
统计量–效应量的相互转换 | 元分析基础


元分析(meta-analysis)是汇总不同研究结果、考察平均效应大小的常用方法。
元分析一般基于效应量(effect size)而非统计量(test statistics)。


然而,很多文献(尤其是一些老文献)只报告了统计量(如t、F、χ²)及其p值,可能并没有报告效应量(如Cohen's d、r、R²、η²),或者报告的效应量在类型上存在差异,无法直接汇总。
本文将为大家梳理总结“如何把文献中的统计量转换为不同类型的效应量”,以方便元分析的实际操作。
效应量的种类
在元分析中,我们一般选择标准化的效应量,而不是非标准化的,因为只有这样,不同研究的效应量才可以比较(Standardized and unstandardized effect sizes - Wikipedia)。
标准化的效应量可以分为三大家族:
- d-family(difference family):如Cohen's d、Hedges' g
- r-family(correlation family):如Pearson r、R²、η²、ω²、f
- OR-family(categorical family):如odds ratio (OR)、risk ratio (RR)
其中,我们可能最熟悉Cohen's d 和Pearson r,而在G*Power软件里面,f 也是一个常用的效应量(注意,并不是大写的F,F 是统计量而非效应量)。
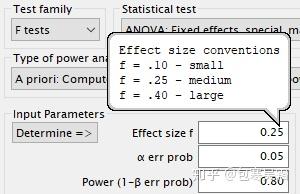
事实上,这三类效应量之间本身就可以相互转换(详见下一节的公式)。下面我们将着重关注d、r、f、OR这几个常用效应量。
把统计量转换为效应量
由于很多文献(尤其是老文献)通常只报告统计量(如t、F、χ²)及其p值,而且并不总能找到均值、标准差等原始的描述统计量,所以在做元分析的时候,我们需要把统计量转换为效应量。
闲话不多说,直接上公式:
r :
r=\sqrt{\eta_p^2}=\sqrt{\frac{f^2}{f^2+1}}=\sqrt{\frac{d^2}{d^2+4}}=\sqrt{\frac{t^2}{t^2+df}}=\sqrt{\frac{F\cdot df_1}{F\cdot df_1+df_2}}=\sqrt{\frac{\chi^2}{N(k-1)}}
(均需要加±,根据实际情况判断正负)
(其中k = 列联表的行数与列数中的最小值;对于最常见的2 × 2列联表,k – 1 = 1)
d :
d=\pm2f=\frac{2r}{\sqrt{1-r^2}}=t\cdot\sqrt{\frac{1}{n_1}+\frac{1}{n_2}}或\frac{2t}{\sqrt{N}}_{(n_1=n_2=\frac{N}{2})}^{(独立样本)}=\frac{t}{\sqrt{N}}^{(配对样本)}=ln(OR)\cdot\frac{\sqrt{3}}{\pi}
f :
f=\sqrt\frac{R^2}{1-R^2}(=\sqrt\frac{r^2}{1-r^2})=\left| \frac{d}{2} \right|
* 注:
1. 与OR相关的转换存在一定的误差,主要在于 \frac{\pi}{\sqrt{3}} 是二分类Logistic回归中因变量标准差的近似估计值。
2. 在回归分析中,如果原始文献报告了非标准化的回归系数b及其标准误SE,则可以通过计算 t=\frac{b}{SE} 来算出效应量r 。
3. 在方差分析中,\eta_{p}^{2}=\frac{SS_{effect}}{SS_{effect}+SS_{error}}=\frac{F\cdot df_{1}}{F\cdot df_{1}+df_{2}}=r^{2} ,也就是说只用F 值及其两个自由度也能直接算出偏η²(partial η²)。
4. “t-to-r”转换是“F-to-r”转换的一个特例,即当 df_{1}=1 时,t^{2}=F 。
5. R语言的psych包拥有相关的转换函数,可直接调用,函数包括——d2r、r2d;t2r、r2t;t2d、d2t;chi2r、r2chi。
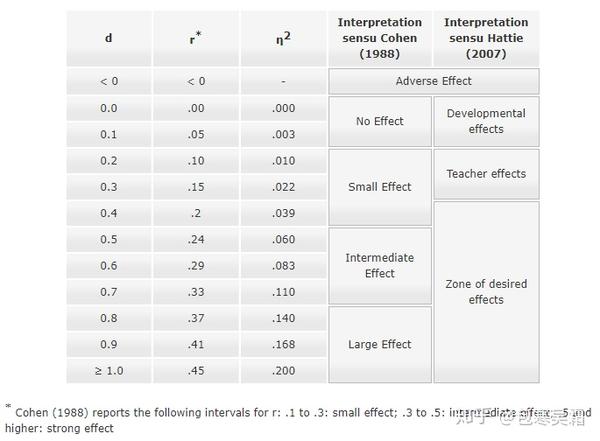
6. 关于不同效应量之间的相互转换,也可以参考一个在线小程序(Computation of different effect sizes like d, f, r and transformation of different effect sizes: Psychometrica)。
7. 关于效应量大小的解释,同样可以参考上面这个链接中的一个表格。

如有错误,欢迎指正!
参考资料:
Introduction to Meta-Analysis (Borenstein, Hedges, Higgins, & Rothstein, 2009)
