
如何优雅的下载huggingface-transformers模型

目录
- 问题描述
- 现有方案
- 自行实现的模型下载方案(历史版本,自以为的优雅中透露着没好好看文档的尴尬)
- Git LFS 模型下载方案(优雅,但不够灵活)
- Hugging Face Hub 模型下载方案(优雅,强烈推荐)
感谢 @ma xy 的提示,作者又进行了一些尝试,已将文章进行更新,下载方案已更新Git LFS 和 Hugging Face Hub的下载方案。
问题描述
作为一名自然语言处理算法人员,hugging face开源的transformers包在日常的使用十分频繁。在使用过程中,每次使用新模型的时候都需要进行下载。如果训练用的服务器有网,那么可以通过调用from_pretrained方法直接下载模型。但是就本人的体验来看,这种方式尽管方便,但还是会有两方面的问题:
- 如果网络很不好,模型下载时间会很久,一个小模型下载几个小时也很常见
- 如果换了训练服务器,又要重新下载。
这里可能大家会疑惑,为什么不能把当前下载好的模型迁移过去,我们可以看下通过from_pretrained保存的文件(一般在~/.cache/huggingface/transformers文件夹下)


这个命名,属实是让人摸不到头脑。
针对上述问题,一种常见的解决方案是预先下载好模型文件,当然这也需要我们有一台网络不错的机器,下面来介绍下这种方案。
现有方案
我们可以再huggingface的官网上,搜索我们想要的模型,直接进行下载,我们以pytorch版本的bert-base-chinese模型为例进行介绍。
首先,打开网站
接下来,在对应位置输入我们想要的模型的名称,就可以看到我们想要的模型了
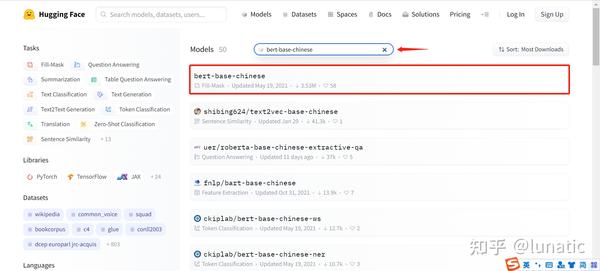
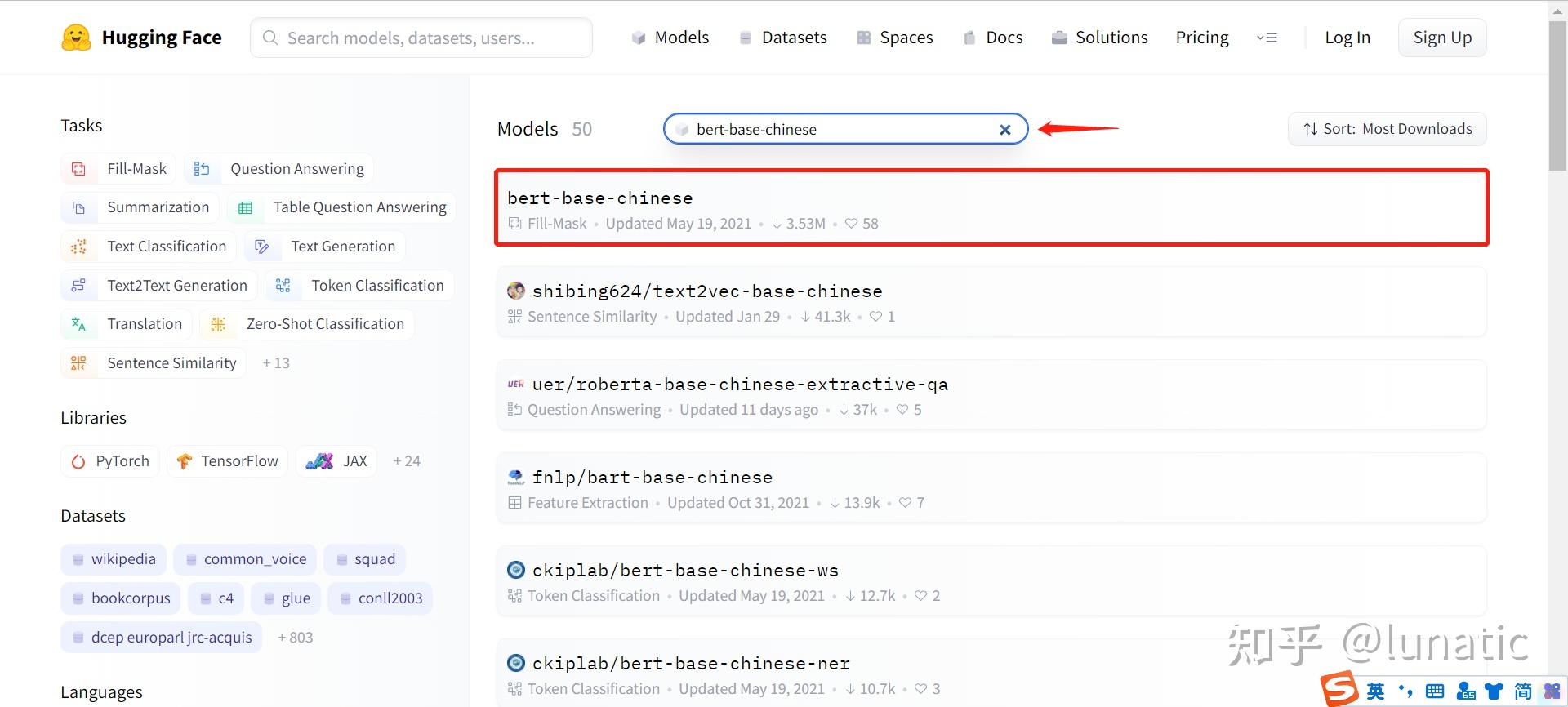
点击对应的模型,进入页面后点击Files and versions,可以看到该模型下面的所有文件
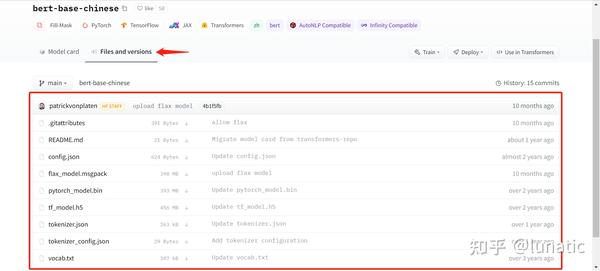

