-Likely-Class Iterative Methods
one-step 方法通过一大步运算增大分类器的损失函数而进行图像扰动,因而可以直接将其扩展为通过多个小步增大损失函数的变体,从而我们得到 Basic Iterative Methods(BIM)。而该方法的变体和前述方法类似,通过用识别概率最小的类别(目标类别)代替对抗扰动中的类别变量,而得到 Least-Likely-Class Iterative Methods。(平衡矛盾:生成速度&攻击成功率)
BIM-L∞


BIM-L1


BIM-L2


- Momentum Iterative Method(优势在于黑盒攻击:解决攻击成功率和迁移性的矛盾)
这是一种通过在迭代过程中在损失函数的梯度方向上积累速度矢量来加速梯度下降算法的技术,在NIPS 2017非定向和定性的对抗样本攻击比赛中均获得了第一名。
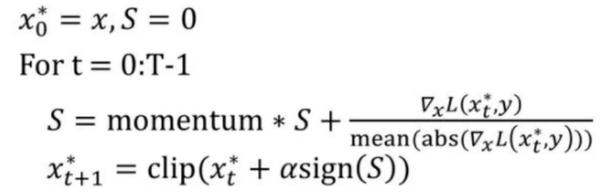



3. DeepFool
使用Deepfool的理想前提是目标DNN完全线性的,即存在可分割不同类别数据的超平面。Deepfool分析得到简化分类问题的最优解,并在此基础上构建对抗样本。然而,由于神经网络实际上不是线性的,只能朝着最优解逐步搜索,并重复该搜索过程。当找到真正的对抗样本是,搜索终止。Deepfool通过迭代计算的方法生成最小规范对抗扰动,将位于分类边界内的图像逐步推到边界外,直到出现错误分类。此方法生成的扰动比 FGSM 更小,同时有相似的欺骗率。
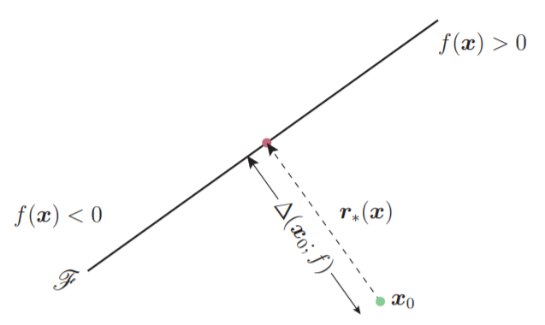

- 二分类最小扰动的解:
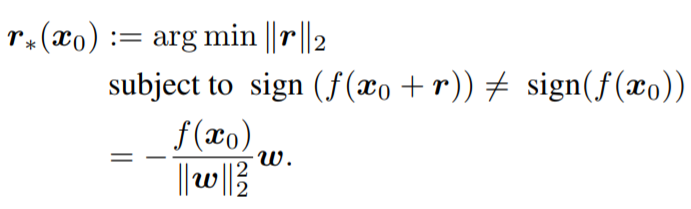

- 二分类非线性问题,用凸函数的“下估计”作为限制条件,逐步优化:
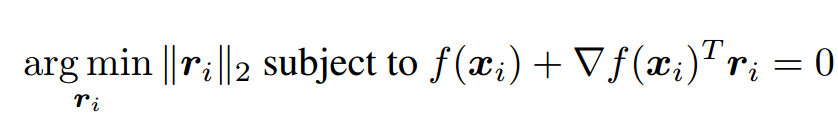

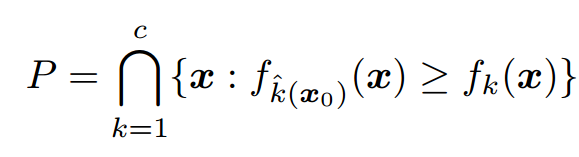

- 多分类问题:

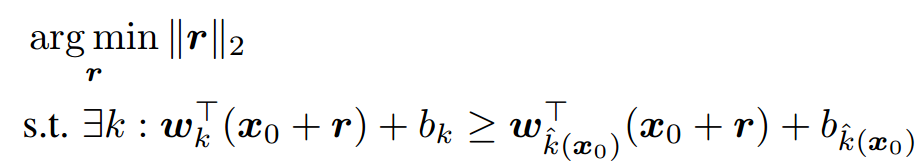

- 多分类非线性问题,用凸函数的“下估计”作为限制条件,逐步优化:
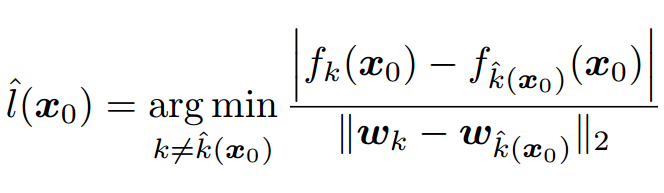





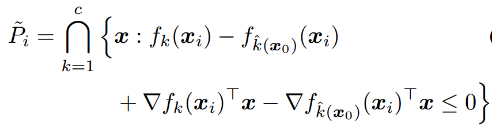




测试结果(优点:与原始图片的差别很小):
L1


L2
L∞
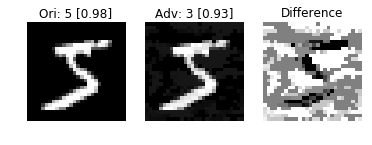



4. Jacobian-based Saliency Map
该方法使用Jacobian矩阵来评估模型对每个输入特征的敏感度,然后用Saliency map选择扰动,通过组合其Jacobian矩阵,将每个输入特征对误分类目标的贡献排序来获取对抗样本。对抗攻击通常使用的方法是限制扰动的 l_∞或 l_2 范数的值以使对抗样本中的扰动无法被人察觉。但 JSM 提出了限制 l_0 范数的方法,即仅改变几个像素的值,而不是扰动整张图像。(Saliency map即特征图,可以告诉我们图像中的像素点对图像分类结果的影响。)


测试结果(优点:局部像素变化):


5. Houdini
Houdini是一种用于欺骗基于梯度的机器学习算法的方法,通过生成特定于任务损失函数的对抗样本实现对抗攻击,即利用网络的可微损失函数的梯度信息生成对抗扰动。除了图像分类网络,该算法还可以用于欺骗语音识别网络。
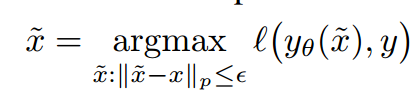
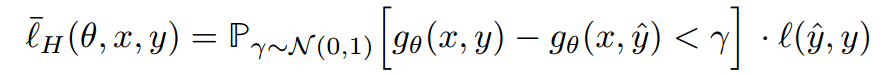

6. Universal Adversarial Perturbations
诸如 FGSM、ILCM、DeepFool等方法只能生成单张图像的对抗扰动,而 Universal Adversarial Perturbations能生成对任何图像实现攻击的扰动,这些扰动同样对人类是几乎不可见的。该论文中使用的方法和 DeepFool 相似,都是用对抗扰动将图像推出分类边界,不过同一个扰动针对的是所有的图像。
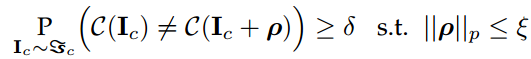

7. UPSET and ANGRI
Sarkar等人提出了两个黑箱攻击算法,UPSET 和 ANGRI。UPSET 可以为特定的目标类别生成对抗扰动,使得该扰动添加到任何图像时都可以将该图像分类成目标类别。相对于 UPSET 的「图像不可知」扰动,ANGRI 生成的是「图像特定」的扰动。它们都在 MNIST 和 CIFAR 数据集上获得了高欺骗率。
8. Adversarial Transformation Networks (ATNs)
Baluja 和Fischer训练了多个前向神经网络来生成对抗样本,可用于攻击一个或多个网络。该算法通过最小化一个联合损失函数来生成对抗样本,该损失函数有两个部分,第一部分使对抗样本和原始图像保持相似,第二部分使对抗样本被错误分类。
二、基于分数(概率或分对数)的方法
1. One Pixel Attack
这是一种极端的对抗攻击方法,仅改变图像中的一个像素值就可以实现对抗攻击。Su等人使用了差分进化算法,对每个像素进行迭代地修改生成子图像,并与母图像对比,根据选择标准保留攻击效果最好的子图像,实现对抗攻击。这种对抗攻击不需要知道网络参数或梯度的任何信息。



2. Local Search Attack(基于贪婪搜索的黑盒攻击)

问题:模型预测softmax分数低的,容易被攻击。高的很难!!
三、基于决策边界的方法(既不需要知道梯度,也不需要概率):
1. 模糊图形

2. 降低对比度

3. 椒盐噪声

4. 随机噪声

5. 沿边界搜索的优化算法(为了保障隐蔽性,生成时间很长)