下面,我们只要点击对应文件的下载(↓)就可以了




然而,我们下载的还是这样的一个文件,想要通过from_pretrained方法加载,就还需要把模型文件名改成pytorch_model.bin。
但不管如何,我们可以通过这种方案,下载我们想要的模型了,而且可以备份起来,哪里都能用。
只是,这种方式还是欠缺优雅,我们能不能也像from_pretrained方法那样,只要给模型的名字,就能自动下载成我们想要的样子呢?的确是可以的,下面来介绍几种优雅下载的解决方案。
自行实现的模型下载方案(历史版本,自以为的优雅中透露着没好好看文档的尴尬)
地址分析
(完整代码放在了后面,不想看分析的小伙伴们可以直接看代码)
利用代码进行文件下载,那肯定是要先分析网页元素。
(PS:做算法,这技能肯定要有不是)

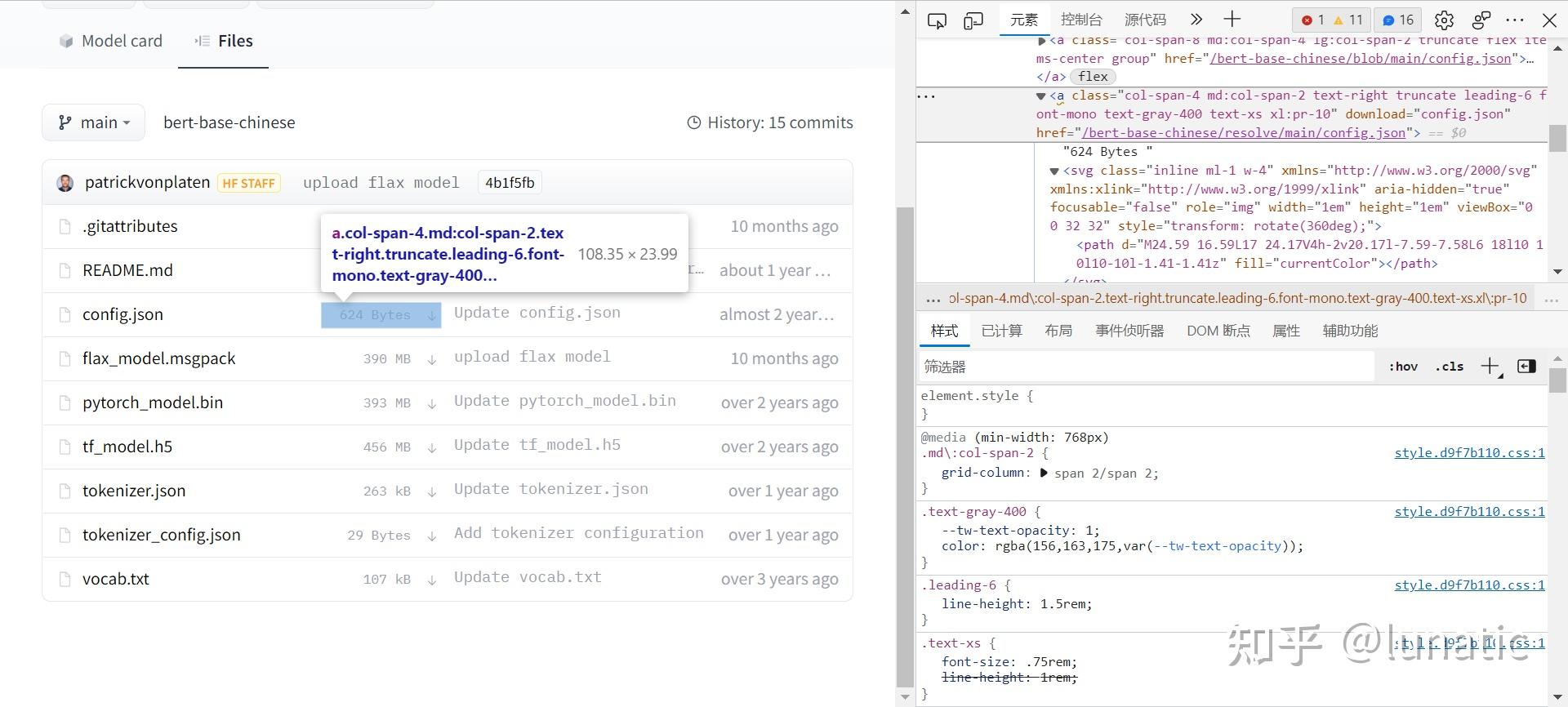
通过简单的元素定位分析,我们得到三个文件的地址分别是
- config.json: https://huggingface.co/bert-base-chinese/resolve/main/config.json
- pytorch_model.bin: https://huggingface.co/bert-base-chinese/resolve/main/pytorch_model.bin
- vocab.txt: https://huggingface.co/bert-base-chinese/resolve/main/vocab.txt
可以明显的看到,整体组成如下,我们可以根据替换模型名称和文件名称达到下载不同模型的效果。
https://huggingface.co/ + 模型名称 + /resolve/main/ + 文件名称
但是,为什么模型文件的名称和地址不一样呢?这个地址真的是下载地址吗?进一步的,查看一下文件真实的下载地址
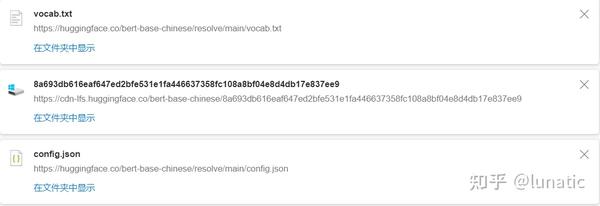
果然,可以看到,config.json和vocab.txt两个文件下载的地址和定位的地址是一样的,而模型文件并不是上述页面中分析的地址。但是直接从这个地址下又不现实,这明显包含着生成的id,我们需要进一步定位到这个id。
那么如何定位到这个ID呢?目前看来,请求肯定是被转发了,那么我们可以这样。
首先,直接向https://huggingface.co/bert-base-chinese/resolve/main/pytorch_model.bin发送请求
r = requests.head(https://huggingface.co/bert-base-chinese/resolve/main/pytorch_model.bin)然后,我们查看请求头中的内容,Location中的内容,正好就是下载地址,直接从这里下载即可。
{..., 'Location': 'https://cdn-lfs.huggingface.co/bert-base-chinese/8a693db616eaf647ed2bfe531e1fa446637358fc108a8bf04e8d4db17e837ee9',}这里为了获得真实下载地址需要多请求一步,在代码中可以很方便的实现。下面给出完整的下载代码。
完整代码
(PS:这里的代码参考了transformers包内的下载代码)
import os
import json
import requests
from uuid import uuid4
from tqdm import tqdm
SESSIONID = uuid4().hex
VOCAB_FILE = "vocab.txt"
CONFIG_FILE = "config.json"
MODEL_FILE = "pytorch_model.bin"
BASE_URL = "https://huggingface.co/{}/resolve/main/{}"
headers = {'user-agent': 'transformers/4.8.2; python/3.8.5; \
session_id/{}; torch/1.9.0; tensorflow/2.5.0; \
file_type/model; framework/pytorch; from_auto_class/False'.format(SESSIONID)}
model_id = "bert-base-chinese"
# 创建模型对应的文件夹
model_dir = model_id.replace("/", "-")
if not os.path.exists(model_dir):
os.mkdir(model_dir)
# vocab 和 config 文件可以直接下载
r = requests.get(BASE_URL.format(model_id, VOCAB_FILE), headers=headers)
r.encoding = "utf-8"
with open(os.path.join(model_dir, VOCAB_FILE), "w", encoding="utf-8") as f:
f.write(r.text)
print("{}词典文件下载完毕!".format(model_id))
r = requests.get(BASE_URL.format(model_id, CONFIG_FILE), headers=headers)
r.encoding = "utf-8"
with open(os.path.join(model_dir, CONFIG_FILE), "w", encoding="utf-8") as f:
json.dump(r.json(), f, indent="\t")
print("{}配置文件下载完毕!".format(model_id))
# 模型文件需要分两步进行
# Step1 获取模型下载的真实地址
r = requests.head(BASE_URL.format(model_id, MODEL_FILE), headers=headers)
r.raise_for_status()
if 300 <= r.status_code <= 399:
url_to_download = r.headers["Location"]
# Step2 请求真实地址下载模型
r = requests.get(url_to_download, stream=True, proxies=None, headers=None)
r.raise_for_status()
# 这里的进度条是可选项,直接使用了transformers包中的代码
content_length = r.headers.get("Content-Length")
total = int(content_length) if content_length is not None else None
progress = tqdm(
unit="B",
unit_scale=True,
total=total,
initial=0,
desc="Downloading Model",
)
with open(os.path.join(model_dir, MODEL_FILE), "wb") as temp_file:
for chunk in r.iter_content(chunk_size=1024):
if chunk: # filter out keep-alive new chunks
progress.update(len(chunk))
temp_file.write(chunk)
progress.close()
print("{}模型文件下载完毕!".format(model_id))执行过程,


最终,我们可以得到如下文件


一顿操作,最终实现了模型按照我们想要的格式进行下载。
事实上,这种方式可能只是我自认为的优雅(^_^;),在官方网站上本身就存在着更好的下载的方案。
感谢评论区 @ma xy 的提示,下面介绍git lfs的方案。
Git LFS 模型下载方案(优雅,但不够灵活)
准备工作
Git LFS的方案相较于前面自行实现的方案要简洁的多得多。我们需要在安装git的基础上,再安装git lfs。以Windows为例,命令如下
git lfs install模型下载
我们还是以bert-base-chinese为例进行下载,打开具体的模型面,可以看到右上角有一个Use in Transformers的button。
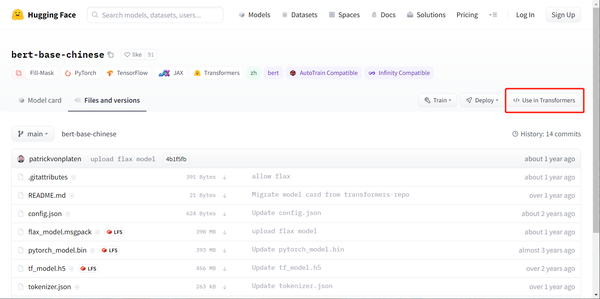
点击该Button,我们就可以看到具体的下载命令了。
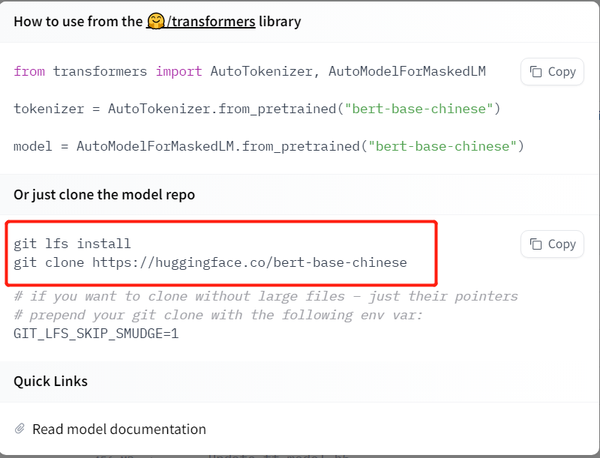

拷贝命令在终端执行,就可以下载了。下载后的格式,和前面自行实现的代码是一样,但是就使用体验上来看,这种方式明显会更加优雅!
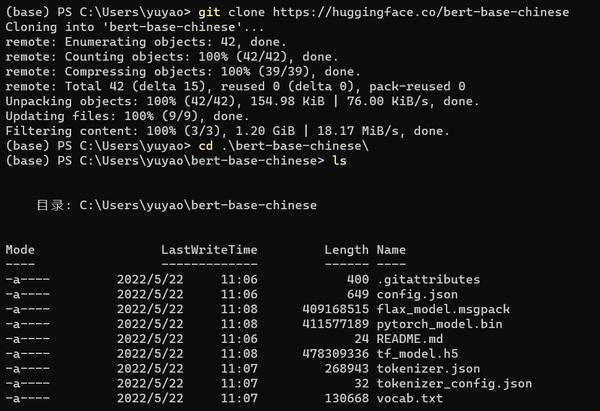

但是,这种方案也存在着一定的问题,即会下载仓库中的所有文件,会大大延长模型下载的时间。我们可以看到在目录中包含着flax_model.msgpack、tf_model.h5和pytorch_model.bin三个不同框架模型文件,在bert-base-uncased的版本中,还存在着rust版本的rust_model.ot模型,如果我们只想要一个版本的模型文件,这种方案就无法实现了。
如果想实现模型精确下载,我们还可以借助Hugging Face Hub,下面来介绍这种方案。
Hugging Face Hub 模型下载方案(优雅,强烈推荐)
准备工作
准备工作同样很简单,我们只需要安装huggingface_hub。
pip install huggingface_hub模型下载
huggingface_hub提供了很多种模型下载的方案,详细的可以到下面的链接中进行查看
这里只介绍下和前面两种对应的下载模式——snapshot_download。
同样的,我们还是下载bert-base-chinese这个模型,代码如下
In [1]: from huggingface_hub import snapshot_download
In [2]: snapshot_download(repo_id="bert-base-chinese")
Downloading: 100%|████████████████████████████████████████████████████████████████████| 391/391 [00:00<00:00, 77.1kB/s]
Downloading: 100%|██████████████████████████████████████████████████████████████████| 21.0/21.0 [00:00<00:00, 4.55kB/s]
Downloading: 100%|█████████████████████████████████████████████████████████████████████| 624/624 [00:00<00:00, 154kB/s]
Downloading: 100%|██████████████████████████████████████████████████████████████████| 409M/409M [00:20<00:00, 20.0MB/s]
Downloading: 100%|██████████████████████████████████████████████████████████████████| 412M/412M [00:25<00:00, 16.0MB/s]
Downloading: 100%|██████████████████████████████████████████████████████████████████| 478M/478M [00:22<00:00, 21.7MB/s]
Downloading: 100%|███████████████████████████████████████████████████████████████████| 269k/269k [00:01<00:00, 238kB/s]
Downloading: 100%|██████████████████████████████████████████████████████████████████| 29.0/29.0 [00:00<00:00, 8.47kB/s]
Downloading: 100%|███████████████████████████████████████████████████████████████████| 110k/110k [00:00<00:00, 160kB/s]
Out[2]: 'C:\\Users\\yuyao/.cache\\huggingface\\hub\\bert-base-chinese.main.4b1f5fb6deac3583018fcf351473024a3d65b2d4'下载完成后,我们可以到对应的目录下查看文件,可以看到,此时的下载与Git LFS下载的内容是一样的。


那么,如何下载指定版本的内容呢?在snaphot_download方法中,提供了allow_regex和ignore_regex两个参数,简单来说前者是对指定的匹配项进行下载,后者是忽略指定的匹配项,下载其余部分。我们只需要使用其中一种就可以了,这里以ignore_regex为例演示下如何只下载Pytorch版本的模型,代码如下。
In [3]: snapshot_download(repo_id="bert-base-chinese", ignore_regex=["*.h5", "*.ot", "*.msgpack"])
Downloading: 100%|█████████████████████████████████████████████████████████████████████| 391/391 [00:00<00:00, 110kB/s]
Downloading: 100%|██████████████████████████████████████████████████████████████████| 21.0/21.0 [00:00<00:00, 5.52kB/s]
Downloading: 100%|█████████████████████████████████████████████████████████████████████| 624/624 [00:00<00:00, 207kB/s]
Downloading: 100%|██████████████████████████████████████████████████████████████████| 412M/412M [00:21<00:00, 19.0MB/s]
Downloading: 100%|██████████████████████████████████████████████████████████████████| 269k/269k [00:04<00:00, 66.4kB/s]
Downloading: 100%|██████████████████████████████████████████████████████████████████| 29.0/29.0 [00:00<00:00, 5.87kB/s]
Downloading: 100%|██████████████████████████████████████████████████████████████████| 110k/110k [00:01<00:00, 71.3kB/s]可以看到,此时下载项相较于前面完整的下载少了几项,我们再打开文件目录查看一下,可以看到此时就没有了TensorFlow和Flax的模型了!
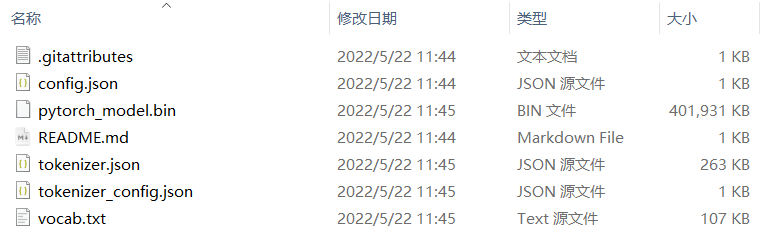

搞定!^_^
希望能给大家帮助!
